










Serviços Personalizados
Journal

artigo
 Espanhol (pdf)
Espanhol (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
Indicadores
Compartilhar

 Permalink
PermalinkActa Comportamentalia
versão impressa ISSN 0188-8145
Acta comport. vol.21 no.4 Guadalajara 2013
ARTIGOS
Modos de lenguaje reactivos y productivos en el aprendizaje de identificación nominal
Reactive and productive language modes, their role in nominal identification learning
Carlos Ibáñez BernalI; Abril Cortés ZúñigaI; María Amelia Reyes SeáñezII; Abraham Manuel Ortiz BarradasI
IUniversidad Veracruzana (México)
IIUniversidad Autónoma de Chihuahua (México)
RESUMEN
Este estudio abordó el aprendizaje de identificación de objetos (aves) a partir de su nombre común. En el entrenamiento se aparearon en tiempo y espacio por tres ocasiones la imagen del ave y su nombre, donde este último se presentó bajo la modalidad auditiva o visual-textual. Adicionalmente se intentó conocer si ocurriría algún efecto facilitador en el aprendizaje de identificación nominal por la participación de los modos de lenguaje productivos, específicamente de hablar (decir en voz alta) o de escribir el nombre que se acababa de escuchar o de leer. Fueron seis condiciones de aprendizaje según los modos de lenguaje implicados para cada grupo experimental: 1) Leer en silencio); 2) Leer y hablar (leer en "voz alta"); 3) Leer y escribir; 4) Escuchar; 5) Escuchar y hablar (repetir en "voz alta"); 6) Escuchar y escribir. Los resultados experimentales mostraron que los modos reactivos escuchar y leer en silencio generaron las mejores ejecuciones de reconocimiento del objeto ante su nombre presentado en cualquier modalidad durante la prueba. La participación de los modos productivos, especialmente escribir, produjo bajos desempeños de reconocimiento. Se presenta un análisis de las contingencias de ocurrencia en cada condición experimental como un intento de explicar los resultados obtenidos.
Palabras clave: modo de lenguaje, identificación nominal, respuesta implícita.
ABSTRACT
This experiment was concerned with learning to identify objects (birds) based on their common names. The image of a bird was paired thrice along a training session with its name, which could appear in an auditory or in a visual-textual modality. Additionally, it intended to evaluate if productive language modes, speaking (saying aloud) or writing the just heard or read name, could have a facilitating effect on nominal identifica tion learning. Six learning conditions were arranged, according to language modes combinations: 1) Silent reading; 2) Reading and speaking (reading aloud); 3) Reading and writing; 4) Listening; 5) Listening and speaking (repeating aloud); 6) Listening and writing. Experimental results showed that reactive modes, listening and silent reading, generated better object recognizing performances when the name was presented in either modality during the test. The participation of productive modes, specially writing, produced poor recognizing performances. An occurrence contingencies analysis is offered for each experimental condition intending to explain the observed results.
Keywords: language modes, nominal identification, implicit response.
Uno de los procesos fundamentales del desarrollo verbal simbólico en la infancia consiste —para decirlo coloquialmente—en la adquisición de la capacidad de establecer relaciones entre objetos o eventos con su nombre, es decir, con la palabra socialmente convenida para referirlo (c. f. Werner & Kaplan, 1963). Esta capacidad es tan importante para la comprensión psicológica del lenguaje que algunos investigadores de la tradición analítica conductual la han identificado con el vocablo nominación (naming), proponiéndolo como término técnico, y al fenómeno como la "unidad básica de la conducta verbal" (Horne & Lowe, 1996).
De igual modo, la educación escolarizada de todos los niveles reconoce que el conocimiento de un dominio específico, como la biología, la geografía o la historia, debe iniciar con el aprendizaje de los términos especializados que hacen referencia a los objetos y eventos que en ese dominio se estudian. La habilidad de identificar un objeto a partir de su nombre constituye la base sobre la cual se construyen otros saberes y conocimientos de mayor complejidad, por lo que bien puede suponerse y justificarse la necesidad de entender a cabalidad cómo se aprende a identificar o nombrar los objetos y cuáles son las condiciones idóneas bajo las que se logra.
Tomando como base a la Teoría de la Conducta (Ribes & López, 1985), las habilidades de (a) identificar un objeto a partir de su nombre, (b) identificar un nombre a partir del objeto al que corresponde, (c) nombrar un objeto en su presencia, o (d) representar verbal o no verbalmente un objeto a partir de su nombre, corresponderían en su forma más simple a una interacción contextual. Todos los casos mencionados guardarían en principio un carácter intra-situacional invariante, isomórfico, en el que debe cumplirse la diferencialidad como criterio de ajuste (Ribes, 2010; Ribes, Moreno, & Padilla, 1996). Dichas formas de desempeño, en las que prima la relación entre objeto-nombre, tienen su origen en contingencias de ocurrencia (Ribes, 1997) que implican la presencia necesaria de ambos, del objeto y del nombre, donde este último se presenta deliberadamente al aprendiz como evento de estímulo bajo ciertas condiciones morfológicas y paramétricas de tiempo, espacio y condicionalidad.
