










Serviços Personalizados
Journal

artigo
 Português (pdf)
Português (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
Indicadores
Compartilhar

 Permalink
PermalinkPsicologia em Pesquisa
versão On-line ISSN 1982-1247
Psicol. pesq. vol.6 no.2 Juiz de Fora dez. 2012
https://doi.org/10.5327/Z1982-12472012000200005
http://dx.doi.org/10.5327/Z1982-12472012000200005
ARTIGOS
Similaridade Ortográfica e Reconhecimento de Letras na Tarefa de Reicher-Wheeler*
Orthographic Similarity and Letter Recognition in the Reicher-Wheeler Task
Francis Ricardo dos Reis JustiI; Cláudia Nascimento Guaraldo JustiII
IUniversidade Federal de Alagoas
IIUniversidade Federal de Juiz de Fora
RESUMO
Esse estudo investiga o efeito do número de vizinhos ortográficos e o efeito do número de vizinhos transpostos no reconhecimento de letras em pseudopalavras em uma tarefa de Reicher-Wheeler. Participaram dessa pesquisa 34 estudantes universitários que falam o português do Brasil. Observou-se que as letras das pseudopalavras que tinham muitos vizinhos ortográficos foram reconhecidas com maior precisão do que as letras das pseudopalavras que não tinham vizinhos ortográficos. Além disso, as letras das pseudopalavras que tinham um vizinho transposto foram reconhecidas com maior precisão do que as das pseudopalavras que não os tinham. O efeito dessas variáveis pode ser explicado por um processo de retroalimentação que ocorreria entre as representações ortográficas das palavras e de suas letras componentes.
Palavras-chave: Reconhecimento visual de palavras; vizinhança ortográfica; vizinhos transpostos; tarefa de Reicher-Wheeler.
ABSTRACT
This study investigated the effects of orthographic neighbors and transposed letter neighbors on letter recognition accuracy in pseudoword stimuli using the Reicher-Wheeler task. Thirty-four Brazilian university students took part in this study. Letter recognition was more accurate for pseudowords with a high number of orthographic neighbors than for pseudowords without orthographic neighbors. In addition, letter recognition for pseudowords with a transposed letter neighbor was better than letter recognition for pseudowords without transposed letter neighbors. It is argued that these effects can be explained by a feedback mechanism acting between the orthographic representations of words and the orthographic representations of letters.
Keywords: Visual word recognition; orthographic neighborhood; transposed letter neighbors; Reicher-Wheeler Task.
É comum os modelos cognitivos de leitura hábil (Coltheart, Rastle, Perry, Langdon & Ziegler, 2001; Grainger & Jacobs, 1996; McClleland & Rumelhart, 1981; Whitney & Lavidor, 2005) proporem que o processo de reconhecimento visual de uma palavra depende de mecanismos de interação e competição. Isso ocorre porque boa parte desses modelos foi inspirada na arquitetura do modelo de Ativação Interativa e Competição (AIC) de McClleland e Rumelhart (1981). Nele, o reconhecimento de uma palavra inicia quando as unidades responsáveis por detectar suas letras componentes enviam ativação para a sua representação ortográfica. No entanto, esse processo não é unidirecional, uma vez que, à medida que a representação ortográfica de uma palavra recebe ativação, essa retroalimenta suas letras componentes. Como ao receber ativação uma letra também envia ativação para todas as palavras que a contêm, muitas vezes ocorre de mais de uma representação ortográfica se tornar ativa em nossa mente. Para resolver esse conflito, o modelo AIC postula que as representações ortográficas das palavras se inibem mutuamente. Daí a ideia de mecanismos de ativação interativa entre diferentes níveis de processamento (letra-palavra e palavra-letra) e de competição entre as representações ortográficas das palavras no léxico ortográfico (palavra-palavra).
Uma consequência lógica de modelos que adotam esse tipo de estrutura representacional é que a similaridade ortográfica que uma palavra tem para com outras deve afetar o seu processamento. Isso ocorre porque se duas palavras compartilham um grande número de letras, é provável que as representações ortográficas de ambas se tornem ativas e se inibam mutuamente, fazendo com que sejam reconhecidas com mais lentidão. Ao mesmo tempo, é uma consequência lógica desses modelos que as letras compartilhadas por muitas palavras sejam reconhecidas mais rapidamente, pois receberiam retroalimentação de fontes diferentes. Assim, considerando a importância de se indexar o grau de similaridade ortográfica de uma palavra, diversas medidas têm sido propostas com esse intuito, sendo as mais comuns: o número de vizinhos ortográficos ou medida N (de Neighborhood), que corresponde ao número de palavras que podem ser formadas pela substituição de uma letra da palavra-alvo (Coltheart, Davelaar, Jonasson & Besner, 1977); o número de vizinhos ortográficos de maior frequência ou medida NF (de Neighborhood Frequency), ou seja, o número de palavras que podem ser formadas pela substituição de uma letra da palavra-alvo e que tem maior frequência de ocorrência do que ela (Grainger, O'Regan, Jacobs & Segui, 1989); e o número de vizinhos transpostos ou TLN (de Transposed Letter Neighbor), se referindo ao número de palavras formadas pela inversão na ordem de duas letras da palavra-alvo (Andrews, 1996). Por exemplo: considerando-se essas medidas, a palavra 'marco' teria: a) N igual a seis, porque pela substituição de uma de suas letras formam-se as palavras 'barco', 'parco', 'manco', 'masco', 'março' e 'marca'; b) NF igual a dois, porque as palavras 'março' e 'marca' são mais frequentes do que ela; e c) TLN igual a um, porque ao se transpor duas de suas letras forma-se a palavra 'macro'.
