










Serviços Personalizados
Journal

artigo
 Português (pdf)
Português (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
Indicadores
Compartilhar

 Permalink
PermalinkPsicologia em Revista
versão impressa ISSN 1677-1168
Psicol. rev. (Belo Horizonte) vol.20 no.3 Belo Horizonte set. 2014
https://doi.org/DOI-10.5752/P.1678-9523.2014V20N3P566
ARTIGOS
DOI - 10.5752/P.1678-9523.2014V20N3P566
Efeitos da aprendizagem da relação entre palavra ditada e figura sobre a nomeação de figuras: relações entre o ouvir e o falar
Learning the effects of the relationship between the dictated word and naming figures on the picture: relationship between listening and speaking
Efectos del aprendizaje de la relación entre la palabra dictada y figura sobre el nombramiento de figuras: las relaciones entre escuchar y hablar
Carolina Antonelli dos Santos*; Anderson Jonas das Neves**; Mariana Girotto Carvalho da Silva***; Ana Claudia Moreira Almeida Verdu****
Resumo
Investigações sobre linguagem têm explorado possíveis relações entre ouvir e falar, bem como se aprender uma relação entre palavra ditada e objeto (ouvir) seria condição suficiente para emergência da nomeação desse objeto (falar). Este estudo verificou se, após o ensino de relações condicionais auditivovisuais entre palavra ditada e figura, ocorreria a nomeação dessas figuras em seis escolares com comprometimentos acadêmicos e de linguagem que frequentavam um atendimento educacional especializado. O procedimento constituiu-se de blocos de tarefas de seleção de figuras em tentativas de emparelhamento segundo modelo, seguidas de testes de nomeação de figuras. Os resultados indicam que a maioria dos participantes aprendeu novas relações entre palavras ditadas e figuras, todavia esse ensino não garantiu que nomeassem imediatamente as figuras. Obteve-se nomeação após sucessivas exposições às tarefas de seleção e de nomeação. Esses resultados demonstram que condições sob as quais se aprende a falar novas palavras podem não depender exclusivamente do reconhecimento auditivo.
Palavras-chave:Reconhecimento auditivo. Nomeação. Ensino.
Abstract
Investigations about language have explored possible relations between listening and speaking, as well as the learning relation between the dictated word and object (listener) would be a sufficient condition for the emergence of naming this object (speak). This study examined whether, after auditoryvisual relations conditional teaching between dictated word and figure, would occur in the naming of these pictures, in six students with academic and language impairment, who frequented specialized educational services. A procedure of block task was established, a selection of figures in matching trials to samples, followed up by naming tests. The results indicate that most participants learned new relations between dictated words and figures, however this learning does not guaranteed that they immediately nominate the figures; naming was obtained after successive exposures to the tasks of selection and naming. These results demonstrate that the conditions under which learning to speak new words cannot depend exclusively on auditory recognition.
Keywords:Auditory recognition. Naming. Teaching.
Resumen
Las investigaciones sobre lenguaje han explorado las posibles relaciones entre escuchar y hablar, así como si el aprendizaje de una relación entre la palabra dictada y el objeto (escuchar) sería una condición suficiente para la emergencia del nombramiento de este objeto (hablar). Este estudió examinó si, después de enseñar relaciones condicionales auditivo-visuales entre la palabra dictada y la figura, ocurriría el nombramiento de las figuras, en seis estudiantes con dificultades académicas y de lenguaje, que frecuentan los servicios de educación especial. El procedimiento se constituyó en bloques de tareas de selección de figuras en tentativas de emparejamiento según modelo, seguido de pruebas de nombramiento de las figuras. Los resultados indican que la mayoría de los participantes aprendieron nuevas relaciones entre palabras dictadas y figuras, no obstante esta enseñanza no garantiza el nombramiento inmediatamente de las figuras; el nombramiento se obtuvo después de sucesivas exposiciones a las tareas de selección y nombramiento. Estos resultados demuestran que las condiciones en las que aprenden a decir nuevas palabras no dependen exclusivamente del reconocimiento auditivo.