Existen dos formas, según los medios naturales de ocurrencia, en los que se puede proporcionar a un aprendiz el nombre de un objeto de interés: El auditivo (palabra hablada) y el visual (palabra escrita). Aquí se denominan modalidades a dichas formas de presentar al aprendiz el nombre de un objeto, y modos del lenguaje (Fuentes & Ribes, 2001) a las distintas formas como éste puede responder lingüísticamente a la presentación del nombre. Se distinguen dos clases de modos del lenguaje en función de la naturaleza de los sistemas de reacción implicados, los reactivos y los activos (Fuentes & Ribes, 2001; Tamayo, Ribes & Padilla, 2009), estos últimos mejor llamados productivos (Pérez-Almonacid & Quiroga, 2010). Así, ante la presentación auditiva del nombre, el modo reactivo es "escuchar" y su complementario productivo es "hablar". Por su parte, si la presentación del nombre es visual-textual, el modo reactivo es "leer" y su correspondiente productivo es "escribir" (Fuentes & Ribes, 2001).
El análisis de la naturaleza funcional de los modos de lenguaje no debe pasar por alto, primero, que la modalidad lingüística visual-textual está fincada sobre la modalidad auditiva, ya que los signos gráficos que la constituyen representan a los sonidos que forman a las palabras. Así, leer implica responder hablando, de forma efectiva ("en voz alta") o inefectiva ("en silencio"), a los signos; y a su vez, hablar implica escuchar, explícita o implícitamente, los sonidos reproducidos. Tampoco debe soslayarse el carácter evanescente y relativamente difuso de la modalidad auditiva, en contraste con el carácter permanente y focalizado de la modalidad visual-textual, lo que de alguna manera implica demandas distintas para el contacto reactivo del organismo con el evento de estímulo convencional (nombre). Las características mencionadas pueden comportar desigualdades entre los modos, que podrían facilitar u obstaculizar el contacto reactivo y, por ende, la actualización de la función contextual.
En relación a la naturaleza funcional de los modos de lenguaje, Ribes (2007) ha planteado que los modos reactivos se vinculan al conocimiento declarativo, por estar ligado a sus fuentes, mientras que los modos activos estarían mayormente implicados en el aprendizaje de conocimiento actuativo en la medida que éstos implican acciones directas o indirectas que están vinculadas a efectos o metas. En su planteamiento, Ribes aclara que el conocimiento declarativo o "conocer" implica que la persona no ha actuado o sufrido efectos directamente respecto de lo que se conoce, lo cual supone que pudo haberlo observado, escuchado o leído. Por su parte el conocimiento actuativo o "saber" implica acciones o reacciones previas que incluyen el uso de técnicas en los dominios simbólicos, lo que supondría la intervención de la gesticulación, el habla o la escritura como medio o instrumento para el logro de los efectos requeridos en la situación.
Independientemente de las hipótesis que puedan desprenderse directamente del planteamiento de Ribes para realizar estudios experimentales que las pusieran a prueba, consideramos que es imperativo analizar la función de los modos de lenguaje reactivos y productivos específicamente en el aprendizaje de la habilidad contextual de identificar objetos por su nombre. Existen algunas importantes razones para hacerlo. Primero, porque ni la Psicología Educacional ni la Pedagogía han analizado sistemáticamente cómo se logra el aprendizaje de un dominio considerando los diferentes niveles en que se puede o se debe organizar funcionalmente el desempeño de los aprendices para cumplir el criterio que exige una determinada tarea que debe ser resuelta por ellos. Segundo, porque aunque en las disciplinas mencionadas ya se reconoce que existen efectos diferenciales en el aprendizaje de los estudiantes en función de la modalidad lingüística en que se presenta la información (Ginns, 2005; Penny, 1989; Sweller, van Merriënboer, & Paas,1998), existen reportes experimentales que parecen contradecir las principales hipótesis derivadas de los estudios de la tradición cognitiva, o se tienen apenas algunos indicios del efecto que estas modalidades tienen específicamente en el aprendizaje de una habilidad o competencia contextual. Por ejemplo, Varela, Martínez-Munguía, Padilla, Ríos y Jiménez (2004) a diferencia de los reportes de los estudios cognitivos, encontraron que la modalidad visual-textual de los nombres presentó primacía sobre la modalidad auditiva, por lo menos en una tarea de clasificación de animales, objetos o vegetales utilizando un procedimiento de igualación de la muestra. De igual forma, Ibáñez, Reyes y Mendoza (2009) realizaron un estudio para conocer el posible efecto diferencial que pudieran ejercer las modalidades auditiva y/o visual-textual en que se presentaba la información criterio en el aprendizaje de competencias contextuales, sin encontrar diferencias claras entre ellas, aunque con indicios que favorecían a la modalidad auditiva.
