









Services on Demand

article
 Portuguese (pdf)
Portuguese (pdf)
 Article in xml format
Article in xml format Article references
Article references
Indicators
Share

 Permalink
PermalinkPesquisas e Práticas Psicossociais
On-line version ISSN 1809-8908
Pesqui. prát. psicossociais vol.15 no.2 São João del-Rei Apr./June 2020
O uso do software Iramuteq na análise de dados de entrevistas
The use of the Iramuteq software in the interview data analysis
El uso del software Iramuteq en el análisis de datos de entrevistas
Yuri Sá Oliveira SousaI; Sonia Maria Guedes GondimII; Iago Andrade CariasIII; Jonatan Santana BatistaIV; Katlyane Colman Machado de MachadoV
IDoutor em Psicologia (UFPE). Professor Adjunto do Instituto de Psicologia (IPS) da Universidade Federal da Bahia (UFBA). E-mail: yurisousas@gmail.com
IIDoutora em Psicologia (UFRJ). Professora Titular do Instituto de Psicologia (IPS) da Universidade Federal da Bahia (UFBA). Pesquisadora do CNPq. E-mail: sggondim@gmail.com
IIIMestrando em Psicologia (Bolsa Fapesb) no Programa de Pós-Graduação em Psicologia da Universidade Federal da Bahia (PPGPSI/UFBA). E-mail: iagocarias@gmail.com
IVDoutorando em Psicologia no Programa de Pós-Graduação em Psicologia da Universidade Federal da Bahia (PPGPSI/UFBA). E-mail: jsb.trevor@hotmail.com
VMestranda em Psicologia (Bolsa Capes) no Programa de Pós-Graduação em Psicologia da Universidade Federal da Bahia (PPGPSI/UFBA). E-mail: katly.colman@gmail.com
RESUMO
O domínio metodológico na análise de dados é importante na formação em pesquisa. O objetivo deste estudo foi analisar os procedimentos de análise de dados oriundos de entrevistas qualitativas com apoio do Iramuteq, software gratuito de análise estatística textual. Foram analisados 38 artigos empíricos publicados entre 2009 e 2018, principalmente nas áreas de Enfermagem e Psicologia. Trinta e três usaram a técnica de Classificação Hierárquica Descendente (CHD), 12 a Análise de Similitude, e somente três a Análise Fatorial por Correspondência (AFC). Dos artigos analisados, 33 apresentaram justificativa de escolha do Iramuteq e 10 adotaram a Teoria das Representações Sociais como referencial teórico. A principal conclusão é a da subutilização dos recursos técnicos do Iramuteq, o que limita a compreensão mais ampla do fenômeno estudado. Apresentam-se sugestões de uso isolado e conjugado dos recursos de análise do Iramuteq para contribuir na formação metodológica de pesquisadores interessados na análise de dados textuais.
Palavras-chave: Análise lexical. Iramuteq. Pesquisa qualitativa. Entrevista.
ABSTRACT
The methodological domain in data analysis is important in research training. The aim of this study was do analyze data analysis procedures from qualitative interviews supported by Iramuteq, a free textual statistical analysis software. We analyzed 38 empirical articles published between 2009 and 2018, mainly in the areas of Nursing and Psychology. Thirty-three used the technique of Descending Hierarchical Classification (DHC), 12 Similitude Analysis, and only three have used Factorial Correspondence Analysis (FAC). Thirty-three of the total presented justification for choosing Iramuteq and 10 adopted the Theory of Social Representations as a framework of theoretical analysis. We conclude that there is an underutilization of the Iramuteq's technical resources, which limits the understanding the phenomenon under study more extensively. Suggestions for single and combined use of the Iramuteq analysis resources are presented to contribute to the methodological training of researchers interested in the analysis of textual data.
Keywords: Lexical analysis. Iramuteq. Qualitative research. Interview.
RESUMEN
El dominio metodológico en el análisis de datos es importante en la capacitación en investigación. El objetivo de este estudio fue analizar los procedimientos de análisis de datos de entrevistas cualitativas respaldadas por Iramuteq, un software de análisis estadístico textual gratuito. Analizamos 38 artículos empíricos publicados entre 2009 a 2018, principalmente en las áreas de Enfermería y Psicología. Treinta y tres utilizaron la Clasificación Jerárquica Descendente (CJD), 12 el análisis de similitud, sólo 3 utilizaron el análisis factorial de correspondencias (AFC). Treinta y tres justificaron la elección del Iramuteq y 10 tuvieron la Teoría de las Representaciones Sociales como referencial teórico. Concluimos que existe una subutilización de los recursos técnicos de Iramuteq, lo que limita la comprensión más amplia del fenómeno estudiado. Se presentan sugerencias de uso aislado y combinado de los recursos del Iramuteq para contribuir a la formación metodológica de investigadores interesados en el análisis de datos textuales.
Palabras clave: Análisis léxico. Iramuteq. Investigación cualitativa. Entrevista.
Introdução
A análise de dados apresenta-se como um desafio para as pesquisas qualitativas em diversos campos do conhecimento. Conforme assinala Gibbs (2009), o manejo de grandes volumes de dados, oriundos de notas de campo, documentos, grupos focais, observação participante e entrevistas exige a adoção de procedimentos metodológicos rigorosos que envolvem a coleta, a armazenagem, o tratamento e a recuperação da informação (Huberman & Miles, 1994). A sistematização desses procedimentos favorece a produção de conhecimento válido em pesquisas qualitativas, o que estimula constantemente reflexões de natureza teórico-metodológica.
O desenvolvimento de manuais especializados em pesquisa qualitativa (Denzin & Lincoln, 1994, que já está em sua 5a edição) também foi acompanhado pela criação de softwares que auxiliam a organização, estruturação e os processos inferenciais. O suporte de programas computacionais amplia a capacidade do pesquisador de lidar com grandes volumes de dados, difíceis de serem tratados manualmente, exigindo apenas domínio sobre os recursos disponíveis para aperfeiçoar as análises e sustentar o processo interpretativo (Cúrcio, 2006). Diferentes softwares oferecem recursos distintos para análises de dados qualitativos, sendo que alguns deles fazem uso de procedimentos de codificação, agrupamento por busca de palavras e expressões verbais, além de contar com o recurso da quantificação para estruturar os dados e gerar outputs sob a forma de indicadores estatísticos, figuras, tabelas e gráficos. Apesar da difusão desses softwares de análise qualitativa nas últimas décadas, chama atenção a subutilização de seus recursos pelos pesquisadores. O que se observa, muitas vezes, é a simples menção ao uso de um software sem que sejam descritos os tipos de análise realizadas ou o referencial teórico de base para a interpretação, o que enfraquece a validade dos resultados.
Ao levar em conta esse cenário, o presente artigo visa contribuir para a formação metodológica de pesquisadores interessados em análise de dados de entrevista com o auxílio do software Iramuteq. Para tanto, realizou-se uma revisão de estudos empíricos com o objetivo de caracterizar os procedimentos teórico-metodológicos adotados em análise de dados de entrevistas, com o apoio do Iramuteq. A principal justificativa pela escolha desse software se deve ao fato de ele oferecer um amplo número de ferramentas para a análise de dados qualitativos com base na estatística textual, ou lexicometria (Camargo, 2005; Sousa, Rodrigues, Rocha, & Martins, 2009).
Além das suas potencialidades funcionais, o Iramuteq é um programa computacional gratuito, mas pouco difundido entre pesquisadores brasileiros (Santos et al., 2017). A proposição de um estudo de revisão com esse escopo oferece um panorama da utilização da ferramenta na análise de dados de entrevistas e, adicionalmente, a partir da identificação de lacunas na literatura, permite apontar formas de utilização do software heuristicamente úteis.