Palabras clave:Reconocimiento auditivo. Nombramiento. Enseñanza.
Introdução
A linguagem é um dos processos mais notáveis do desenvolvimento humano (Papalia & Olds, 2000), fomentando diversas áreas da ciência à investigação dos elementos de sua gênese, estabelecimento e manutenção nos indivíduos e na comunidade verbal (Coseriu, 1993). Entre as múltiplas ciências que corroboram nas pesquisas sobre a linguagem (tais como a Pedagogia, Fonoaudiologia, Audiologia e Linguística), a Psicologia se destaca por suas contribuições teórico-metodológicas na identificação e descrição das variáveis e processos psicológicos relacionados à formação, significação e desenvolvimento dos repertórios linguísticos. Uma das maneiras de estudar linguagem na Psicologia é considerá-la como um comportamento cuja consequência é mediada por um ouvinte especialmente treinado por uma comunidade verbal, sendo que a aquisição, manutenção e extinção deste seguem os mesmos princípios operantes (Barros, 2003; Skinner, 1978). Assim, princípios básicos do comportamento, como modelagem, discriminação, extinção e generalização, são aplicáveis também ao comportamento verbal (Córdova, Lage & Ribeiro, 2007; Skinner, 1978).
Considerando essa proposição, o indivíduo que emite o comportamento verbal é designado de falante, sendo o ambiente que o comportamento do falante modifica é o ambiente social, isto é, o ouvinte. O ouvinte, ao ser especialmente treinado pela comunidade verbal, medeia as consequências do comportamento do falante. Embora os comportamentos de falante e de ouvinte se interrelacionem, essas competências são aprendidas sob condições de ensino distintas e constituem-se em repertórios independentes (Baum, 1999; Skinner, 1978).
Baseado nas variáveis controladoras da resposta verbal, Skinner (1978) categorizou os comportamentos de falante em sete operantes verbais elementares: tato (controlado por estímulos não verbais), mando (controlado por variáveis motivacionais), ecoico, textual, cópia, ditado e intraverbal (controlados por estímulos verbais). O fato de uma criança aprender a emitir esses operantes verbais sob uma circunstância não implica que ele será emitido em outra, com outra função. Uma criança que aprende a emitir o tato "bolo" diante do alimento bolo pode não demonstrar um operante verbal de mando do tipo "quero bolo" (ou simplesmente "bolo") quando estiver faminta e, ou, quiser comer um pedaço do bolo, sendo esta uma evidência de que os operantes verbais são funcionalmente independentes.
A maior parte dos estudos sobre independência funcional entre operantes verbais estabelece uma topografia de resposta com uma função específica (mando, tato, ecoico, textual, cópia, ditado ou intraverbal) e monitora os efeitos desse ensino sobre a emergência (ou não) da mesma topografia verbal sob controle de variáveis que definem outros operantes verbais (Hall & Sundberg, 1987; Lamarre & Holland, 1985; Twyman, 1996).
Dado que o enfoque deste trabalho está sobre quais são relações estabelecidas entre o ouvir e o falar (especificamente o nomear), será descrito o operante tato, visto que a nomeação é uma extensão do tato (para uma discussão mais aprofundada, ver Alves & Ribeiro, 2007; Barros, 2003; Matos, 1991; Skinner, 1978). O tato é definido como um tipo de comportamento verbal emitido na presença de estímulos não verbais, o qual é mantido por reforço social. Os estímulos discriminativos que o antecedem podem ser objetos, pessoas, acontecimentos, sensações, lembranças ou mudanças no campo sensorial do falante (visual, auditivo, tátil, proprioceptivo, interoceptivo, entre outros) (Matos, 1991). Esse operante é responsável pela descrição do mundo e fornece informações ao ouvinte sobre quais eventos o falante está em contato (Matos, 1991; Skinner, 1978;).