Una tercera razón es que se desconoce el posible efecto disposicional de los modos de lenguaje productivos en el aprendizaje de habilidades contextuales. Aunque existen estudios desde la tradición cognitiva que pudieran interpretarse en este sentido, su naturaleza la hace difícil de relacionar, como el caso del uso de "imaginería mental" que desde los años 60 se ha estudiado como un facilitador en el aprendizaje de pares asociados (Davidson, 1964; Levin & Kaplan, 1972; Reese, 1965). Otra área estudiada por psicólogos cognitivos (Slamecka & Graf, 1978), que pudiera vincularse con el problema que aquí se aborda, es la del efecto de generación (generation effect). En esta área se reportan hallazgos experimentales donde los individuos recuerdan mejor la información cuando se involucran activamente en la generación de ésta —por ejemplo al completar una palabra fragmentada— que cuando sólo la leen o escuchan pasivamente. Por ejemplo, Macklin (1985) realizó un estudio que muestra que la elaboración verbal (repetición en voz alta) y la generación de preguntas (técnicas interrogativas) sobre dicha elaboración facilitan el aprendizaje de pares asociados en niños pequeños.
Para aproximarse entonces directamente al problema, en este estudio se abordó el aprendizaje de habilidades contextuales consistentes en la identificación de distintos objetos (aves) a partir de su nombre común. Se partió del procedimiento más simple de aparear en tiempo y espacio dos eventos: a) la presentación discreta de un objeto de estímulo, y b) la ocurrencia de su nombre bajo las modalidades lingüísticas auditiva o visual-textual. Adicionalmente se intentó conocer si ocurriría algún efecto facilitador en el aprendizaje de la habilidad contextual por la participación de los modos de lenguaje productivos, específicamente de hablar (decir en voz alta) o de escribir el nombre que se acababa de escuchar o de leer. Se establecieron entonces seis condiciones de aprendizaje según los modos de lenguaje implicados: 1) Leer en silencio); 2) Leer y hablar (leer en "voz alta"); 3) Leer y escribir; 4) Escuchar; 5) Escuchar y hablar (repetir en "voz alta"); 6) Escuchar y escribir.
MÉTODO
Participantes
Participaron 24 niños que cursaban el sexto grado de primaria durante el ciclo escolar 2010- 2011 en la escuela primaria "Francisco Zarco" del Municipio de Xalapa, Veracruz. El 50% de los participantes fueron de sexo femenino y el 50% restante de sexo masculino. El promedio de edad fue de 11.73 años en un rango de 11 a 13 años. Ninguno de ellos había participado en estudios experimentales de ésta u otra índole.
Los participantes se asignaron al azar, aunque igualados por sexo, en seis grupos experimentales de 4 participantes por grupo, 2 de cada sexo.
Materiales
La presentación de todos los estímulos y el registro de respuestas se llevó a cabo mediante un programa experimental creado especialmente con el software SuperLab Pro versión 4.0.8. Para su aplicación se emplearon 4 computadoras portátiles con ratón y bocinas integradas en cubículos individuales del Instituto de Psicología y Educación de la Universidad Veracruzana, en un horario de las 9 a las 11 horas.
Se utilizaron 32 imágenes de aves del Estado de Veracruz como objetos referentes, de las cuales 15 fueron apareadas con su nombre común específico durante la fase experimental, mientras que otras 15 se presentaron como imágenes de control durante la pre-prueba y la post-prueba y 2 más como imágenes de "priming". Los nombres apareados con su imagen fueron: ámpelis, avetoro, cerceta, chara, charrán, colimbo, fandanguero, ibis, milano, mirlo, pijije, rabijunco, reyezuelo, soterillo y trogón. Durante la fase experimental, dependiendo de la condición de exposición a los estímulos, los nombres podían presentarse en la modalidad auditiva a través de las bocinas de la computadora o en la modalidad visual-textual escrito en la parte superior de la pantalla sobre la imagen del ave. En la modalidad auditiva de presentación del nombre, se reproducía una grabación 5 segundos después de la presentación de la imagen; en la modalidad visualtextual tanto el nombre escrito como la imagen iniciaban y terminaban juntos. La duración de los ensayos estaba determinada por el participante quien daba clic en una flecha colocada en la parte inferior derecha con la etiqueta "siguiente". Con propósitos de control se registró automáticamente la duración en segundos de cada ensayo.
Diseño y procedimiento
El diseño experimental general consistió de tres fases que transcurrían en una sola sesión: Pre-prueba, Fase Experimental y Post-prueba.
La Pre-prueba tuvo como propósito evaluar el grado de conocimiento que los participantes tenían sobre el tema. En la pantalla de la computadora se presentaron las siguientes instrucciones, que además eran leídas en voz alta por el instructor: "¡Bienvenido! Agradecemos tu participación en este estudio donde investigamos sobre la forma como se aprende y se siguen instrucciones. Haz tu mejor esfuerzo y recuerda seguir al pie de la letra las instrucciones que se te darán. Si tienes alguna duda dirígete a mí". Posterior a esto, iniciaba la pre-prueba. A todos los participantes se les presentó una secuencia de 30 pantallas con la pregunta: "¿Cómo se llama esta ave?". En ellas aparecía una sola imagen de las aves y ante la pregunta leída por el aplicador respondían o no con el nombre. En caso de tener una respuesta nominal, los participantes procedían a escribirla dentro de una caja de texto que se encontraba centrada bajo la imagen del ave correspondiente. En caso de no tener una respuesta, el experimentador introducía la letra "N" en la caja de texto, lo que iniciaba la presentación del siguiente ensayo. Las 15 imágenes programadas para el entrenamiento aparecieron ordenadas al azar con las otras 15 imágenes de control.