A opção pela análise das entrevistas encontra respaldo no fato de ser esta uma das técnicas mais utilizadas em pesquisas qualitativas nas áreas da Saúde, Educação e Ciências Sociais (Alves & Silva, 1992; Poupart, 2008; Silverman, 2009). O pesquisador decide pelo uso da entrevista quando almeja obter dados que, em geral, não são facilmente acessados por outras técnicas de coleta de dados, como documentos, imagens e questionários fechados (Brito Júnior & Feres Júnior, 2011). A entrevista também é uma via de acesso ao mundo subjetivo do participante, seus conceitos, crenças, percepções, experiências e processos manifestados pela linguagem verbal e gestual (Sampieri, Fernández-Colado, & Lucio, 2006; Silverman, 2009). Possibilita também conhecer os dilemas enfrentados pelos sujeitos na sua vida cotidiana, o que os compele a assumir um papel ativo na construção de sentido do mundo social (Poupart, 2008; Warren, 2001).
As entrevistas são caracterizadas como interações verbais centradas em processos intersubjetivos, que decorrem da relação entre entrevistador e entrevistado, com o objetivo de aprofundar as possíveis respostas às questões de pesquisa (Fraser & Gondim, 2004; Scribano, 2008) - daí a importância de se estabelecer uma interação social que permita a livre manifestação de sentimentos, afetos e opiniões por parte dos entrevistados - e podem ser divididas em estruturadas, semiestruturadas e abertas (Silverman, 2009). Nas entrevistas estruturadas, o pesquisador constrói um roteiro fixo de perguntas para orientar a fala do entrevistado, e também conduzir o processo de codificação e categorização de respostas. As entrevistas abertas ou não diretivas, ao contrário, são orientadas por um tema geral a ser aprofundado conforme a natureza da interação entrevistado-entrevistador (Sampieri et al., 2006). A semiestruturada, por sua vez, adota um roteiro flexível, mas difere das entrevistas abertas por estarem apoiadas em um roteiro de tópicos, temas ou perguntas específicas a partir das quais são feitos questionamentos adicionais à medida que a entrevista avança na elucidação de informações relevantes ao objeto de estudo (Belei, Gimeniz-Paschoal, Nascimento, & Matsumoto, 2008).
Ainda que a entrevista seja considerada uma técnica de coleta de dados que favorece o acesso e a compreensão da subjetividade imbricada nos processos de percepção do mundo social, os discursos enunciados pelos sujeitos nem sempre são facilmente interpretáveis (Poupart, 2008). Muitos críticos ressaltam a ausência de critérios e parâmetros científicos para subsidiar os procedimentos de análise de dados textuais, incluindo os oriundos de entrevistas. O surgimento e a difusão de softwares de análise de dados apresentam-se como uma tentativa de lidar com tais críticas, visto que facilitam a organização e ordenação da informação para fins interpretativos (Alves & Silva, 1992; Santos et al., 2017). Alguns desses softwares baseiam-se na lexicometria para tratamento automático do texto, a partir de cálculos estatísticos sobre o vocabulário do corpus analisado, por exemplo,Alceste, Lexico, Iramuteq (Dany, 2016). Nesse contexto, a lexicometria pode ser definida como um conjunto de técnicas de tratamento estatístico de dados textuais que permite analisar as características estruturais e de conteúdo de um texto ou conjunto de textos com base no vocabulário utilizado (Salem, 1986). Essa abordagem metodológica é notadamente utilizada para identificar tendências, regularidades e estilos discursivos subjacentes a padrões de associação entre palavras, expressões e conceitos (sinonímias, antinomias), reduzindo o material e dando sentido ao aglomerado de dados (Leblanc, 2015). As análises lexicométricas têm sido combinadas com o uso de técnicas de análise de conteúdo e as diversas modalidades de análise de discurso (Bardin, 1977; Leblanc, 2015; Marchand, 2013; Oliveira, Teixeira, Fischer, & Amaral, 2003; Pélissier, 2017; Reinert, 1983, 2002, 2001; Salem, 1986).
No campo das ciências humanas e sociais, a utilização de métodos estatísticos para a análise de dados textuais se iniciou nos anos 1970, na França (Marchand, 2013). Na década de 1980, Max Reinert (1986) desenvolveu o software Alceste (Analyse des Lexèmes Cooccurrents dans les Enoncés Simplifiés d'un Texte), possibilitando inovações metodológicas que reverberaram na criação de outros programas informatizados para gerenciamento de dados, como é o caso do Iramuteq. Desenvolvido por Pierre Ratinaud (2014), o Iramuteq (Interface de R pour les Analyses Multidimensionnelles de Textes ET de Questionnaires) é um software gratuito, que funciona como uma interface de R (www.r-project.org), indicado para o gerenciamento e tratamento estatístico de textos de entrevistas e questionários abertos (Camargo & Justo, 2013; Loubère & Ratinaud, 2014; Ratinaud, 2014). O software começou a ser utilizado no Brasil em 2013 (Camargo & Justo, 2013) e, desde então, a ferramenta se apresenta como possibilidade para o tratamento e a análise estatística de dados textuais dos mais variados tipos, tais como: transcrições de entrevistas e grupos focais, respostas a questionários de evocação livre de palavras, documentos legais e midiáticos. Apesar dessa abertura, o uso do Iramuteq no país tem privilegiado a entrevista como técnica de produção dos dados analisados. Em um estudo de revisão sobre o uso desse software em teses e dissertações no campo da saúde (Santos et al., 2017), constatou-se que apenas uma das 54 pesquisas identificadas não analisou dados provenientes de entrevistas, resultado que parece indicar a prevalência dessa técnica de coleta em estudos dessa natureza.
A utilização do Iramuteq na análise de dados de entrevistas pode ocorrer de diferentes maneiras. Isso porque o software reúne um conjunto variado de procedimentos lexicométricos, tais como: estatísticas textuais clássicas, Análise de Especificidades, Classificação Hierárquica Descendente (CHD), Análise Fatorial por Correspondência (AFC), análise de similitude, análise prototípica de evocações e nuvem de palavras (Camargo & Justo, 2013, 2017; Loubère & Ratinaud, 2014; Pélissier, 2017; Ratinaud, 2014). Com exceção da análise prototípica, todos os procedimentos citados podem ser aplicados a dados de entrevistas, razão pela qual as suas características serão brevemente apresentadas a seguir.
As estatísticas textuais clássicas decompõem os textos em segmentos (enunciados), ocorrências (palavras) e formas linguísticas reduzidas pelo processo de lematização (Cf. Salem, 1986). Essa etapa permite construir o dicionário de formas ativas (verbos, substantivos e adjetivos) e suplementares (pronomes, preposições e verbos auxiliares) que é utilizado em outros procedimentos. Os seus resultados permitem explorar as características do vocabulário utilizado (frequência de formas reduzidas e tipos gramaticais, número total e por texto de ocorrências, hápax, etc.).
A Análise de Especificidades, também conhecida como análise de contrastes, permite comparar a distribuição de formas linguísticas em diferentes partições de um texto, definidas pelo pesquisador por meio da inserção de variáveis categóricas (Leblanc, 2015). Por exemplo, "é possível comparar a produção textual de homens e mulheres em relação a determinado tema" (Camargo & Justo, 2013, p. 515). Quando se considera uma variável com, pelo menos, três modalidades, também é possível realizar uma Análise Fatorial por Correspondência (AFC). Essa última parte do princípio de que as relações entre as partições de um texto e as formas linguísticas utilizadas podem ser reduzidas a poucos fatores (Cf. Marchand, 2013). O método da AFC busca representar graficamente essas relações em um plano fatorial de duas dimensões, cujos resultados são úteis para identificar oposições que estruturam o conteúdo analisado (Leblanc, 2015; Pélissier, 2017).