Devido às predições de vários modelos teóricos sobre os efeitos que a similaridade ortográfica de uma palavra pode ter no seu processamento, vários estudos têm sido desenvolvidos para investigar como as variáveis N, NF e TLN afetam o reconhecimento visual de palavras (Acha & Perea, 2008; Andrews, 1989, 1996; Arduino & Burani, 2004; Grainger & Jacobs, 1994, 2005; Grainger et al., 1989; Huntsman & Lima, 2002; Justi & Pinheiro, 2006, 2008; Justi & Roazzi, 2012; Laxon, Gallagher & Masterson, 2002; Paap, Johansen, Chun & Vonnahme, 2000; Perea, Carreiras & Grainger, 2004; Slattery, 2009; entre outros). No entanto, quase a totalidade dos estudos que investigaram essas variáveis tem se concentrado em determinar o efeito delas no tempo total gasto para se reconhecer uma palavra. Porém, como exposto anteriormente, os modelos de leitura hábil predizem claramente que as variáveis também podem afetar o reconhecimento das letras. Infelizmente, poucos foram os estudos que investigaram diretamente essa possibilidade, havendo, assim, uma lacuna na literatura da área no que tange aos efeitos de similaridade ortográfica sobre o reconhecimento de letras, questão que será discutida a seguir.
A principal tarefa utilizada para estudar a detecção de letras na área de reconhecimento visual de palavras é a tarefa de Reicher-Wheeler (Reicher, 1969; Wheeler, 1970). Nessa tarefa, um estímulo (que pode ser uma palavra, uma pseudopalavra1 ou uma letra) é apresentado muito rapidamente e depois mascarado (#####), mostrando, na sequência, duas letras alternativas referentes à determinada posição do estímulo, cabendo ao participante decidir qual dessas letras estava presente na posição-alvo do estímulo. Por exemplo: após o mascaramento da palavra 'bola', podem ser apresentadas como alternativas na terceira posição a letra 'l' e a letra 't' e o participante deve decidir qual delas estava presente no estímulo apresentado. Um controle importante nessa tarefa é que quando o estímulo é uma palavra, as duas letras apresentadas formam palavras, e quando o estímulo é uma pseudopalavra, as duas letras apresentadas também formam pseudopalavras.
Um dos principais achados relatados inicialmente por Reicher (1969) e Wheeler (1970) com essa tarefa é que as letras de uma palavra são reconhecidas de forma mais precisa do que as apresentadas isoladamente ou em conjuntos de letras sem significado, como é o caso de dtsa. Desde então, os achados dessa tarefa têm sido interpretados como evidência da influência do processo de retroalimentação que as representações ortográficas das palavras exercem sobre suas letras componentes tal como proposto no modelo AIC (McClleland & Rumelhart, 1981; Grainger & Jacobs, 1994).
Infelizmente, apesar da tarefa de Reicher-Wheeler ser interpretada como uma das principais formas de investigar o mecanismo de retroalimentação entre palavras e letras, e de existir uma clara justificativa para se esperar um efeito de similaridade ortográfica no reconhecimento de letras nessa tarefa, poucos estudos investigaram os efeitos de N e NF na tarefa de Reicher-Wheeler (Grainger & Jacobs, 1994, 2005; Johnston, 1978; Paap et al., 2000) e nenhum analisou os efeitos de TLN.
Um dos primeiros trabalhos a avaliar o efeito de similaridade ortográfica na tarefa de Reicher-Wheeler foi o de Johnston (1978). Porém, a manipulação de N foi apenas indireta. O autor investigou se palavras que tinham muitas letras alternativas em determinada posição as tinham reconhecidas com menos precisão do que as palavras com poucas letras alternativas em determinada posição (por exemplo: a partir de mudanças na terceira letra da palavra 'bola', podem ser formadas várias palavras como 'boba', 'boca', boda' e 'bota', já a partir de mudanças na quarta letra da palavra 'raspar', pode ser formada apenas a palavra 'rasgar').
Johnston (1978) observou que as palavras com muitas letras alternativas (muitos vizinhos ortográficos) em uma determinada posição foram reconhecidas com maior precisão do que as que tinham poucas (poucos vizinhos ortográficos), porém esse efeito não foi replicado em um segundo experimento. Um dos problemas desse estudo é que o N foi manipulado de forma indireta, considerando-se apenas a posição de uma das letras das palavras, e isso pode ter afetado os resultados da pesquisa.
Os únicos trabalhos que realizaram manipulação mais direta de N ou NF na tarefa de Reicher foram os de Grainger e Jacobs (1994, 2005) e o de Paap et al. (2000). Em seu estudo de 1994, realizado com falantes da língua francesa, Grainger e Jacobs investigaram se o fato de uma palavra infrequente ser similar ortograficamente a uma palavra mais frequente prejudica o reconhecimento de suas letras na tarefa de Reicher-Wheeler. De acordo com os autores, todas as palavras-alvo tinham apenas um vizinho ortográfico (N=1), sendo que para metade delas esse era um vizinho ortográfico mais frequente (NF=1) e para a outra metade esse era um vizinho ortográfico menos frequente (NF=0). Das duas letras a serem reconhecidas no estudo, uma sempre formava a palavra alvo e a outra a palavra que lhe era similar pela mudança de uma letra. Grainger e Jacobs observaram que quando as palavras da língua francesa tinham um vizinho ortográfico mais frequente, suas letras eram reconhecidas com menor precisão do que quando tinham um vizinho ortográfico menos frequente, ou seja, NF teve efeito inibidor no reconhecimento das letras. Os autores hipotetizaram que esse efeito poderia ser proveniente de duas fontes. A primeira seria um mecanismo de retroalimentação existente entre a representação ortográfica das palavras e a das letras que resultaria, no caso da palavra ter um vizinho ortográfico mais frequente, no envio de ativação para a letra alternativa, prejudicando a identificação da letra-alvo (lembre-se que a letra alternativa sempre formava o vizinho ortográfico da palavra apresentada).