Para la Fase Experimental, o de exposición al nombre-objeto, se formaron seis grupos. En los grupos G1, G2 y G3 la presentación del nombre fue visual-textual, mientras que para los grupos G4, G5 y G6 fue auditiva. Adicionalmente los grupos difirieron en términos de la no ocurrencia de respuestas en modos productivos (G1 y G4) o de la ocurrencia de respuestas en uno de los modos productivos, ya fuere hablar (G2 y G5) o escribir (G3 y G6). La fase comenzaba con las siguientes instrucciones: "Lo que vas a tener que hacer ahora es aprender el nombre de las aves haciendo exactamente lo que te voy a pedir que hagas. Una vez que hayas realizado la actividad indicada, tienes que dar clic en la flecha que dice siguiente para pasar a otra pantalla. Cuando estés listo para iniciar, da clic en el botón 'comenzar'". Todos los grupos recibieron primeramente dos ensayos de "priming", con el propósito de probar si los participantes seguían correctamente las instrucciones de cómo responder ante los ensayos a entrenar. En estos ensayos aparecía escrita en la parte superior de la pantalla la instrucción propia a la condición particular del grupo experimental. Para el G1 la instrucción fue "Lee en silencio el nombre del ave"; para G2 "Lee en voz alta el nombre del ave"; para G3 "Escribe sin hablar con el teclado el nombre del ave después de leerlo"; para G4 "Escucha sin hablar el nombre del ave"; para G5 "Repite en voz alta el nombre del ave después de escucharlo", y para el G6 "Escribe sin hablar con el teclado el nombre del ave después de escucharlo". Posteriormente se presentaba el nombre en la modalidad correspondiente y la imagen de "priming". Luego de corroborar el desempeño correcto del participante, el aplicador retroalimentaba su ejecución con la frase "hazlo así en adelante" y dando clic en una flecha colocada a la derecha de la parte inferior de la pantalla con la etiqueta "siguiente" para iniciar. En caso de hacerlo de manera incorrecta, se volvía a presentar el ensayo mediante un clic en una flecha en la parte inferior a la izquierda de la pantalla apuntando a esta misma dirección y con la etiqueta "atrás". Sólo se inició el entrenamiento una vez que el participante hubiera ejecutado correctamente las actividades solicitadas. Los datos de estas pantallas no se tomaron en cuenta en el análisis de resultados. La exposición al par nombre-objeto consistió de 45 ensayos durante los cuales se presentaron al azar en 3 ocasiones las15 imágenes de aves. La imagen aparecía centrada en la pantalla, acompañada por una flecha en el extremo inferior derecho para cambiar de pantalla una vez realizada la actividad criterio asignada a cada grupo. Terminada la secuencia de ensayos aparecía una pantalla con la leyenda: "Has terminado esta fase del experimento".
La Post-prueba iniciaba inmediatamente después con las siguientes instrucciones: "En esta parte del experimento se te presentarán diferentes pantallas, en cada una leerás una instrucción, verás o escucharás el nombre de una ave, cuatro imágenes de aves y un botón que dice 'No sé'. Debes escoger la figura del ave que va con el nombre que oíste o leíste. Si no sabes la respuesta, no intentes adivinar, sé sincero y da clic en el botón 'No sé'. Para elegir cualquiera de las imágenes o el botón 'No sé', ubica la flecha del mouse en el centro de la imagen y oprime el botón izquierdo del mouse. Es muy importante que sigas al pie de la letra cada instrucción que leas. Cuando estés listo para iniciar da clic en el botón 'comenzar'". Se presentaron 45 pantallas donde los participantes debían identificar la imagen del ave correspondiente al nombre presentado en modalidad auditiva o visual-textual a fin de evaluar los efectos de la exposición según las condiciones experimentales. Las pantallas seguían un arreglo de igualación de la muestra de primer orden, donde el estímulo de muestra correspondía al nombre y los estímulos de comparación (4) a las imágenes de aves. La pantalla contenía una quinta opción, el botón "No sé", que aparecía en la parte inferior central de la pantalla. Las pantallas de la post-prueba se componían de 15 ensayos presentados en 2 ocasiones (30 en total) donde el nombre se presentaba en la modalidad asignada al grupo experimental particular, y otros 15 ensayos donde el nombre se presentaba en la modalidad alterna. Estos ensayos tuvieron el objetivo de explorar si los efectos de la exposición al nombre-objeto en una modalidad particular podían afectar el desempeño ante el nombre presentado en la modalidad no entrenada. Los ensayos terminaban cuando los participantes respondían a cualquiera de los estímulos de comparación o al botón "No sé" y se registraba automáticamente esta respuesta. Al término de la secuencia programada aparecía una pantalla con la leyenda "Gracias por tu participación".
RESULTADOS
Pre-Prueba. Los resultados de esta prueba mostraron que ninguno de los participantes sabía el nombre común específico de las aves utilizadas como objeto en el experimento. Algunos de ellos, dieron un nombre genérico a algunas de ellas (p. ejem. "pato", "colibrí", etc.), los que se consideraron irrelevantes para los propósitos de este experimento.