A Classificação Hierárquica Descendente (CHD), também denominada método Reinert, em referência ao desenvolvedor do software Alceste (cf. Reinert, 1986), é o procedimento mais conhecido e utilizado no Iramuteq (Santos et al., 2017). A CHD realiza uma análise de agrupamentos (clusters) sobre os segmentos de texto de um corpus, de modo que o material é sucessivamente particionado em função da coocorrência de formas lexicais nos enunciados. Dito de outro modo, esse procedimento permite obter uma classificação estável em que os segmentos de texto são distribuídos em classes lexicais homogêneas segundo o vocabulário utilizado (Nascimento & Menandro, 2006; Oliveira et al., 2003). Em seguida, o Iramuteq realiza testes de qui-quadrado (χ2), visando verificar o grau de associação entre as formas linguísticas do corpus e as classes lexicais, o que permite produzir um dendrograma que representa graficamente os diferentes conjuntos lexicais e suas palavras mais características. A interpretação sobre os resultados da CHD se sustenta na hipótese de que o uso de formas lexicais similares vincula-se a representações ou conceitos comuns (Reinert, 1987). Por essa razão, o método Reinert é frequentemente utilizado com o objetivo de identificar temáticas subjacentes a um conjunto de textos. Os resultados obtidos com o método Reinert (CHD) também podem ser representados em um plano fatorial construído pelo método da Análise Fatorial por Correspondência (AFC). Especificamente, quando utilizada no método Reinert, a AFC relaciona formas linguísticas e variáveis de contexto com as classes resultantes da CHD (Nascimento & Menandro, 2006).
A análise de similitude, a seu turno, ancora-se na teoria dos grafos e é realizada com base na coocorrência de palavras em segmentos de texto. Os resultados são graficamente representados, tornando possível visualizar as relações entre as formas linguísticas de um corpus, o que evidencia a maneira como o conteúdo discursivo de um tópico de interesse se estrutura (Camargo & Justo, 2013, 2017; Marchand & Ratinaud, 2012). O Iramuteq também permite combinar, em uma mesma representação, os resultados da Análise de Similitude com uma Análise de Especificidades, realizada a partir de uma variável categórica. Nesse caso, o grafo destaca palavras particularmente associadas às diferentes modalidades da variável (homens e mulheres, conforme exemplo citado anteriormente).
O último recurso mencionado, a nuvem de palavras, produz uma representação gráfica das ocorrências do corpus, em que cada palavra tem um tamanho proporcional a sua frequência. A figura gerada não acompanha indicadores descritivos, mas pode facilitar uma rápida identificação dos termos que são preponderantes no conjunto de textos analisados.
Deve-se enfatizar que a escolha pela utilização de uma ou outra técnica de análise depende das características do problema e dos objetivos da pesquisa (Leblanc, 2015). Nessa direção, o referencial teórico-metodológico do pesquisador, acrescido do suporte de softwares de análise lexicométrica, podem conferir maior confiabilidade às inferências realizadas em pesquisas qualitativas (Justo & Camargo, 2014; Santos et al., 2017). Diante disso, o estudo aqui apresentado descreve e discute as características da utilização do Iramuteq na análise de dados de entrevistas em artigos empíricos publicados entre 2009 e 2018.
Método
Material e procedimentos de coleta
Foi realizada uma revisão sobre artigos empíricos, publicados em periódicos nacionais e internacionais, que utilizaram o Iramuteq na análise de dados de entrevistas, nas principais bases de dados da plataforma de periódicos da Coordenação de Aperfeiçoamento de Pessoal de Nível Superior - Capes (PsychoInfo, WebScience, Scopus, SciELO, Lilacs, Medline e Pubmed). O período temporal de revisão foi de 2009 a 2018. A data inicial corresponde ao ano de lançamento do software e a coleta foi finalizada em junho de 2018.
A busca foi feita com o descritor "Iramuteq" constando no título, no resumo ou nas palavras-chave. Inicialmente, foram identificados 149 artigos, publicados em periódicos nacionais e internacionais, que mencionavam a utilização do software Iramuteq. Depois da exclusão de referências duplicadas, restaram 38 artigos empíricos que utilizaram o Iramuteq para analisar dados de entrevistas, publicados em diferentes idiomas (português, inglês, francês, espanhol e italiano).
Procedimentos de análise de dados
Os artigos foram analisados por dois pesquisadores independentes, seguindo um sistema de codificação previamente elaborado: (i) data da publicação do artigo; (ii) periódico de publicação; (iii) foco do estudo, inferido a partir dos objetivos apresentados pelos autores, destacando os construtos investigados e suas relações com o campo temático; (iv) perfil dos participantes, com ênfase sobre as características que se relacionam com o objeto investigado; (v) número de entrevistados; (vi) recursos ou técnicas de análise do Iramuteq usadas no estudo; (vii) percentual classificado dos dados, caso tenha usado CHD, ou seja, percentagem de aproveitamento dos segmentos de texto; (viii) variáveis categóricas usadas na análise, como sexo, escolaridade, profissão, etc.; (ix) argumentos e fundamentos para a escolha do método ou, especificamente, o tipo de justificativa apresentada para utilizar o Iramuteq na pesquisa; e (x) presença de fundamentação teórica para sustentar a interpretação nas análises. As divergências nos procedimentos de alocação dos artigos nas categorias foram dirimidas por um terceiro pesquisador.
Resultados
A apresentação dos resultados está dividida em duas partes. A primeira se dedica a uma descrição geral dos artigos empíricos e as técnicas de análise utilizadas. A segunda apresenta a Tabela 1 com a categorização dos artigos em relação aos objetivos do estudo e as características dos participantes.
Dos 38 artigos analisados, dois foram publicados em 2014, nove em 2015, 15 em 2016 e 12 em 2017. No que tange aos periódicos, 12 são específicos da área da Psicologia e 12 da área da Enfermagem. Em menor número, encontram-se artigos publicados em periódicos de áreas gerais, como a da Saúde (n=8), e interdisciplinares (n=4). Dos dois artigos restantes, um foi publicado na área da Comunicação e outro da Sociologia. O número de participantes entrevistados variou entre 5 e 584 (Md=25; =50,6; σ=98,9). Apenas quatro artigos incluíram menos de 10 entrevistas em suas análises e sete consideraram mais de 40. Os outros 27 trabalharam com um número médio de 23 participantes (min.=11; máx.=36; σ=7,39).
No que concerne às estratégias de análise realizadas com auxílio do Iramuteq, dos 38 artigos, 33 utilizaram o Método Reinert (CHD); 12 realizaram Análises de Similitude; cinco apresentaram nuvens de palavras como método de tratamento; três discutiram os resultados da CHD com base na Análise Fatorial por Correspondência (AFC), e nenhum deles fez uso da Análise de Especificidades; 13 artigos empregaram mais de um recurso do Iramuteq.
Nos 18 artigos que apresentaram a porcentagem do material distribuída nas classes lexicais, o número de segmentos de texto retidos ao final da CHD oscilou entre 71% e 94% do total do corpus (=82,47%; σ=8,18%). Quanto à possibilidade de incluir variáveis categóricas na CHD, constatou-se que 17 artigos adotaram a estratégia. Para tanto, essas produções consideraram a relação entre o conteúdo das classes e as características dos participantes, tais como: sexo, faixa etária, faixa de renda e/ou de escolaridade, e também outras categorias definidas com fins comparativos.
Dos artigos analisados, 33 apresentaram alguma justificativa sobre a escolha do software, embora apenas 16 tenham incluído argumentos sobre a opção pela técnica de análise adotada (CHD, AFC, Análise de Similitude, etc.). No geral, as justificativas enfatizavam a descrição das características do Iramuteq, destacando ser um programa de código aberto que funciona com o apoio do software estatístico R para realização de análises lexicométricas.