O tato, como operante verbal, supõe uma identidade funcional entre a resposta e os eventos que a antecederam, sobretudo para o ouvinte que compartilha desse quadro de equivalências (Matos, 1991). Um exemplo demonstrado por Alves e Ribeiro (2007, p. 290) remete ao fato de que, "na presença de um cachorro, o falante pode emitir a resposta verbal 'Isto é um cachorro' e receber reforçadores generalizados como a atenção e/ou verbais, 'isto mesmo, você está certo'".
Wraikat, Sundberg e Michael (1991) acrescentam que repertórios verbais podem ser definidos a partir de contingências estabelecidas para cada operante e pela especificidade da resposta emitida, sendo classificados em comportamento baseado na seleção e comportamento baseado em topografia, ou ainda, de linguagem receptiva e linguagem expressiva, respectivamente. A linguagem expressiva abrange os comportamentos baseados na topografia, os quais ficam sob controle de estímulos discriminativos específicos (contingências de discriminação simples) e requerem que a topografia da resposta demonstre correspondência estrutural ou arbitrária com as convenções estabelecidas pela comunidade verbal. Quando a criança, na presença do animal gato, vocaliza "gato", expressa um operante verbal que tem correspondência arbitrária com o evento/coisa (no caso, o animal gato), e está, sob controle, desse mesmo estímulo não verbal (animal gato), emitindo, nesse caso, um tato expressivo.
Já os comportamentos baseados em seleção podem envolver contingências de discriminação condicional, exigindo uma varredura visual dos estímulos e que haja um controle condicional do estímulo (estímulo modelo) em relação à resposta de selecionar ou apontar um estímulo entre outros disponíveis para a escolha (estímulo de comparação), podendo funcionar como um substitutivo oral. Um claro exemplo desse processo no âmbito da linguagem remete à condição em que um adulto fala ";onde está a bola?" e a criança seleciona o objeto bola na caixa de brinquedos, eliminando os demais estímulos presentes (que poderiam ser o carrinho, a boneca ou o pião), em uma tarefa de reconhecimento auditivo (ou uma espécie de tato receptivo). Especificamente para o nosso estudo, os repertórios receptivos (comportamento baseado em seleção) podem oferecer critérios operacionais de: a) quais relações o indivíduo estabelece entre os estímulos verbais e não verbais (tais como na seleção de figura diante de uma palavra ditada); e b) identificar as habilidades de ouvinte competente, capaz de reconhecer estímulos auditivos e associá-los com aos respectivos eventos referentes, constituindo-se em uma espécie de reconhecimento auditivo (para leitura mais aprofundada, ver Almeida-Verdu, Matos, Battaglini, de Souza & Bevilacqua, 2012; Dugdale & Lowe, 1990; Ferrari, Giacheti & de Rose, 2009; Polson & Parsons, 2000), o que implicará na forma com que ocorre a mediação das consequências para o comportamento do falante.
As relações entre o ouvir e o falar têm levantado problematizações e hipóteses teórico-metodológicas importantes na literatura (Bandini, Sella, Postalli, Bandini & Silva, 2012; Skinner, 1978; Stemmer, 1992). A aprendizagem de repertórios de ouvinte seria condição necessária e suficiente para a emergência de habilidades de falante, especialmente o nomear, estabelecendo-se uma relação de dependência funcional entre ouvir e falar (Stemmer, 1992). Por meio de sucessivas exposições aos eventos ostensivos, que são condições sob as quais ocorre pareamento entre estímulos não verbais e estímulos verbais (que referenciam o estímulo não verbal), o indivíduo seria capaz de responder, de forma correta, como ouvinte, e sua produção verbal poderia ser estabelecida, derivando em aprendizagem do comportamento de falante (Vichi, Nascimento & Souza, 2012). Desse modo, após longa história de exposição à palavra ditada "boneca" com o objeto boneca (evento ostensivo), o indivíduo poderia selecionar o objeto boneca quando alguém lhe solicita verbalmente a boneca (repertório de ouvinte), bem como seria capaz de vocalizar "boneca" diante do referido objeto (comportamento de falante, no caso, um tato).