Fase experimental. Ninguno de los participantes falló en seguir las instrucciones durante los ensayos de "priming". Con el propósito de determinar posibles efectos del tiempo de exposición a los ensayos experimentales, generada por los distintos desempeños requeridos de los participantes, se obtuvo la duración promedio en segundos de dichos ensayos para cada grupo, con los siguientes resultados: G1, 9.21 seg.; G2, 9.30 seg; G3, 22.19 seg.; G4, 12.13 seg.; G5, 14.20 seg.; G6, 21.81 seg.
Post-prueba. Las respuestas de elección dadas ante el estímulo de comparación que correspondía al nombre presentado se consideraron como respuestas correctas. Sin embargo, con el objetivo de determinar si el participante identificaba confiablemente el objeto ante su nombre solo se contabilizó como "acierto" cuando hubo respondido correctamente a los dos ensayos del mismo reactivo de la modalidad entrenada en la fase experimental. Este mismo criterio no fue posible aplicarlo para contabilizar los aciertos en la modalidad no entrenada, ya que solo se probó el efecto en un solo ensayo, por lo que si la elección del objeto era correcta, constituía un acierto. Hecha esta aclaración, las Figuras 1 y 2 muestran los porcentajes de aciertos de los participantes de los grupos experimentales. Las barras negras dispuestas hacia arriba corresponden al porcentaje de aciertos en la modalidad entrenada, mientras que las barras grises hacia abajo son de la modalidad no entrenada.
La Figura 1 contiene los desempeños de los participantes en los grupos donde en nombre se presentó en la modalidad visual-textual. Se puede observar que los participantes del G1 (Leer en silencio) tuvieron mejores desempeños que los participantes de los grupos G2 (Leer y hablar) y G3 (Leer y escribir), tanto en la modalidad entrenada como en la no entrenada. Asimismo, se aprecia que el entrenamiento con el nombre presentado en la modalidad visual-textual se trasladó a la modalidad auditiva, independientemente de la participación o no de los modos productivos de hablar o escribir.
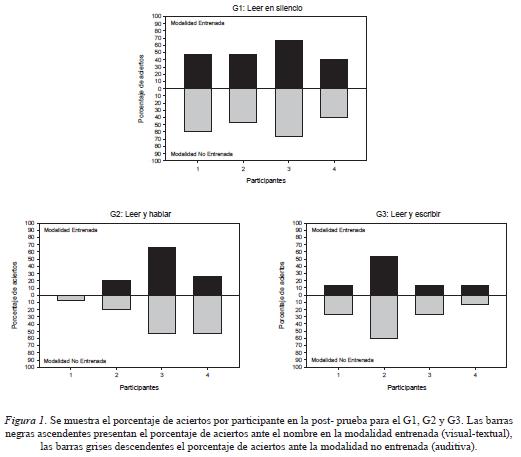
La Figura 2 muestra los porcentajes de aciertos de los grupos experimentales con el nombre presentado en modalidad auditiva. Es notable el desempeño de los participantes del G4 (Escuchar) que es superior al de los grupos G5 (Escuchar y hablar) y G6 (Escuchar y escribir) e, inclusive, al del grupo G1 (Leer en silencio). Nuevamente se observa en los tres grupos el efecto de traslado simétrico del entrenamiento con la modalidad auditiva a la modalidad visual-textual.
En la Figura 3 se comparan los desempeños generales de todos los grupos experimentales, mostrando el porcentaje promedio de aciertos obtenido en los ensayos de la modalidad entrenada (panel izquierdo) y en los de la no entrenada (panel derecho), así como el recorrido intercuartílico de los datos por grupo. Como puede notarse, el promedio más alto obtenido en la modalidad entrenada corresponde a G4 (Escuchar), con 73.33%, seguido por G1 (Leer en silencio), con 49.99%, donde ambos grupos se caracterizan por haber tenido un contacto reactivo con el nombre sin la participación de modos productivos. El grupo con el desempeño más bajo fue G3 (Leer y escribir) con 23.33% de aciertos. La diferencia entre los efectos de los tratamientos experimentales, particularmente entre los grupos G3 y G4, es evidente en la comparación de sus recorridos intercuartílicos, aun considerando la variabilidad de los datos de cada grupo, la cual se da inevitablemente por el reducido número de participantes en cada condición. La misma tendencia se observa en la modalidad no entrenada, cuyos resultados guardan la misma simetría ya comentada para los datos de los participantes individuales.
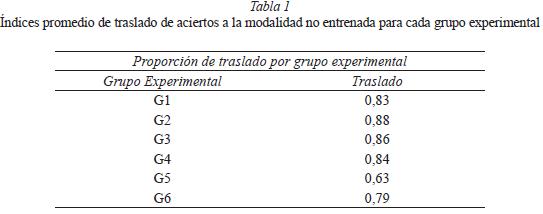
Finalmente, con el objetivo de determinar con precisión el grado de traslado del entrenamiento ocurrido de la modalidad entrenada a la no entrenada, se obtuvieron los "índices de traslado", dividiendo el número de reactivos con respuestas correctas en ambas modalidades sobre el total de aciertos en la modalidad entrenada. La Tabla 1 muestra estas proporciones.