Dos 38 artigos analisados, 14 utilizaram algum referencial teórico para discutir os resultados. Desses, a teoria das representações sociais foi a mais citada (n=10). Entretanto, sete artigos não apresentaram fundamentação teórica e se limitaram a descrever e interpretar os resultados. Os 17 artigos restantes não utilizaram referencial teórico explícito, mas compararam os resultados obtidos com aqueles de outros estudos empíricos.
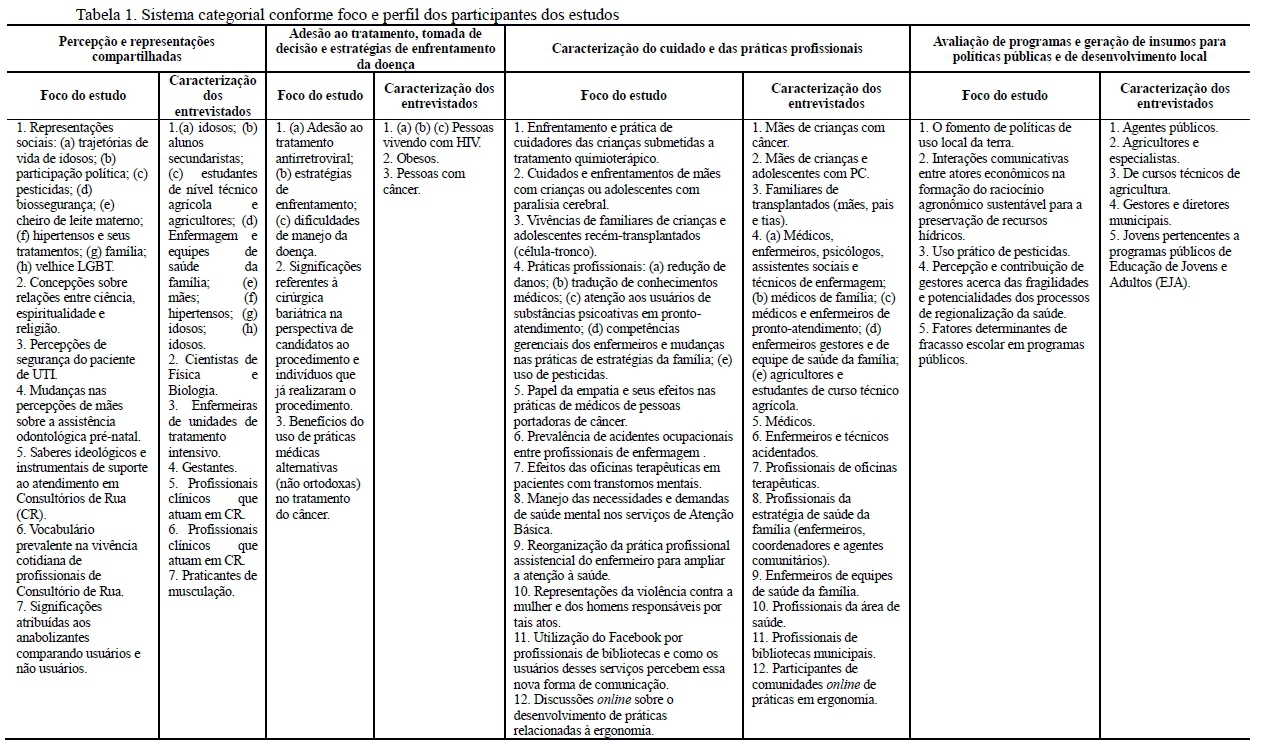
Os objetivos dos 38 estudos analisados foram organizados em quatro categorias (ver Tabela 1). A primeira reuniu os estudos empíricos que se dedicaram a caracterizar percepções, concepções e representações compartilhadas acerca de um tema específico (Camargo, Bousfield, Giacomozzi, & Koelzer, 2014; Fernandes, Montiel, Andrade, Bartholomeu, Cecato, & Martinelli, 2015). Em alguns desses estudos, os autores deixavam evidente a opção pela perspectiva teórico-metodológica das representações sociais e abrangeram tópicos variados, ao passo que outros estudos se valeram dos conceitos de significações, concepções, percepções, vocabulários e saberes ideológicos. A segunda categoria agrupou estudos direcionados a investigar o engajamento em tratamentos de saúde, as tomadas de decisão em função do tratamento e as estratégias adotadas por pacientes para enfrentar doenças (Ibiapina, Monteiro, Alencar, Fernandes & Costa Filho, 2017; Jesus, Oliveira, Caliari, Queiroz, Gir, & Reis, 2017). A terceira, por sua vez, reuniu estudos que caracterizaram modelos de tratamento e intervenção terapêutica, e as vivências por parte de familiares de crianças e adolescentes acometidos por diversas doenças (Nascimento & Faro, 2015; Almico & Faro, 2014). Considerando que se trata de uma categoria de atuação/intervenção, incluíram-se também os estudos com foco na caracterização das práticas profissionais. Por último, a quarta categoria agrupou os estudos com foco na avaliação de programas e geração de insumos para políticas públicas e desenvolvimento local (Chevry Pebayle & Slouma, 2016; Negreiros, Silva, Souza, & Santos, 2017).
Discussão
Os resultados serão discutidos a partir das principais tendências identificadas. Em primeiro lugar, é possível observar que o Iramuteq tem sido utilizado na análise de dados de entrevistas em pesquisas de diferentes áreas. A despeito disso, assinala-se a predominância de estudos publicados em periódicos da Psicologia, Enfermagem e outras áreas que têm relações com o campo da saúde. Esse resultado corrobora as observações de Santos et al. (2017), quando afirmam que, desde o lançamento do Iramuteq, essa ferramenta tem sido largamente utilizada em estudos qualitativos do campo da saúde.
Importa mencionar que a Teoria das Representações Sociais - TRS (Jodelet, 2005; Moscovici, 2009, 2012) foi claramente apontada como abordagem teórica em 26% dos artigos analisados (n=10) (Camargo, Bousfield, Giacomozzi, & Koelzer, 2014; Fernandes et al., 2015; Leite et al., 2016; Salgado et al., 2017; Silva & Bousfield, 2016; Sousa et al., 2016; Zouhri, Garros-Levasseur, Weiss & Valette, 2016). Esse resultado encontra respaldo no fato de os estudos sobre representações sociais já fazerem uso de métodos lexicométricos em seus protocolos de pesquisa há algum tempo (cf. Kalampalikis, 2003). Além disso, ainda que a TRS constitua um arcabouço teórico a partir do qual diferentes objetos podem ser investigados, temas ligados ao campo da saúde predominam na literatura, especialmente na América do Sul (Wachelke, Matos, Ferreira & Costa, 2015). Conforme argumentam Silva, Camargo e Padilha (2011), a TRS passou a ser amplamente adotada nos estudos da área da Saúde como uma forma de compreender e analisar o conhecimento leigo de diferentes grupos sociais acerca dos objetos relacionados a processos de saúde-doença. Por sua vez, os resultados da revisão parecem confirmar a existência de tais tendências temáticas e teóricas também na utilização do Iramuteq em pesquisas que analisaram dados de entrevistas.
No tocante aos recursos de tratamento lexicométrico viabilizados pelo software, observou-se que o Iramuteq tem sido majoritariamente utilizado para realizar análises baseadas no Método Reinert (CHD). A segunda técnica de tratamento mais utilizada foi a Análise de Similitude, tendo sido aplicada em aproximadamente um terço dos artigos (n=12). Outros procedimentos foram parcamente utilizados ou não foram contemplados nos estudos. Chama atenção, por exemplo, o fato de apenas três trabalhos terem apresentado resultados apoiados no método da AFC, assim como a constatação de que nenhum deles fez uso da Análise de Especificidades. Essas lacunas não indicam apenas escolhas técnicas relacionadas aos procedimentos, mas permitem, sobretudo, destacar tendências teórico-metodológicas que repercutem no próprio alcance da pesquisa, uma vez que diferentes opções de tratamento propiciam o acesso a dimensões distintas do fenômeno investigado.