Já a segunda fonte, corresponderia à inferência da letra-alvo a partir da identificação completa da palavra apresentada. No entanto, se essa palavra tivesse um vizinho ortográfico mais frequente, os participantes poderiam, equivocadamente, identificar esse vizinho ortográfico e inferir a letra errada na hora de responder, daí o efeito inibidor de NF.
Visando replicar este efeito relatado por Grainger e Jacobs (1994), Paap et al. (2000) desenvolveram três experimentos utilizando a versão padrão da tarefa de Reicher-Wheeler com falantes da língua inglesa. No primeiro, Paap et al. manipularam o número de vizinhos ortográficos (N), o número de vizinhos ortográficos de maior frequência de ocorrência (NF) e a frequência de ocorrência das palavras da língua inglesa. O único efeito estatisticamente significante observado foi um inibidor de NF para as palavras de baixa frequência de ocorrência. No segundo e terceiro experimentos, a investigação concentrou-se no efeito de NF e o efeito inibidor dessa variável foi replicado em ambos os experimentos, observando-se um efeito nulo de NF apenas quando a palavra-alvo era tornada claramente disponível (nas condições em que a palavra-alvo, que era apresentada em letras capitulares, era precedida por ela mesma, porém em letras minúsculas, por dois segundos). Com base nesses resultados, Paap et al. argumentaram que o efeito de NF seria inibidor porque as palavras de alta frequência tenderiam a estar prontamente disponíveis para os participantes na hora de responderem, e ao verem uma letra compatível com uma palavra de alta frequência os participantes tenderiam a escolhê-la como resposta. Já nos casos em que a palavra-alvo é tornada claramente disponível, o efeito de NF tenderia a ser cancelado. Nesse momento, é importante notar que tanto Paap et al. quanto Grainger e Jacobs (1994) propõem que uma das formas de se responder na tarefa de Reicher-Wheeler seria baseada na inferência da letra-alvo a partir da identificação completa da palavra-alvo. No entanto, essas interpretações alternativas não eliminam a possibilidade de que um mecanismo de retroalimentação entre as representações ortográficas das palavras e das letras esteja atuante, já que esse mecanismo poderia contribuir para que tanto as palavras quanto as letras mais compatíveis com o estímulo apresentado tenham maior nível de ativação e possam ser utilizadas em um processo inferencial posterior. Em especial, é importante considerar, também, que os estudos de Paap et al. e Grainger e Jacobs não contaram com um tempo limite para a resposta dos participantes e isso pode ter contribuído para o uso de estratégias inferenciais sofisticadas. Assim, o que parece ser crucial é avaliar se, mesmo em situações nas quais é implausível o uso de inferências sofisticadas, pode-se observar um efeito de vizinhança ortográfica na tarefa de Reicher-Wheeler.
É importante notar que se os estudos anteriores investigaram o efeito de similaridade ortográfica no reconhecimento de letras em palavras, o estudo de Grainger e Jacobs (2005) analisou esse efeito no reconhecimento de letras em pseudopalavras. O procedimento adotado por Grainger e Jacobs é interessante, porque ao se considerar o modelo AIC (McClleland & Rumelhart, 1981), a única forma das letras de uma pseudopalavra serem reconhecidas com maior precisão é devido à possível ativação no léxico de representações ortográficas de palavras que são similares à pseudopalavra e a subsequente retroalimentação de suas letras componentes. Em seu estudo, Grainger e Jacobs (2005) desenvolveram três experimentos para investigar os efeitos de N sobre o reconhecimento de letras em pseudopalavras, tendo como participantes estudantes universitários falantes da língua francesa. No entanto, apenas o primeiro e o terceiro experimentos utilizaram a versão padrão da tarefa de Reicher-Wheeler e, por isso, serão descritos aqui. No primeiro, os pesquisadores compararam pseudopalavras que tinham um vizinho ortográfico compatível com a letra-alvo com pseudopalavras com um vizinho ortográfico incompatível com essa letra e observaram que, ter um vizinho ortográfico compatível facilitou o reconhecimento das letras nas pseudopalavras. Já em seu terceiro experimento, os pesquisadores utilizaram uma manipulação diferente de N e compararam pseudopalavras sem vizinhos ortográficos com pseudopalavras com um vizinho ortográfico e com pseudopalavras com mais de três vizinhos ortográficos. Nesse experimento, todos os vizinhos das pseudopalavras eram compatíveis com a letra-alvo e observou-se que as letras das pseudopalavras que tinham vizinhos ortográficos foram reconhecidas com maior precisão do que as letras das pseudopalavras sem esses vizinhos. No entanto, mesmo no estudo de Grainger e Jacobs, não se pode atribuir, exclusivamente, o efeito de N a um mecanismo de retroalimentação existente entre as representações ortográficas das palavras e das letras, porque os participantes do estudo tinham um tempo livre para responder e isso pode ter facilitado o uso de inferências.