DISCUSIÓN
Las condiciones experimentales y sus operaciones específicas generaron en los participantes, aunque en distintos grados, la identificación del objeto ante la presentación de su nombre, tanto en la modalidad entrenada como en la no entrenada. La sola exposición secuencial por pares de nombre-objeto fue suficiente para que los participantes eligieran de entre varios objetos aquél asociado a un nombre. Este responder diferencial puede caracterizarse teóricamente como una función contextual (Ribes, 2010; Ribes y López, 1985). El análisis teórico del proceso de mediación requiere detallar los estímulos y respuestas, sus relaciones de contingencia, determinar cuál es el elemento mediador del conjunto de relaciones de contingencia y caracterizar el desligamiento funcional resultante. Se supondría que analizando las contingencias de ocurrencia en cada condición experimental tendríamos elementos suficientes para dar cuenta de los efectos diferenciales en el desligamiento obtenido (c .f. Ribes, 1997).
Podemos suponer como hipótesis guía que la identificación de un objeto particular ante su nombre (Nom) escrito o escuchado dependerá de que éste evoque la respuesta implícita (Kantor, 1924; Parrot, 1984) de "observar" el objeto en su ausencia, o como se dice corrientemente, recordarlo. Si establecemos, por lo pronto, que el objeto (Obj) es el elemento mediador del sistema de contingencias establecidas, por ser lo que "da sentido" al nombre, debemos suponer que su respuesta reactiva observar (Obs) se desliga temporalmente y ahora ocurre como respuesta reactiva implícita ante el nombre. En términos coloquiales diríamos que ante el estímulo Nom, los participantes escuchan el nombre y también observan implícitamente el objeto, es decir, lo imaginan.
¿Cuáles condiciones experimentales permitieron generar mayor identificación de objetos ante el nombre escrito o leído? Intentemos un análisis de los procesos de mediación en cada grupo experimental.
En G4 (Escuchar) los participantes tuvieron desempeños en identificación superiores en promedio a los de los demás grupos. La contingencia entre el nombre en modalidad auditiva (Nom-a) y el objeto en modalidad visual (Obj-v) fue establecida por el experimentador bajo los parámetros ya descritos. Detallemos ahora las respuestas ante cada estímulo: Ante Nom-a ocurre la respuesta más simple posible, la respuesta reactiva de escuchar el nombre (Esc-n), mientras que para Obj ocurre la también simple respuesta reactiva de observar (Obs). En este grupo no hay respuestas productivas programadas y las modalidades de cada uno de los estímulos son distintas, por lo que puede suponerse en principio que no hay interferencia de ningún tipo.
En cuanto a G1 (Leer en silencio), cuyo desempeño fue el segundo más alto de los grupos, habrían ocurrido las mismas contingencias del G4, excepto por la respuesta reactiva ante el nombre en modalidad visual-textual (Nom-vt). En este caso, existen dos posibilidades de respuesta reactiva: a) Observar el patrón de estímulos, o b) leer en silencio, que supondría la compleja historia de adquisición del sistema reactivo convencional que implica: Escudriñar las grafías- hablar implícitamente-escuchar implícitamente. Si las respuestas reactivas ante Nom-vt hubieran sido las del inciso "a", los participantes habrían respondido ante el par nombre-objeto como un estímulo visual complejo, sin que el efecto del entrenamiento se trasladara a la modalidad auditiva. Por lo tanto, el hecho de haber encontrado en la post-prueba un alto índice de traslado (0,83) de la modalidad visual-textual a la auditiva nos hace suponer que los participantes leyeron, y que este patrón de respuestas reactivas seguramente incluye el elemento terminal del escuchar implícito. Coloquialmente diríamos que estos participantes, cuando leen el nombre saben cómo se escucha; por ello, cuando menos en este caso, diríamos que leer es hablar escuchando lo que está escrito. Para dar cuenta de la calidad del desempeño de los participantes bajo las condiciones experimentales de este grupo, es necesario considerar que el escuchar implícito del nombre está en función de su habilidad y desempeño actual como lector, escudriñando grafías y hablando implícitamente, lo que constituye una hipótesis a corroborarse empíricamente.
G5 (Escuchar y hablar) tuvo un desempeño ligeramente más bajo que G1. La única diferencia en cuanto a las contingencias ocurridas en este grupo en comparación con las de G4 (Escuchar) es el patrón de respuesta ante el nombre. En este caso, ante Nom-a ocurre la respuesta reactiva escuchar el nombre (Esc-n), luego la respuesta productiva de hablar o decir el nombre en voz alta (Hbl-n) cuyo producto es un estímulo auditivo Nom-a2, que a su vez genera la respuesta reactiva de escuchar el nombre (Esc-n2) por segunda ocasión. Tenemos entonces que para este grupo, el nombre, entendido como segmento de estímulo, ocurre en cada ensayo dos veces, con sus necesarias diferencias morfológicas, funcionales y temporales. Este hecho puede ayudar a esclarecer las razones de su menor desempeño en la post-prueba que G4, el grupo que solo escucha. La repetición del nombre en los ensayos pudo haber provocado condiciones vinculadas al fenómeno de "inhibición reactiva" (Hull, 1951), dificultando la contextualización nombre-objeto. El efecto pudiera ser análogo al de "saciedad verbal o semántica" (Lambert & Jakobovits, 1960), originalmente denominado "lapso de significado" (Severance & Washburn, 1907), consistente en que ante la repetición de una palabra ésta "pierde" significado, lo que requeriría estudiarse específicamente en el aprendizaje de identificación nominal.