Nessa direção, é possível distinguir a CHD da AFC em função do tipo de análise que se pretende realizar. Com base em perfis lexicais típicos do corpus, o primeiro método permite colocar em evidência o que há de comum nas respostas dos participantes, enquanto o segundo destaca oposições e diferenças nas tomadas de posição discursivas, representadas por relações de aproximação e distanciamento que são observadas em um espaço de duas dimensões, em um plano fatorial (Aubert-Lotarski & Capdevielle-Mougnibas, 2002). Por sua vez, a Análise de Especificidades poderia contribuir para destacar possíveis diferenças no uso do vocabulário de acordo com as características dos participantes, o que permitiria identificar tendências na distribuição de formas linguísticas significativas ao contexto da pesquisa (Cf. Lebart & Salem, 1994). Assim, os resultados apresentados parecem indicar duas tendências complementares: a preferência por parte dos pesquisadores em adotar procedimentos baseados na CHD e a subutilização do software em relação à diversidade de seus recursos. Para compreender essas tendências, algumas hipóteses foram desenvolvidas.
Em primeiro lugar, é possível que parte da procura pelo Iramuteq seja explicada pelo fato de que ele representa uma alternativa gratuita ao software Alceste, comercializado pela Société IMAGE e cuja utilização no Brasil já é bem consolidada, especialmente no campo das pesquisas sobre representações sociais (Azevedo, Costa & Miranda, 2013; Azevedo & Miranda, 2012; Camargo, 2005; Oliveira et al., 2003). Uma vez que o método da CHD constitui o principal fundamento operacional do Alceste, muitos pesquisadores que já tinham alguma experiência com esse software podem ter buscado o Iramuteq especificamente para esse tipo de análise. Além disso, a ênfase sobre a CHD também pode ser explicada pelas suas potencialidades inerentes. Em outras palavras, a escolha pelo procedimento pode derivar da sua capacidade de fornecer uma organização tipológica do material em classes lexicais. A seu turno, as classes são tomadas como categorias analíticas endógenas, a partir das quais os processos inferenciais são desenvolvidos (Landivar, Mathonnat & Tichit, 2015). Deve-se ressaltar que, embora o Iramuteq utilize o mesmo algoritmo do Alceste para a CHD e a AFC, ele não oferece a possibilidade de realizar uma Classificação Hierárquica Ascendente (CHA), tal como encontrado no Alceste. Tanto a CHD quanto a CHA são métodos que permitem representar as relações entre os elementos de um corpus a partir de conjuntos lexicais ou classes (Lebart & Salem, 1994). Contudo, enquanto a CHA identifica agrupamentos com base na proximidade entre os elementos do corpus e produz tantas classes quanto forem solicitadas pelo pesquisador, a CHD funciona de maneira inversa, realizando divisões sucessivas no material até que se obtenha um número de classes lexicais suficientemente estáveis (Landivar et al., 2015). Uma vez que o Iramuteq não contempla o método da CHA, recomenda-se a utilização de outros softwares (Alceste e Rtemis) caso a pesquisa necessite desse recurso.
Sobre o argumento da subutilização da ferramenta, constatação decorrente da escassa representatividade de análises baseadas na AFC e Especificidades, é possível alegar que os pesquisadores dispõem de pouca informação sobre as potencialidades do uso de outros métodos, além da CHD. Não se pretende, com isso, sugerir qualquer obrigatoriedade na utilização conjugada de métodos lexicométricos distintos, uma vez que o desenho metodológico de toda pesquisa deve ser planejado em termos de pertinência e alcance em relação ao problema de pesquisa (Furlan, 2017). É importante enfatizar também a complementaridade entre os resultados produzidos por diferentes procedimentos lexicométricos, o que viria a beneficiar o desenvolvimento de estudos qualitativos com os mais variados focos, a exemplo daqueles que foram descritos na Tabela 1.
Embora a CHD e a AFC possam fornecer informações distintas sobre um mesmo corpus (cf. Aubert-Lotarski & Capdevielle-Mougnibas, 2002; Nascimento & Menandro, 2006), a Análise de Especificidades pode também contribuir na exploração de dados de entrevista quando há variáveis categóricas pertinentes à pesquisa. Com efeito, em um dos estudos realizados por Justo (2016), a autora fez uso da Análise das Especificidades para analisar entrevistas semidirigidas sobre corpo e obesidade, comparando o discurso de participantes com e sem sobrepeso. Estratégias desse tipo podem ser úteis, por exemplo, para identificar a relação entre conteúdos linguísticos específicos e os grupos de pertença dos indivíduos entrevistados. Além disso, conforme mencionado anteriormente, é possível conjugar a Análise de Especificidades com uma Análise de Similitude, fornecendo uma representação gráfica que informa tanto sobre as características estruturais de um conjunto de textos como sobre tendências na distribuição das suas formas linguísticas constitutivas em função de grupos específicos de comparação.
Note-se, ainda, que objetivos comparativos podem ser desenvolvidos de, ao menos, duas maneiras: (i) analisar separadamente diferentes corpora construídos com base nas características dos entrevistados (sexo, faixa etária, faixa de renda, profissão, estado civil, ter ou não ter passado por determinada experiência significativa, etc.); e (ii) incluir variáveis categóricas pertinentes ao problema da pesquisa em um mesmo procedimento de tratamento dos dados. A primeira estratégia tem relevância, mas a segunda traz a vantagem adicional de fornecer evidências baseadas em probabilidades, uma importante característica dos principais procedimentos lexicométricos viabilizados pelo Iramuteq. Conforme apresentado anteriormente, pouco menos da metade dos artigos analisados (n=17) neste estudo incluiu variáveis de comparação em suas análises. Ressalta-se que a operacionalização de variáveis categóricas no tratamento dos dados é um pré-requisito da Análise de Especificidades, mas não constitui condição necessária para a realização de outros procedimentos (CHD e Análise de Similitude). A despeito disso, argumenta-se que, quando pertinente, a operacionalização de variáveis categóricas contribui significativamente para o desenvolvimento de hipóteses fundamentadas na relação entre os conteúdos analisados e suas condições de produção, o que condiz com objetivos comuns a diferentes métodos de análise de conteúdo (Dany, 2016). Para Marchand (2013, p. 39), os métodos lexicométricos contribuem na mesma direção, conduzindo à pergunta sobre "por que, no universo de palavras - e categorias de palavras - possíveis, aquelas foram escolhidas e quais relações elas estabelecem entre si e com as suas condições de produção" (tradução nossa). Desse modo, a operacionalização de variáveis categóricas com auxílio do Iramuteq apresenta a vantagem de subsidiar processos inferenciais baseados na estatística textual, e não se limita a um tipo de procedimento específico, podendo ser aplicada no Método Reinert (CHD), na Análise de Especificidades e na Análise de Similitude conjugada com um cálculo de especificidades.
Feitas essas considerações sobre os resultados, convém sintetizar algumas orientações a respeito da utilização do Iramuteq na análise de dados de entrevista, sobretudo diante da observação de que poucos artigos justificaram suficientemente a escolha metodológica pelo uso do software e, menos ainda, pelo tipo de procedimento lexicométrico adotado. Com base nas recomendações de Lebart e Salem (1994), argumenta-se que o uso da estatística na análise de dados textuais pode ser decomposto, para fins de discussão, em quatro etapas.