Ao se considerar os estudos desenvolvidos sobre o efeito de similaridade ortográfica na tarefa de Reicher-Wheeler (Grainger & Jacobs, 1994, 2005; Johnston, 1978; Paap et al., 2000), pode-se dizer que, enquanto o efeito de NF foi consistentemente inibidor no reconhecimento de letras (Grainger & Jacobs, 1994; Paap et al., 2000), o efeito de N não se mostrou tão consistente assim, variando de facilitador (Grainger & Jacobs, 2005; Johnston, 1978) a nulo (Johnston, 1978; Paap et al., 2000). Assim, mais estudos acerca do efeito de N são necessários. Além disso, uma lacuna nos estudos desenvolvidos relacionados ao efeito similaridade ortográfica sobre o reconhecimento de letras na tarefa de Reicher-Wheeler é que nenhum desses estudos investigou o efeito de TLN na tarefa. Destarte, visando contribuir para suprir essas lacunas na literatura da área, o presente estudo investigou o efeito de N e o efeito de TLN no reconhecimento de letras utilizando uma tarefa de Reicher-Wheeler realizada por falantes do português do Brasil. Como o principal objetivo deste trabalho é avaliar o efeito dessas variáveis no reconhecimento de letras por meio do processo de retroalimentação entre palavras e suas letras componentes, conforme proposto pelo modelo AIC e seus derivados (Coltheart et al., 2001; Grainger & Jacobs, 1996; McClleland & Rumelhart, 1981; Whitney & Lavidor, 2005), optou-se por investigar o efeito de N e de TLN no reconhecimento de letras em pseudopalavras, da mesma forma que fizeram Grainger e Jacobs (2005). Como no modelo AIC as pseudopalavras não contam com representações lexicais próprias, essa pode ser considerada uma forma otimizada de se investigar se a pré-ativação dos vizinhos ortográficos das pseudopalavras é capaz de retroalimentar suas letras componentes, conforme esperado no modelo.
Uma diferença entre o presente estudo e o de Grainger e Jacobs (2005) é que, no último, os pesquisadores não impuseram um limite de tempo para as respostas dos participantes e isso pode ter facilitado o uso de inferências sofisticadas na adivinhação da letra. Como o foco deste trabalho é em processos automáticos relacionados à retroalimentação entre as representações ortográficas de palavras e letras, utilizou-se um limite de tempo de três segundos para as respostas, visando diminuir o uso de estratégias sofisticadas por parte dos participantes. Por fim, outro aspecto relevante é que, até onde se sabe, este artigo é o primeiro a investigar o efeito de N e TLN no reconhecimento de letras em língua portuguesa, o que estabelece um ponto de comparação com os demais estudos (Johnston, 1978; Grainger & Jacobs, 1994, 2005; Paap et al., 2000), já que foram realizados em línguas nas quais os mapeamentos grafema-fonema e fonema-grafema são bem menos previsíveis do que no português, como é o caso das línguas inglesa e francesa.
Método
Participantes
Participaram deste estudo 34 estudantes do curso de Psicologia de uma universidade federal brasileira. A pesquisa foi aprovada pelo Comitê de Ética em Pesquisa dessa instituição (nº 018238/2008-06).
Material
Os estímulos experimentais consistiram em 72 pseudopalavras que obedeceram a uma manipulação fatorial do tipo 2x2 de N e TLN. Assim, foram utilizadas 18 pseudopalavras em cada uma das quatro condições a seguir: 1.1) pseudopalavras sem vizinhos ortográficos (N=0) e sem vizinhos transpostos (TLN=0); 1.2) pseudopalavras sem vizinhos ortográficos (N=0) e com um vizinho transposto (TLN=1); 2.1) pseudopalavras com uma média de quatro vivinhos ortográficos (N=4) e sem vizinhos transpostos (TLN=0); 2.2) pseudopalavras com uma média de quatro vizinhos ortográficos (N=4) e um vizinho transposto (TLN=1). Para o cálculo do número de vizinhos ortográficos e vizinhos transpostos das pseudopalavras utilizou-se o programa N-Watch (Davis, 2005), tendo como vocabulário base a lista de palavras de Justi e Justi (2008).
Para compor a tarefa, foram acrescentados 72 estímulos, sendo 36 deles letras e os demais 36, palavras. A finalidade da inclusão foi diversificar os tipos de estímulos apresentados e as respostas possíveis para dificultar que os participantes adotassem, na hora de responder, a estratégia de escolher sempre letras que formassem pseudopalavras em suas respostas. Além disso, pode-se argumentar que isso também dificulta o uso de quaisquer outras estratégias por parte dos participantes já que elaborar uma estratégia que funcione igualmente bem para três tipos de estímulo é mais difícil do que inventar uma que funcione bem para apenas um tipo.