En G6 (Escuchar y escribir), siguiente grupo en mostrar un menor desempeño respecto a G5 que acabamos de discutir, el patrón de respuestas ante el nombre que se presenta en modalidad auditiva (Nom-a) es el siguiente: La respuesta reactiva de escuchar el nombre (Esc-n), luego la respuesta productiva de escribir o transcribir el nombre escuchado (Trs-n) cuyo producto es el estímulo visual-textual (Nom-vt) que genera la respuesta reactiva de "leer en silencio" y que, como ya se dijo para G1, implica el sistema reactivo convencional que consiste en escudriñar las grafías- hablar implícitamente-escuchar implícitamente (Esc-n2). Puede entonces resultar evidente que en este caso el modo productivo escribir, que genera el estímulo visualtextual Nom-vt y que es leído por el participante, interfiere el contacto con Obj, el evento mediador visual del sistema de contingencias. En términos coloquiales diríamos que tener que transcribir el nombre que se ha escuchado distrae al participante de atender al objeto y sus características. Dadas estas condiciones, no sorprenden los bajos porcentajes de identificación de este grupo.
Por su parte, G2 (Leer y hablar) o leer en voz alta tiene ante el nombre presentado en modalidad visual-textual (Nom-vt) el siguiente patrón de respuestas: La respuesta reactiva de escudriñar las grafías, luego la respuesta productiva de hablar o decir el nombre (Hbl-n), cuyo producto es el estímulo auditivo Nom-a que a su vez genera la respuesta reactiva de escuchar el nombre (En). El desempeño de este grupo debe comparase con el que presentó G1 (Leer en silencio) ya que su principal diferencia es la respuesta productiva de hablar en voz alta. A reserva de corroborar con más estudios si este efecto es consistente, y que el menor desempeño global de G2 no se debió solo a la ejecución del Participante 1 con cero identificaciones en la modalidad entrenada, puede concluirse tentativamente que el modo productivo de hablar en voz alta pudo tener un efecto disposicional negativo. Sin embargo, consideramos que las contingencias de ocurrencia de G1 (Leer en silencio) y G4 (Leer y hablar) son funcionalmente las mismas.
Finalmente, G3 (Leer y escribir), con el patrón de respuestas ante el nombre más complejo, fue el grupo experimental que tuvo el desempeño más bajo que todos los demás. Ante el nombre en modalidad visual-textual (Nom-vt), el participante pudo leer en silencio (escudriñar las grafías-hablar implícitamenteescuchar implícitamente). Luego, ocurría la respuesta productiva de escribir o transcribir el nombre leído o escuchado (Trs-n) cuyo producto es otra vez el estímulo visual-textual Nom-vt2, que nuevamente generaría el sistema reactivo convencional de "leer en silencio": Escudriñar las grafías-hablar implícitamenteescuchar implícitamente (Esc-n2). Aquí puede recurrirse por lo menos a dos posibilidades de interferencia del contacto con el objeto: La emisión de la respuesta productiva de escribir, y la doble lectura del nombre (Nom-vt y de Nom-vt2). Pero también, pudo ocurrir el efecto ya mencionado de "saciedad semántica" ante la repetición visual del nombre.
En resumen, se puede decir que a partir de un análisis de los procesos de mediación, detallando los estímulos, respuestas y sus relaciones de contingencia, es posible dar cuenta de los resultados del presente experimento. Los grupos G4 (Escuchar) y G1 (Leer en silencio), que estuvieron expuestos a la presentación de los estímulos solo en modos reactivos, tuvieron mejores desempeños que los grupos a los que se les pedía responder también en modos productivos (hablar y escribir). Los modos productivos pudieron tener un carácter disposicional interferente en el contacto con el Objeto, considerado aquí el objeto mediador visual del sistema de contingencias. Dicho carácter interferente pudiera ser resultado de: a) la complejidad de las respuestas productivas requeridas por la tarea, b) las características de modalidad en que se presentan los estímulos nombre y objeto, y c) las características de modalidad de los productos de las respuestas productivas requeridas por la tarea. Si ambos estímulos son visuales, esto es, relativamente permanentes y focalizados, y se presentan de manera simultánea, como en las condiciones de G1, G2 y G3, el contacto con uno u otro estímulo podría depender de la contigüidad espacial entre ellos; a mayor distancia, mayor incompatibilidad en el contacto con cada uno de ellos. En cambio, si los estímulos difieren en modalidad, objeto visual y nombre auditivo como en G4, G5 y G6, dicha incompatibilidad para el contacto con los estímulos simultáneos no existe, lo que presentaría mejores condiciones para su contextualización. Sin embargo, al requerir la tarea respuestas lingüísticas productivas cuyos productos son de naturaleza visual, aparece nuevamente la incompatibilidad para el contacto con el objeto mediador también visual, interfiriendo así con su contextualización.