1. Construção de um problema de pesquisa: deve haver compatibilidade entre o problema e a estratégia metodológica que será adotada. Para tanto, é preciso conhecer os fundamentos teóricos e operacionais dos procedimentos escolhidos.
2. Produção de dados pertinentes ao problema e compatíveis com a estratégia metodológica: o corpus deve satisfazer condições de homogeneidade e volume que justifiquem a utilização de métodos estatísticos. Nessa etapa, deve-se atentar para o modo como os dados de entrevistas são transcritos e organizados em um corpus textual. Isso porque algumas vezes pode ser útil adaptar o conteúdo do corpus com a finalidade de aumentar a legibilidade do software e evitar que resultados artificiais sejam produzidos por conta de variações linguísticas, típicas do discurso oral, e pouco relevantes no contexto de determinadas pesquisas (Aubert-Lotarski & Capdevielle-Mougnibas, 2002). Além disso, em análises que empregam o método Reinert (CHD), é preciso que o corpus analisado seja suficientemente volumoso e que o material tenha certa coerência temática ou que seja homogêneo em suas condições de produção (Dalud-Vincent, 2011). Por isso, recomenda-se que os estudos apresentem, em seus relatos de pesquisa, o percentual do material que foi retido na CHD, notadamente porque um aproveitamento menor que 75% pode indicar problemas na homogeneidade do corpus (Camargo & Justo, 2017). Apesar da relevância dessa informação, apenas 18 dos 33 artigos que utilizaram o Método Reinert (CHD) apresentaram o percentual de aproveitamento.
3. Tratamento estatístico do material textual: a mineração dos dados deve ser pertinente ao problema da pesquisa e ser realizada com finalidades exploratórias, no intuito de reestruturar o material com base em critérios formais. Pode também estar baseada em testes de hipóteses passíveis de verificação em termos de probabilidade. Por exemplo, pode-se trabalhar com a hipótese de que existem diferenças significativas no conteúdo produzido pelos entrevistados em função de algumas de suas características, seus grupos de pertença e determinadas condições de participação social.
4. Interpretação dos resultados: os processos inferenciais devem ser fundamentados em reflexões críticas sobre a validade e o significado das observações. Por exemplo, deve-se enfatizar que os conteúdos produzidos em uma entrevista são produzidos em contextos de interação entre pesquisador e participante (Fraser & Gondim, 2004), pois as características da situação de coleta também atuam como condição de produção do material analisado. Por exemplo, há que se considerar a influência do roteiro de entrevista, ou das perguntas realizadas, nos conteúdos produzidos pelos participantes, o que pode facilitar ou inibir o surgimento de conteúdos discursivos específicos. Além disso, limitações operacionais também devem ser consideradas na interpretação dos resultados. Por exemplo, algumas características constitutivas dos enunciados (se são afirmações, negações ou interrogações) produzem efeitos de sentido muito diferentes, ainda que façam uso dos mesmos verbos, adjetivos e substantivos. Apesar disso, uma CHD pode agrupar tais enunciados em uma mesma classe lexical, sem que isso indique, evidentemente, que expressem a mesma ideia ou posição diante de determinado tema (Dalud-Vincent, 2011).
Observa-se, portanto, que cada uma das etapas descritas mobiliza questões que podem influenciar as escolhas do pesquisador, de maneira que o potencial heurístico das ferramentas de análise utilizadas depende do planejamento da pesquisa como um todo, começando pela formulação do problema, não se restringindo apenas à etapa de tratamento dos dados. Nesse contexto, a escolha pela utilização do Iramuteq ou qualquer outra ferramenta baseada na lexicometria precisa, necessariamente, considerar as especificidades do problema de pesquisa, mas também do material que se pretende analisar. Entende-se que os estudos que utilizam o Iramuteq na análise de dados de entrevistas e o fazem de modo crítico e reflexivo podem aumentar o potencial contributivo do conhecimento que produzem ao conferir maior consistência metodológica às observações realizadas.
Considerações finais
A revisão empírica realizada para os fins deste estudo evidenciou que, apesar de o Iramuteq ter sido criado em 2009, seu uso por pesquisadores brasileiros mostrou crescimento mais visível somente a partir de 2015. Além de sua pouca difusão no Brasil, os próprios pesquisadores que optam por recorrer a esse software como apoio às análises de dados das entrevistas realizadas parecem desconhecer os seus recursos técnicos, o que impõe limites à apreensão das especificidades que caracterizam os fenômenos investigados. A superação desses limites pode vir a ocorrer caso aqueles que fazem uso da entrevista qualitativa como via de acesso ao mundo subjetivo (percepções, crenças, experiências e representações), e buscam ainda caracterizar compartilhamentos e especificidades entre as pessoas e grupos, estiverem mais familiarizados com softwares capazes de oferecer alternativas de análise textual estatística. Desse modo, conseguirão ampliar o alcance da interpretação analítica de seus dados e assegurar a confiabilidade do processo inferencial e interpretativo.
O Iramuteq, além de ser gratuito, oferece um leque de opções para uso de técnicas isoladas ou combinadas, vindo a atender aos anseios de todos os pesquisadores qualitativistas que pretendem ultrapassar a dicotomia quali e quanti, reconhecendo os limites e as vantagens da complementaridade na análise de dados textuais. Sendo assim, apesar de a CHD ser a técnica prevalente nos estudos revisados, seu potencial de explicação se veria ampliado caso houvesse a inclusão de variáveis categóricas no tratamento e análise textual e se recorresse também a outras técnicas complementares, como a Análise de Similitude, a AFC e a Análise de Especificidades.
Conforme destacado na seção de discussão, a análise de dados deve manter uma relação lógica com o problema de pesquisa, pois ele demarca os processos de coleta, tratamento, análise e interpretação de dados. Adicionalmente, processos inferenciais devem estar apoiados também no referencial teórico do pesquisador. A expectativa é de que a formação no nível da pós-graduação redobre cuidados para assegurar melhor alinhamento no desenho de pesquisa, particularmente no que tange aos estudos qualitativos que se utilizam da entrevista, técnica prevalente de coleta de dados entre pesquisadores considerados qualitativistas.
Por fim, sugere-se que este estudo não seja considerado conclusivo. Deixamos de fora, por exemplo, artigos que fizeram uso de entrevistas, mas cujos materiais foram analisados com auxílio do Alceste. Isso é importante, porque o Alceste precede o Iramuteq e serviu de base para a sua criação. Não podemos afirmar, portanto, que os resultados seriam semelhantes aos que encontramos caso incluíssemos artigos empíricos que utilizaram o Alceste em suas análises. Ainda que o estudo tenha ficado restrito a artigos empíricos que analisaram dados de entrevistas com o Iramuteq, desconsiderando estudos de análise documental ou trabalhos publicados em teses e dissertações, os resultados sinalizam a necessidade de fortalecer a formação de pesquisadores qualitativos no domínio de softwares de análise textual, especialmente no âmbito da pós-graduação. Dessa forma, a principal contribuição deste estudo é a de oferecer um diagnóstico crítico, o que poderá subsidiar a formação e o aperfeiçoamento de pesquisadores na utilização de softwares para fins de análise textual.
Referências
Almico, T., & Faro, A. (2014). Enfrentamento de cuidadores de crianças com câncer em processo de quimioterapia. Psicologia, saúde & doenças, 15(3), 723-737. Doi: 10.15309/14psd150313. [ Links ]
Alves, Z. M. M. B., Silva, M. H. G. F. (1992). Análise qualitativa de dados de entrevista: uma proposta. Paideia, (2), 61-69. Doi: 10.1590/S0103-863X1992000200007. [ Links ]
Aubert-Lotarski, A., & Capdevielle-Mougnibas, V. (2002). Dialogue méthodologique autour de l'utilisation du logiciel Alceste en sciences humaines et sociales : "lisibilité" du corpus et interprétation des résultats. Actes des 6ème Journées internationales d'Analyse statistique des Données Textuelles, pp. 45-56.