Procedimentos
Para controlar o efeito dos itens (Clark, 1973; Raaijmakers, Schrijnemakers & Gremmen, 1999), as 72 pseudopalavras foram divididas em duas listas, de acordo com as quatro condições experimentais, sendo que metade dos participantes foi exposta a uma delas e a outra metade à outra lista. De acordo com Clark (1973), muitas vezes os pesquisadores deixam de considerar que, em replicações do seu experimento, itens (como palavras ou pseudopalavras) diferentes podem ser utilizados, não considerando essa fonte de variação na análise dos dados. Embora a principal forma proposta por Clark (1973) para se lidar com a variação resultante do efeito dos itens fosse estatística, a variação também pode ser controlada de forma experimental (Raaijmakers et al., 1999) e é essa forma de controle que o presente estudo adotou ao dividir as pseudopalavras em duas listas. No caso, a preocupação é avaliar se a variação resultante dos dois grupos de pseudopalavras utilizados pode afetar a média entre as diferentes condições experimentais. Colocando de forma diferente, como metade dos participantes foi exposta a uma lista de pseudopalavras e a outra parte exposta a outra lista, é como se, no mesmo estudo, os efeitos de N e TLN fossem replicados em amostras de pseudopalavras diferentes. Como os dois níveis da variável 'lista' representam grupos diferentes de pseudopalavras, caso os efeitos de N e TLN não se generalizem para ambos os grupos, o esperado é que se observe interação entre a variável 'lista' e as variáveis 'N' ou 'TLN' na análise estatística.
Os participantes foram testados em uma sala cedida pela instituição de ensino, onde eram recebidos pelo pesquisador e convidados a fazer parte do estudo. Era solicitado a eles que lessem as instruções experimentais e, caso houvesse alguma dúvida quanto aos procedimentos, tinham a oportunidade de redimi-la antes de iniciarem a sessão experimental. As informações diziam que seria apresentado, muito rapidamente, na tela do computador, um estímulo que poderia ser uma letra, uma palavra ou uma palavra inventada e que o seu objetivo era indicar qual de duas letras estava presente em determinada posição do estímulo. A posição da letra a ser lembrada era indicada por um ponto de interrogação e a letra-alvo e a alternativa encontravam-se acima e abaixo dele. Como é o procedimento padrão em tarefas do tipo Reicher-Wheeler, sempre que o estímulo apresentado era uma palavra, a letra alternativa também formava uma palavra e sempre que era uma pseudopalavra, a letra alternativa também formava uma pseudopalavra. A letra-alvo aparecia acima ou abaixo do ponto de interrogação com a mesma probabilidade.
Os estímulos foram apresentados em uma configuração de tela de 640x480 pixels, na fonte 'fixedsys' de tamanho 10 e em letras capitulares, sendo a cor da fonte branca e do fundo, azul. A sequência de apresentação dos estímulos iniciava-se com uma marca de fixação "+" que durava 500 milissegundos (ms) e indicava onde o participante deveria olhar. Logo depois o estímulo-alvo, que podia ser uma letra isolada, uma palavra ou uma pseudopalavra, era apresentado por 50 ms e logo substituído por uma máscara "######" durante 400 ms. Por fim, aparecia uma deixa para a resposta "_ _ _ _ ? _", onde o ponto de interrogação indicava a posição da letra-alvo, estando acima e abaixo dele as alternativas de resposta. Os participantes deviam responder pressionando um botão com o desenho de uma seta para cima, caso a letra alvo estivesse acima do ponto de interrogação ou pressionando um botão com o desenho de uma seta para baixo, caso a letra alvo estivesse abaixo do ponto de interrogação. Para evitar o uso de estratégias de adivinhação sofisticadas por parte dos participantes, o tempo para responder foi limitado a 3 s, sendo que eles foram encorajados à responder de forma tão rápida e correta quanto possível. O estudo contou com uma sessão de treinamento constituída por 12 itens e seguiu os mesmos princípios da experimental, porém essa sessão apresentava feedback sobre a precisão das respostas e era automaticamente repetida caso os participantes apresentassem uma porcentagem de acertos menor do que 70%.
Os instrumentos utilizados para o teste foram computadores de arquitetura compatível à IBM-PC e o software para a apresentação dos estímulos e coleta dos dados de tempo de reação e porcentagem de acertos, o DMDX (Forster & Forster, 2003). O tempo de reação foi medido desde a apresentação da deixa para resposta até a resposta do participante, e a ordem de apresentação dos estímulos-alvo (letras, palavras e pseudopalavras) foi aleatória para cada participante.
Resultados
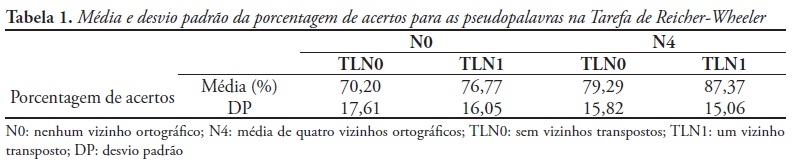
A manipulação experimental de N e TLN concentrou-se apenas nas pseudopalavras e, assim, somente os dados referentes a esses estímulos foram analisados. É procedimento padrão na tarefa de Reicher-Wheeler adaptar o tempo de exposição, de forma a obter precisão próxima de 75% para cada participante ou excluir os que apresentem precisão muito elevada ou muito baixa (Johnston, 1978; Paap et al., 2000; Reicher, 1969; Wheeler, 1970). Assim, como neste estudo o tempo de exposição dos estímulos foi fixado em 50 ms, optou-se por excluir os participantes que apresentaram efeito de teto ou de piso. Levando em conta que o nível de chance nessa tarefa é de 50%, foram excluídos das análises os dados de 12 pessoas que apresentaram porcentagem de acertos maior do que 90% ou menor do que 60%. Metade deles tinha sido exposta à lista 1 e a outra parte à lista 2 e, dessa forma, os grupos continuaram balanceados. O procedimento foi bem sucedido para os objetivos da tarefa, já que os participantes restantes apresentaram precisão média de 78,4% (desvio padrão de 8,13%; assimetria de -0,26 e curtose de -1,42) e gastaram, em média, 1,2 s para responder. De acordo com o teste de Kolmogorov-Smirnov (Z=0,687, p>0,7), pode-se considerar que a porcentagem de acertos apresentou distribuição normal. A Tabela 1 indica a média da porcentagem de acertos dos participantes para as pseudopalavras que corresponderam à manipulação experimental de N e TLN.