Aunque sería aún prematuro pretender generalizar estas observaciones e interpretaciones a los resultados de otros estudios, se ha querido mostrar que el análisis de las contingencias de ocurrencia puede ser una herramienta que arrojaría elementos suficientes para comprender y guiar la investigación sobre el aprendizaje de una habilidad o competencia determinada.
REFERENCIAS
Davidson, R. E. (1964). Mediation and ability in pair-associate learning. Journal of Experimental Psychology, 55, 352-356. [ Links ]
Fuentes, M., & Ribes, E. (2001). Un análisis funcional de la comprensión lectora como interacción conductual. Revista Latina de Pensamiento y Lenguaje, 9, 181-212. [ Links ]
Ginns, P. (2005). Meta-analysis of the modality effect. Learning and Instruction, 15, 313-331. [ Links ]
Horne, P. J., & Lowe, C.F. (1996). On the origins of naming and other symbolic behavior.Journal of the Experimental Analysis of Behavior, 65, 185-241. [ Links ]
Hull, C. L. (1951). Essentials of behavior. Westport, Connecticut: Greenwood Press. [ Links ]
Ibáñez, C., Reyes, M.A., & Mendoza, G. (2009). Modalidad lingüística del discurso didáctico y aprendizaje de competencias contextuales. ActaComportamentalia, 17, 333-350. [ Links ]
Kantor, J. R. (1924). Principles of psychology, Vol. I. Chicago, Illinois: Principia Press, Inc. [ Links ]
Lambert, W. E. and Jakobovits, L. A. (1960).Verbal satiation and changes in the intensity of meaning. Journal of Experimental Psychology, 60, 376–383.
Levin, J., & Kaplan, S. A. (1972). Imaginal facilitation in pair-associate learning: A limited generalization. Journal of Educational Psychology, 63, 429-432. [ Links ]
Macklin, M.C. (1985). Imagery and paired-associate learning in pre-schoolers. En , E.C. Hirschman, & M.B. Holbrook (Eds.), Advances in Consumer Research (pp. 37-41). Provo UT: Association for Consumer Research. [ Links ]
Parrot, L. J. (1984). Listening and Understanding. The Behavior Analyst, 7, 29-39. [ Links ]
Penney, C. G. (1989). Modality effects and the structure of short-term memory. Memory and Cognition, 17, 398-442. [ Links ]
Pérez-Almonacid, R., & Quiroga, L. A. (2010). Lenguaje: Una aproximación interconductual. Bogotá: Iberoamericana Corporación Universitaria. [ Links ]
Reese, H. W. (1965). Imagery in pair-associate learning. Journal of Experimental Child Psychology, 2, 290- 296. [ Links ]
Ribes, E. (1997). Causality and Contingency: Some conceptual considerations. The Psychological Record, 47, 619-635. [ Links ]
Ribes, E. (2007). Lenguaje, aprendizaje y conocimiento. Revista Mexicana de Psicología, 24, 7-14. [ Links ]
Ribes, E. (2010). Acerca de las funciones psicológicas: Un post-scriptum. En E. Ribes (Comp.),Teoría de la Conducta 2: Avances y extensiones (pp. 57-67). México: Trillas. [ Links ]
Ribes, E., & López, F. (1985). Teoría de la Conducta: Un análisis de campo y paramétrico. México: Trillas. [ Links ]
Ribes, E., Moreno, R., & Padilla, A. (1996). Un análisis funcional de la práctica científica: Extensiones de un modelo psicológico. Acta Comportamentalia, 4, 205-235. [ Links ]
Severance, E., & Washburn, M. (1907). The loss of associative power in words after long fixation. American Journal of Psychology, 18, 182–186.
Slamencka, N.J. & Graf, P. (1978). The generation effect: Delineation of a phenomenon. Journal of Experimental Psychology: Human, Learning & Memory, 4, 592-604 [ Links ]
Sweller, J., van Merriënboer, J. J. G., & Paas, F. G. W. C. (1998).Cognitive architecture and instructional design. Educational Psychology Review, 10, 251-296. [ Links ]
Tamayo, J., Ribes, E., & Padilla, M.A. (2009). Análisis de la escritura como modalidad lingüística. Acta Comportamentalia, 18, 87-106. [ Links ]
Varela, J., Martínez-Munguía, C., Padilla, M. A, Ríos, A. y Jiménez, B. (2004) ¿Primacía visual? Estudio sobre la transferencia basada en la modalidad de estímulo y en el modo lingüístico. International Journal of Psychology and Psychological Therapy, 4, 67-77. [ Links ]
Werner, H., & Kaplan, B. (1963).Symbol Formation: An Organismic-Developmental Approach to Language and the Expression of Thought. New York: John Wiley & Sons, Inc. [ Links ]
 Endereço para correspondência:
Endereço para correspondência:
Carlos Ibáñez Bernal
Centro de Estudios e Investigaciones en
Conocimiento y Aprendizaje Humano (CEICAH),
Universidad Veracruzana, Av. Orizaba 203,
Col. Obrero Campesina, Xalapa, Veracruz,
México, C.P. 91020.
E-mail: cibanez@uv.mx
Received: May 22, 2013
Accepted: September 16, 2013