Azevedo, D. M., Costa, R. K. S., & Miranda, F. A. N. (2013). Uso do Alceste na análise de dados qualitativos: contribuições na pesquisa em enfermagem. Revista de Enfermagem da UFPE, 7(7), 5015-5022. Doi: 10.5205/1981-8963-v7i7a11764p5015-5022-2013. [ Links ]
Azevedo, D. M., & Miranda, F. A. N. (2012). Teoria das representações sociais e Alceste: contribuições teórico-metodológicas na pesquisa qualitativa. Saúde & Transformação Social, 3(4), 4-10. Recuperado de https://www.redalyc.org/html/2653/265324588003/. [ Links ]
Bardin, L. (1977). Análise de conteúdo. Lisboa: Edições 70. [ Links ]
Belei, R. A., Gimeniz-Paschoal, S. R., Nascimento, E. N., & Matsumoto, P. H. V. R. (2008). O uso de entrevista, observação e videogravação em pesquisa qualitativa. Cadernos de Educação, 30(1), 187-199. Doi: 10.15210/CADUC.V0I30.1770. [ Links ]
Brito Júnior, Á. F., & Feres Júnior, N. (2011). A utilização da técnica da entrevista em trabalhos científicos. Evidência, 7(7), 237-250. Recuperado de http://www.uniaraxa.edu.br/ojs/index.php/evidencia/article/view/200/186. [ Links ]
Camargo, B. V. (2005). Alceste: um programa informático de análise quantitativa de dados textuais. In A. S. P. Moreira, B. V. Camargo, J. C. Jesuino & S. M. Nóbrega (Orgs.). Perspectivas teórico-metodológicas em representações sociais (pp. 511-539). João Pessoa: EdUFPB. [ Links ]
Camargo, B. V., & Justo, A. M. (2013). Iramuteq: um software gratuito para análise de dados textuais. Temas em Psicologia, 21(2), 513-518. Doi: 10.9788/TP2013.2-16. [ Links ]
Camargo, B. V., & Justo, A. M. (2017). Tutorial para uso do software IRaMuTeQ (Interface de R pour les Analyses Multidimensionnelles de Textes et de Questionnaires). Laboratório de Psicologia Social da Comunicação e Cognição - UFSC.
Camargo, B. V., Bousfield, A. B. S., Giacomozzi, A. I., & Koelzer, L. P. (2014). Representações sociais e adesão ao tratamento antirretroviral. Liberabit, 20(2), 229-238. Recuperado de http://www.scielo.org.pe/scielo.php?pid=S1729-48272014000200004&script=sci_arttext&tlng=en. [ Links ]
Chevry Pebayle, E., & Slouma, M. (2016). Facebook et les médiathèques: entre appropriation des professionnels et réception des usagers. ESSACHESS. Journal for Communication Studies, 9(2), 125-139. Recuperado de https://hal.archives-ouvertes.fr/hal-01722421/. [ Links ]
Cúrcio, V. R. (2006). Estudos estatísticos de textos literários. Revista texto digital, 2(2), 9-28. Doi: doi.org/10.5007/%25x. [ Links ]
Dalud-Vincent, M. (2011). Alceste comme outil de traitement d'entretiens semi-directifs : essai et critiques pour un usage en sociologie. Langage et Société, 135(1), 9-28. Doi: 10.3917/ls.135.0009 [ Links ]
Dany, L. (2016). Analyse qualitative du contenu des représentations sociales. In G. Lo Monaco, S. Delouvée & P. Rateau (Orgs.). Les représentations sociales: théories, méthodes et applications (pp. 85-102). Paris: De Boeck Supérieur. [ Links ]
Denzin, N., & Lincoln, Y. (Eds.). (1994) Handbook of qualitative research (1th) London: Sage Publications Inc. [ Links ]
Fernandes, J. S. G., Montiel, J. M., Andrade, M. S., Bartholomeu, D., Cecato, J. F., & Martinelli, J. E. (2015). Análise discursiva das representações sociais de idosos sobre suas trajetórias de vida. Estudos Interdisciplinares sobre o envelhecimento, 20(3), 903-920. Recuperado de https://seer.ufrgs.br/RevEnvelhecer/article/view/46451. [ Links ]
Fraser, M. T. D., & Gondim, S. M. G. (2004). Da fala do outro ao texto negociado: discussões sobre a entrevista na pesquisa qualitativa. Paideia, 14(28), 139-152, Doi: 10.1590/S0103-863X2004000200004. [ Links ]
Furlan, R. (2017). Reflexões sobre o método nas ciências humanas: quantitativo ou qualitativo, teorias e ideologias. Psicologia USP, 28(1), 83-92. Doi: 10.1590/0103-656420150134. [ Links ]
Gibbs, G. (2009). Análise de dados qualitativos (R. C. Costa, Trad.). Porto Alegre: Artmed. [ Links ]
Huberman. A. M., & Miles, M. B. (1994). Data management and analysis methods. In N. K. Denzin & Y. S. Lincoln (Eds). Handbook of qualitative research, first edition (pp. 428-444). Thousands Oaks, CA: Sage Publications, Inc. [ Links ]
Ibiapina, A. R. D. S., Monteiro, C. F. D. S., Alencar, D. D. C., Fernandes, M. A., & Costa Filho, A. A. I. (2017). Therapeutic Workshops and social changes in people with mental disorders. Escola Anna Nery, 21(3), 1-8. Doi: 10.1590/2177-9465-EAN-2016-0375. [ Links ]
Jesus, G. J., Oliveira, L. B., Caliari, J. S., Queiroz, A. A. F. L., Gir, E. & Reis, R. K. (2017). Dificuldade do viver com HIV/Aids: entraves na qualidade de vida. Acta Paulista de Enfermagem, 30(3), 301-307. Doi: 10.1590/1982-0194201700046. [ Links ]
Jodelet, D. (2005). Loucuras e representações sociais. Petrópolis: Vozes. [ Links ]
Justo, A. M., & Camargo, B. V. (2014). Estudos qualitativos e o uso de softwares para análises lexicais. In C. Novikoff, S. R. M. Santos & O. B. Mithidieri (Orgs.). Caderno de artigos: X SIAT & II Serpro (pp. 37-54). Rio de Janeiro: Lageres. [ Links ]
Justo, A. M. (2016). Corpo e representações sociais: sobrepeso, obesidade e práticas de controle de peso. Tese de Doutorado, Universidade Federal de Santa Catarina, Florianópolis, Santa Catarina. [ Links ]
Kalampalikis, N. (2003). L'apport de la méthode Alceste dans l'analyse des représentations sociales. In J.-C. Abric (Org.). Méthodes d'étude des représentations sociales (pp. 147-163). Ramonville-Saint-Agne: Érès. [ Links ]
Landivar, D. S., Mathonnat, C., & Tichit, A. (2015). Classification des systèmes de monnaies non-bancaires: ce que disent les données du Web. Etudes & documents, 25, 1-25. Recuperado de https://halshs.archives-ouvertes.fr/halshs-01100849/. [ Links ]
Lebart, L., & Salem, A. (1994). Statistique textuelle. Paris: Dunod. [ Links ]
Leblanc, J.-M. (2015). Proposition de protocole pour l'analyse des données textuelles: pour une démarche expérimentale en lexicométrie. Nouvelles perspectives en sciences sociales (NPSS), 11(1), 25-63. Doi:10.7202/1035932ar. [ Links ]
Leite, G. de O., Martins, F. D. P., França, M. S. de, Ângelo, B. H. de B., Vasconcelos, M. G. L. de, & Pontes, C. M. (2016). Representações sociais de mulheres sobre o cheiro do leite materno. Escola Anna Nery, 20(4), 1-8. Doi: 10.5935/1414-8145.20160090. [ Links ]
Loubère, L., & Ratinaud, P. (2014). Documentation IraMuTeQ - 0.6 alpha 3 version 0.1. Recuperado de http://www.iramuteq.org/documentation/fichiers/documentation_19_02_2014.pdf
Marchand, P. (2013). Quelques traces chronologiques de l'exploration textométrique. Bulletin de Méthodologie Sociologique, 120(1), 38-46. Doi: 10.1177/0759106313497856. [ Links ]
Marchand, P., & Ratinaud, P. (2012). L'analyse de similitude appliquée aux corpus textuels: les primaires socialistes pour l'élection présidentielle française. Actes des 11ème Journées internationales d'Analyse statistique des Données Textuelles, pp. 687-699.