Para analisar uma possível interação entre o fator 'lista' e os fatores experimentais 'N' e 'TLN', realizou-se uma análise de variância incluindo o primeiro como um fator entre sujeitos e os demais como intrasujeitos, tendo como variável dependente a porcentagem de acertos dos participantes. O efeito principal do fator 'lista' não foi significativo, e nem as interações entre ele e N ou TLN (todos os valores p>0,25).
Observou-se um efeito facilitador estatisticamente significante de N [F(1,20)=5,19 e p=0,034], sendo as pseudopalavras com muitos vizinhos ortográficos reconhecidas com porcentagem de acertos 9,85% maior do que as sem vizinhos ortográficos. Também se observou um efeito facilitador estatisticamente significante de TLN [F(1,20)=6,88 e p=0,016], sendo as pseudopalavras com um vizinho transposto reconhecidas com uma porcentagem de acertos 7,32% maior do que as pseudopalavras sem vizinhos transpostos. A interação entre N'e TLN não foi estatisticamente significante (p>0,8).
É importante ressaltar que, por precaução, os dados também foram analisados considerando-se os escores dos 12 participantes excluídos e que isso não alterou o padrão dos resultados, ou seja, os efeitos estatisticamente significantes continuaram significantes, e aqueles que não foram significantes assim se mantiveram. No entanto, optou-se pela apresentação das análises, com a exclusão dos participantes que apresentaram efeitos de teto ou de piso, para garantir maior comparabilidade com os outros estudos realizados com a tarefa de Reicher-Wheeler.
Discussão
A ausência de interação entre o fator 'lista' e 'N' e 'TLN' indica que o efeito dessas variáveis é geral e pode ser generalizado para as diferentes amostras de pseudopalavras empregadas no estudo. Já a ausência de interação entre as variáveis N e TLN demonstra que elas têm efeitos independentes no reconhecimento de letras, o que se coaduna com outros dados psicolinguísticos, já que Justi e Justi (2008) demonstraram que nas palavras do português brasileiro a correlação entre N e TLN é de apenas 0,10.
Considerando-se que os participantes gastaram, aproximadamente, apenas 1 s para responder, e que diferentes tipos de estímulos foram utilizados para dificultar a formulação de estratégias de resposta, pode-se dizer que é pouco provável que eles tenham utilizado estratégias inferenciais sofisticadas na hora de responder. Assim, a explicação mais provável para o efeito facilitador de N refere-se à ativação enviada à letra-alvo via mecanismo de retroalimentação por parte das representações ortográficas pré-ativadas das palavras, conforme proposto por diversos modelos de reconhecimento visual de palavras (Coltheart et al., 2001; Grainger & Jacobs, 1996; McClleland & Rumelhart, 1981; Whitney & Lavidor, 2005). No caso de TLN, a ideia é a de que o mecanismo de retroalimentação também esteja presente, só que agora é apenas a representação ortográfica de uma palavra que envia a ativação à letra-alvo. Isso implica em que o efeito facilitador de N, nesse caso, deva ser mais forte que o de TLN, afinal são mais fontes retroalimentando a letra-alvo no caso de N do que no caso de TLN. Essa ideia tem respaldo nos dados se considerar-se que o efeito facilitador de N foi maior do que o efeito de TLN (9,85 e 7,32%, respectivamente). No entanto, como as palavras que tinham muitos vizinhos ortográficos, em média, contavam com quatro vizinhos ortográficos e as palavras com vizinhos transpostos tinham apenas um vizinho transposto, é provável que TLN gere representações ortográficas mais fortes no léxico, já que o efeito de N não foi quatro vezes maior do que o efeito de TLN.
Uma possível explicação para que a representação ortográfica gerada por um vizinho transposto (TLN) seja mais forte do que a de um vizinho ortográfico (N) pode ser derivada do modelo SERIOL, desenvolvido por Whitney (2001; Whitney & Lavidor, 2005; Whitney & Cornelissen, 2008). Nesse modelo, a ordem das letras nos estímulos é codificada apenas de forma relativa por meio de unidades ortográficas que Grainger e Whitney (2004) chamaram de bigramas abertos. No caso, diante do estímulo 'bola', seriam ativados os seguintes bigramas abertos: 'bo', 'bl', 'ba', 'ol', 'oa', 'la'. Dessa forma, uma pseudopalavra como 'bloa', formada pela transposição de duas letras da palavra 'bola', compartilha com essa 83,33% de seus bigramas abertos (os bigramas abertos 'bl', 'bo', 'ba', 'la' e 'oa'), enquanto uma pseudopalavra como 'bova', formada pela substituição de uma das letras da palavra 'bola', compartilha apenas 50% de seus bigramas abertos ( 'bo', 'ba' e 'oa'). Como, no modelo SERIOL, os bigramas abertos alimentam diretamente a representação ortográfica das palavras no léxico (Whitney & Cornelissen, 2008), pode-se compreender porque um vizinho transposto gera representações ortográficas mais fortes, já que compartilha com o estímulo-alvo mais bigramas abertos do que um vizinho ortográfico comum.