Se o ouvir é condição importante para o falar, de que maneira a aprendizagem receptiva (ouvir) interfere na aprendizagem expressiva (falar) de palavras novas? Os estudos de Ferrari et al. (2009) e de Almeida-Verdu et al. (2012) investigaram empiricamente essa questão. Ambos analisaram a relação entre esses desempenhos em participantes com surdez, sendo que, no primeiro caso, a tecnologia aplicada na reabilitação era o aparelho de aplicação sonora individual (AASI) e, no segundo caso, o implante coclear (IC).
Tanto Ferrari et al. (2009) quanto Almeida-Verdu et al. (2012) adotaram um delineamento de ensino de discriminações condicionais auditivo-visuais em que, após a apresentação de uma palavra convencional ditada, a tarefa do participante era selecionar a figura que correspondia ao modelo, entre três disponíveis (matching to sample). Após 100% de acertos nas tarefas de ensino, o desempenho em nomeação de figuras era avaliado. Na pesquisa de Ferrari et al. (2009), as tarefas de seleção e nomeação de figuras convencionais foram sistematicamente repetidas até que o participante apresentasse porcentagens de acertos mais elevadas nas vocalizações, durante a nomeação de figuras. Em ambas as pesquisas, os participantes aprenderam, em poucas tentativas, as relações ensinadas entre palavras ditadas e figuras, contudo houve grande variabilidade de desempenho nas tarefas de nomeação de figuras, o que poderia evidenciar a independência funcional entre ouvir e falar.
Bandini et al. (2012) também propuseram um estudo com delineamento semelhante ao de Ferrari et al. (2009) e Almeida-Verdu et al. (2012) com nove crianças escolares, porém com desenvolvimento típico e no qual os estímulos experimentais foram palavras não convencionais (palavras sem sentido) e figuras abstratas. Ao atingir 100% de acertos nas tarefas de seleção, este era exposto ao teste de nomeação de figuras. Os resultados desse estudo apontaram que os participantes apresentaram grande variabilidade de desempenho nas tarefas de seleção de figuras, bem como nos testes de nomeação, sendo que, no último, houve variação significativa entre as sucessivas vocalizações que os participantes emitiam, aproximando-se gradativamente, do comportamento-alvo, indicando que as relações estabelecidas entre o ouvir e o falar ainda requerem investigações.
Na direção dessas investigações, este estudo replicou as pesquisas de Ferrari et al. (2009) e Almeida-Verdu et al. (2012) com população diferente a dos estudos anteriores (escolares com déficits acadêmicos e de linguagem), investigando se a exposição a tarefas de seleção de figuras mediante palavras ditadas seria condição suficiente para emergência de nomeação precisa de figuras para essa população.
Método
Participantes
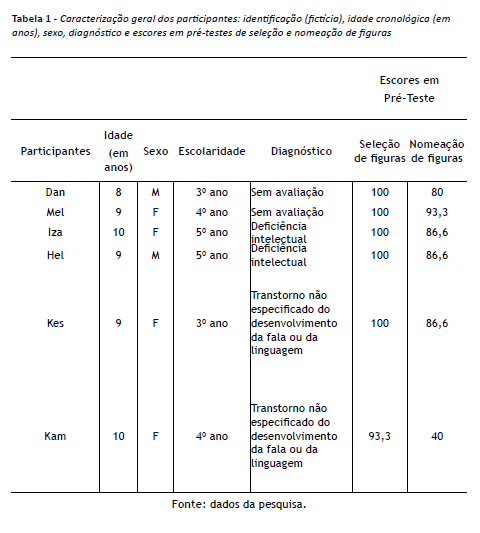
Participaram deste estudo seis crianças escolares, com idades entre 7 e 10 anos, que frequentavam o serviço de apoio pedagógico especializado, sendo duas crianças sem diagnóstico específico, duas crianças com diagnóstico de deficiência intelectual e duas crianças diagnosticadas com transtorno não especificado do desenvolvimento da fala ou da linguagem. A tabela 1 apresenta uma caracterização dos participantes. Antes de serem expostos às atividades de ensino e testes deste estudo, os participantes foram avaliados em tarefas de seleção de figuras e nomeação de figuras, que forneceram medidas comportamentais do repertório verbal inicial do participante. O desempenho dos participantes na avaliação inicial de seleção de figuras ficou entre 86,6% e 100%, e, na nomeação de figuras, ficou entre 40% e 93,3%, demonstrando serem bons ouvintes. Este estudo compõe um projeto amplo aprovado pelo Comitê de Ética em Pesquisa da Faculdade de Ciências de Bauru/Universidade Estadual Paulista “Julio de Mesquita Filho” (FC/Unesp-Bauru), sob o parecer número 13653/46/01/12.