Moscovici, S. (2009). Representações sociais: investigações em Psicologia Social (6a ed.). Petrópolis: Vozes. [ Links ]
Moscovici, S. (2012). A Psicanálise, sua imagem e seu público. Petrópolis: Vozes. [ Links ]
Nascimento, A. R. A., & Menandro, P. R. M. (2006). Análise lexical e análise de conteúdo: uma proposta de utilização conjugada. Estudos e Pesquisas em Psicologia, 6(2), 72-88. Recuperado de https://www.e-publicacoes.uerj.br/index.php/revispsi/article/view/11028. [ Links ]
Nascimento, A. O., & Faro, A. (2015). Estratégias de enfrentamento e o sofrimento de mães de filhos com paralisia cerebral. Salud & Sociedad, 6(3), 195-210. [ Links ]
Negreiros, F., Silva, C. F. C., Sousa, Y. L. G., & Santos, L. B. (2017). Análise psicossocial do fracasso escolar na Educação de Jovens e Adultos. Revista Psicologia em Pesquisa, 11(1), 1-11. Doi: 10.24879/201700110010066. [ Links ]
Oliveira, D. C., Teixeira, M. C. T. V., Fischer, F. M., & Amaral, M. A. (2003). Estudo das representações sociais através de duas metodologias de análise de dados. Revista de Enfermagem da UERJ, 11(3), 317-327. [ Links ]
Pélissier, D. (2017). Initiation à la lexicométrie: approche pédagogique à partir de l'étude d'un corpus avec le logiciel Iramuteq. IDETCOM - Université Toulouse.
Poupart, J. (2008). A entrevista de tipo qualitativo: considerações epistemológicas, teóricas e metodológicas. In J. Poupart, J. P. Deslauriers, L. H. Groulx, A. Laperriere, R. Mayer & A. P. Pires (Orgs.) A pesquisa qualitativa: enfoques, epistemológicos e metodológicos (pp. 215-253). Petrópolis: Editora Vozes. [ Links ]
Ratinaud, P. (2014). Iramuteq: Interface de R pour les Analyses Multidimensionnelles de Textes et de Questionnaires - 0.7 alpha 2. Recuperado de http://www.iramuteq.org.
Reinert, M. (1983). Une méthode de classification descendante hiérarchique: application à l'analyse lexicale par contexte. Cahiers de l'analyse des données, 8(2), 187-198. [ Links ]
Reinert, M. (1986). Un logiciel d'analyse lexicale: Alceste. Cahiers de l'analyse des données, 11(4), 471-484. [ Links ]
Reinert, M. (1987). Classification Descendante Hierarchique et Analyse Lexicale par Contexte - Application au Corpus des Poesies D'A. Rimbaud. Bulletin de Méthodologie Sociologique, 13(1), 53-90. Doi: 10.1177/075910638701300107. [ Links ]
Reinert, M. (2002). Alceste: un logiciel d'aide pour l'analyse de discours. Notice simplifiée (de la version de base commune aux versions 4x).
Reinert, M. (2001). Alceste, une méthode statistique et sémiotique d'analyse de discours. Application aux Rêveries du promeneur solitaire. Revue française de psychiatrie et de psychologie médicale, 5(49), 32-36. [ Links ]
Salem, A. (1986). Segments répétés et analyse statistique des données textuelles. Histoire & Mesure, 1(2), 5-28. Recuperado de https://www.jstor.org/stable/pdf/24565797.pdf?seq=1#page_scan_tab_contents. [ Links ]
Salgado, A. G. A. T., Araújo, L. F., Santos, J. V. O., Jesus, L. A., Fonseca, L. K. S., & Sampaio, D. S. (2017). Velhice LGBT: uma análise das representações sociais entre idosos brasileiros. Ciências Psicológicas, 11(2), 155-163. Doi: 10.22235/cp.v11i2.1487. [ Links ]
Sampieri, R. H., Fernández-Colado, C., & Lucio, P. B. (2006). Metodologia da investigação (4a ed.). México: MacGraw-Hill Interamericana. [ Links ]
Santos, V., Salvador, P., Gomes A., Rodrigues, C., Tavares, F., Alves, K., & Bezerril, M. (2017). Iramuteq nas pesquisas qualitativas brasileiras da área da saúde: scoping review. 6º Congresso Ibero-Americano em Investigação Qualitativa, pp. 392-401.
Scribano, A. O. (2008). Entrevista en Profundidad. In A. O. Scribano (Org.). El proceso de investigación social cualitativo (pp. 71-97). Buenos Aires: Prometeo Libros Editorial. [ Links ]
Silva, M. L. B., & Bousfield, A. B. S. (2016). Representações sociais da hipertensão arterial. Temas em Psicologia, 24(3), 895-909. Doi: 10.9788/TP2016.3-07. [ Links ]
Silva, S. É. D., Camargo, B. V., & Padilha, M. I. (2011). A teoria das representações sociais nas pesquisas da Enfermagem brasileira. Revista Brasileira de Enfermagem, 64(5), 947-951. Recuperado de https://www.redalyc.org/html/2670/267022214021/. [ Links ]
Silverman, D. (2009). Interpretação de dados qualitativos: métodos para análise de entrevistas, textos e interações (Magda França Lopes, Trad.). Porto Alegre: Artmed. [ Links ]
Sousa, Á. F. L., Queiroz, A. A. F. L. N., Oliveira, L. B., Moura, M. E. B., Batista, O. M. A., & Andrade, D. (2016). Representações sociais da enfermagem sobre biossegurança: saúde ocupacional e o cuidar prevencionista. Revista Brasileira de Enfermagem, 69(5), 864-871. Doi: 10.1590/0034-7167-2015-0114. [ Links ]
Sousa. E. S., Rodrigues, M., Rocha, F., & Martins, C. (2009). Guia de utilização do software Alceste: uma ferramenta de análise lexical aplicada à interpretação de discursos de atores na agricultura. Planaltina, DF: Embrapa Cerrados. [ Links ]
Wachelke, J., Matos, F. R., Ferreira, G. C. S., & Costa, R. R. L. (2015). Um panorama da literatura relacionada às representações sociais publicada em periódicos científicos. Temas em Psicologia, 23(2), 309-325. Doi: 10.9788/TP2015.2-06-Pt. [ Links ]
Warren, C. A. B. (2001). Qualitative Interviewing. In J. F. Gubrium & J. A. Holstein (Eds.). Handbook of Interview Research: Context & Method (pp. 83-101). Thousands Oaks: Sage. [ Links ]
Zouhri, B., Garros-Levasseur, E., Weiss, K., & Valette, A. (2016). Quand les agriculteurs et les étudiants pensent l'objet pesticide: analyse discursive des représentations sociales. Pratiques Psychologiques, 22(3), 221-237. Doi: 10.1016/j.prps.2016.05.002. [ Links ]
Recebido em: 12/2/2019
Aprovado em: 18/2/2020

{kind=link}