Uma explicação alternativa para a ausência de um efeito facilitador ainda maior de N em relação ao de TLN, e que pode mais facilmente ser acomodada no arcabouço de modelos diferentes do SERIOL (Coltheart et al., 2001; Grainger & Jacobs, 1996; McClleland & Rumelhart, 1981), é argumentar que alguns dos vizinhos ortográficos pré-ativados podem ser vizinhos ortográficos entre si e, dessa forma, podem se inibir mutuamente, reduzindo a quantidade de ativação enviada à letra-alvo via mecanismo de retroalimentação. De fato, essa é uma possibilidade quando a maioria dos vizinhos ortográficos de uma pseudopalavra provém de mudanças em uma mesma posição, como é o caso da pseudopalavra 'escumo' que tem como vizinhas ortográficas as palavras 'escudo', 'escuro', 'escuso' e 'escuto' que são todas vizinhas ortográficas umas das outras. Considerando essa possibilidade, procurou-se identificar se a maioria das pseudopalavras utilizadas nesse estudo tinha vizinhos formados em apenas uma posição. No entanto, constatou-se que apenas 3 das 36 pseudopalavras com vizinhos ortográficos tinham vizinhos formados em apenas uma posição, sendo que, na maioria das vezes (21), os vizinhos ortográficos das pseudopalavras eram formados em três ou mais posições. Assim, a hipótese de que o efeito de N possa ter sido decrescido devido à inibição mútua dos vizinhos ortográficos das pseudopalavras é pouco provável, considerando-se as pseudopalavras empregadas nesse estudo.
É importante considerar que o fato das medidas N e TLN terem apresentado efeito facilitador significativo e independente no reconhecimento de letras é um indício de que ambas são bons índices do grau de similaridade ortográfica do estímulo-alvo para com outras palavras da língua, e também de que há pouca sobreposição entre essas medidas. Isso, se por um lado indica que os modelos de reconhecimento visual de palavras que são inspirados pela arquitetura do modelo AIC (McClleland & Rumelhart, 1981) estão no caminho certo (Coltheart et al., 2001; Grainger & Jacobs, 1996), por outro indica que, com exceção do modelo SERIOL (Grainger & Whitney, 2004), têm que desenvolver uma forma de acomodar os efeitos de TLN, já que essa variável apresentou efeitos facilitadores significativos no reconhecimento de letras, independente do número de vizinhos ortográficos das pseudopalavras.
Por fim, até onde se sabe, esse é o primeiro estudo a investigar os efeitos de N e de TLN em uma tarefa de Reicher-Wheeler realizada com falantes do português brasileiro e também o primeiro a analisar o efeito de TLN nessa tarefa. Esse é um aspecto importante porque Whitney e Lavidor (2005) levantaram a possibilidade de que em línguas nas quais os mapeamentos grafema-fonema e fonema-grafema são mais previsíveis, o nível de retroalimentação entre as representações ortográficas das palavras e suas letras componentes seria menor, porque a representação ortográfica das letras nessas línguas seria diretamente previsível a partir da fonologia, não necessitando muito de conexões diretas com as representações ortográficas das palavras. Como, no presente estudo, N e TLN apresentaram efeito facilitador significante no reconhecimento de letras, pode-se dizer que o mecanismo de retroalimentação entre palavras e letras é funcional mesmo em línguas como o português brasileiro, cujos mapeamentos grafema-fonema e fonema-grafema são bastante previsíveis. Cabe ressaltar, também, que o presente estudo replicou o efeito facilitador de N para pseudopalavras na tarefa de Reicher-Wheeler observado por Grainger e Jacobs (2005), mesmo tendo adotado um limite de tempo para as respostas e o uso de diferentes tipos de estímulos de forma a dificultar o uso de estratégias inferenciais sofisticadas por parte dos participantes.
Referências
Acha, J., & Perea, M. (2008). The effect of neighborhood frequency in reading: evidence with transposed-letter neighbors. Cognition, 108, 290-300. [ Links ]
Andrews, S. (1989). Frequency and neighborhood effects on lexical access: activation or search? Journal of Experimental Psychology: Learning, Memory, and Cognition, 15, 802-814. [ Links ]
Andrews, S. (1996). Lexical retrieval and selection processes: effects of transposed-letter confusability. Journal of Memory and Language, 35, 775-800. [ Links ]
Arduino, L. S., & Burani, C. (2004). Neighborhood effects on nonword visual processing in a language with shallow orthography. Journal of Psycholinguistic Research, 33, 75-95. [ Links ]
Clark, H. H. (1973). The language-as-fixed-effect fallacy: a critique of language statistics in psychological research. Journal of Verbal Learning and Verbal Behavior, 12, 335-359. [ Links ]
Coltheart, M., Davelaar, E., Jonasson, J. T., & Besner, D. (1977). Access to the internal lexicon. In S. Dornic (Ed.), Attention and performance VI, (pp. 535-555). Hillsdale, NJ: Lawrence Erlbaum Associates. [ Links ]
Coltheart, M., Rastle, K., Perry, C., Langdon, R., & Ziegler, J. (2001). DRC: a dual route cascaded model of visual word recognition and reading aloud. Psychological Review, 108, 204-256. [ Links ]
Davis, C. J. (2005). N-watch: a program for deriving neighborhood size and other psycholinguistic statistics. Behavior Research Methods, 37, 65-70. [ Links ]
Forster, K. I., & Forster, J. C. (2003). DMDX: a windows display program with millisecond accuracy. Behavior Research Methods, Instruments and Computers, 35, 116-124. [ Links ]
Grainger, J., & Jacobs, A. M. (1994). A dual read-out model of word context effects in letter perception: further investigations of the word superiority effect. Journal of Experimental Psychology: Human Perception and Performance, 20, 1158-1176. [ Links ]
Grainger, J., & Jacobs, A. M. (1996). Orthographic processing in visual word recognition: a multiple read-out model. Psychological Review, 103, 518-565. [ Links ]
Grainger, J., & Jacobs, A. M. (2005). Pseudoword context effects on letter perception: the role of word misperception. European Journal of Cognitive Psychology, 17, 289-318. [ Links ]
Grainger, J., O'Reagan, J. K., Jacobs, A. M., & Segui, J. (1989). On the role of competing word units in visual word recognition: the neighborhood frequency effect. Perception & Psychophysics, 45, 189-195. [ Links ]
Grainger, J., & Whitney, C. (2004). Does the huamn mnid raed wrods as a wlohe? Trends in Cognitive Sciences, 8, 58-59. [ Links ]
Huntsman, L. A., & Lima, S. D. (2002). Orthographic neighbors and visual word recognition. Journal of Psycholinguistic Research, 31, 289-306. [ Links ]
Johnston, J. C. (1978). A test of the sophisticated guessing theory of word perception. Cognitve Psychology, 10, 123-153. [ Links ]
Justi, F. R., & Justi, C. (2008). As estatísticas de vizinhança ortográfica das palavras do português e do inglês são diferentes? Psicologia em Pesquisa, 2, 61-73. [ Links ]
Justi, F. R. R., & Pinheiro, A. M. V. (2006). O efeito de vizinhança ortográfica no português do Brasil: acesso lexical ou processamento estratégico. Interamerican Journal of Psychology, 40, 275-288. [ Links ]
Justi, F. R. R., & Pinheiro, A. M. V. (2008). O efeito de vizinhança ortográfica em crianças brasileiras: estudo com a tarefa de decisão lexical. Interamerican Journal of Psychology, 42, 559-569. [ Links ]
Justi, F. R. R., & Roazzi, A. (2012). Efeitos de vizinhança ortográfica no português brasileiro: um estudo com a tarefa de identificação perceptual. Psicologia: Reflexão e Crítica, 25, 301-310. [ Links ]
Laxon, V., Gallagher, A., & Masterson, J. (2002). The effects of familiarity, orthographic neighbourhood density, letter-length and graphemic complexity on children's reading accuracy. British Journal of Psychology, 93, 269-287. [ Links ]
McClleland, J., & Rumelhart, D. (1981). An interactive activation model of context effects in letter perception: Pt. 1, an account of basic findings. Psychological Review, 88, 375-407. [ Links ]
Paap, K. R., Johansen, L. S., Chun, E., & Vonnahme, P. (2000) Neighborhood frequency does affect performance in the Reicher task: encoding or Decision? Journal of Experimental Psychology: Human Perception and Performance, 26, 1691-1720. [ Links ]
Perea, M., Carreiras, M., & Grainger, J. (2004). Blocking by word frequency and neighborhood density in visual word recognition: a task-specific response criteria account. Memory & Cognition, 32, 1090-1102. [ Links ]
Raaijmakers, J. G. W., Schrijnemakers, J. M. C., & Gremmen, F. (1999). How to deal with "the language-as-fixed-effect fallacy": common misconceptions and alternative solutions. Journal of Memory and Language, 41, 416-426. [ Links ]
Reicher, G. M. (1969). Perceptual recognition as a function of meaningfulness of stimulus material. Journal of Experimental Psychology, 81, 275-280. [ Links ]
Slattery, T. J. (2009). Word misperception, the neighbor frequency effect, and the role of sentence context: evidence from eye movements. Journal of Experimental Psychology: Human Perception and Performance, 35, 1969-1975. [ Links ]
Wheeler, D. (1970). Processes in word recognition. Cognitive Psychology, 1, 59-85. [ Links ]
Whitney, C. (2001) How the brain encodes the order of letters in a printed word: the SERIOL model and selective literature review. Psychonomic Bulletin & Review, 8, 221-243. [ Links ]
Whitney, C., & Cornelissen, P. L. (2008) SERIOL reading. Language and Cognitive Processes, 23, 143-164. [ Links ]
Whitney, C., & Lavidor, M. (2005) Facilitative orthographic neighborhood effects: the SERIOL model account. Cognitive Psychology, 51, 179-213. [ Links ]
 Endereço para correspondência:
Endereço para correspondência:
Cláudia Nascimento Guaraldo Justi
Departamento de Psicologia – Universidade Federal de Juiz de Fora
Rua José Lourenço Kelmer, s/n
CEP 36036-900 – Juiz de Fora/MG
E-mail: coglin.gp@gmail.com
Recebido em 22/02/2012
Revisto em 27/08/2012
Aceito em 22/10/2012
* Esse trabalho integra uma série de estudos que deu origem à tese de doutorado do autor Francis Ricardo dos Reis Justi, que recebeu bolsa de estudos do Conselho Nacional de Desenvolvimento Científico e Tecnológico (CNPq).
1 Conjunto de letras que segue as regras fonotáticas da língua, mas não tem significado. Por exemplo: no caso do português brasileiro, 'capena' seria uma pseudopalavra.

{kind=link}