Equipamentos e situação
As sessões foram conduzidas na escola dos participantes, especificamente na sala de Informática e supervisionadas pela professora responsável do Atendimento Educacional Especializado (AEE). Um microcomputador foi disponibilizado para apresentação das tarefas de seleção e nomeação de figuras. O software "Aprendendo a Ler e a Escrever em Pequenos Passos"– ProgLeit® (Rosa Filho, Rose, Souza, Hanna & Fonseca, 1998) gerenciava a apresentação das tentativas e registrava as respostas dos participantes. Os estímulos envolvidos nas tarefas eram de natureza auditiva (palavras ditadas) e visual (respectivas figuras). Cada conjunto de tarefas era composto por número variável de figuras e de palavras ditadas, sendo o conjunto 1 constituído pelos estímulos "tatu", "vaca", "apito", "boca", "bolo";, "luta" e "lata"; já o conjunto 2 abarcava os estímulos "mato", "mapa", "pato", "vale", "tomate", "toco", "pipa" e "tubo"; e o conjunto 3 era composto pelos estímulos "bico";, "cavalo", "lobo", "fita", "luva", "mala", "muleta" e "vovô". Os treinos de seleção de figuras envolviam a apresentação concomitante de uma dada palavra ditada do conjunto e de três figuras na tela do computador. Já nos testes de nomeação, exibia-se apenas a figura que o participante deveria nomear.
Procedimentos
O procedimento consistiu em expor os participantes a um ensino sistemático de seleção de figuras diante da palavra ditada e testar a nomeação de figuras, com três conjuntos de estímulos, considerando que, em cada conjunto, havia pelo menos um estímulo desconhecido pela criança (havia apresentado erro na avaliação inicial) entre muitos conhecidos por esta (havia apresentado acerto na avaliação inicial).
Tentativas de seleção de figuras: consistiam em exibir três figuras, dispostas linearmente na porção inferior da tela, como alternativas de escolha e simultaneamente apresentar, por meio dos alto-falantes do computador, a instrução sonora "Aponte... (nome da figura)". A tarefa do participante era selecionar a figura que correspondesse à palavra ditada. A posição da alternativa correta foi aleatorizada em sucessivas tentativas, a fim de evitar escolhas baseadas exclusivamente na posição. O ensino de seleção de um conjunto de estímulos era encerrado quando o participante apresentasse 100% de acertos em um bloco de tentativas e então este era exposto ao teste de nomeação de figuras. Caso o participante não tivesse 100% de acertos, o bloco de tarefas era apresentado novamente. No ensino, houve consequências programadas para acerto e erro, no qual respostas consideradas corretas eram consequenciadas por efeitos sonoros e as respostas incorretas seguidas da apresentação da próxima tentativa. O registro das respostas de seleção via mouse eram registradas automaticamente pelo software.
Teste de nomeação de figuras: consistia em apresentar uma figura na tela do computador, seguida da instrução "o que é isso?". Diferentemente das tarefas de seleção, as respostas de nomeação do participante eram digitadas pelo examinador no momento em que o participante realizava essa tarefa, sendo então computados acertos ou erros, que constituiriam o relatório da sessão gerado pelo ProgLeit®. O teste de nomeação era encerrado quando o participante apresentasse 100% de acertos em tentativas de nomeação de um conjunto e então era exposto ao novo treino de seleção e aos testes de nomeação, com estímulos de outro conjunto.
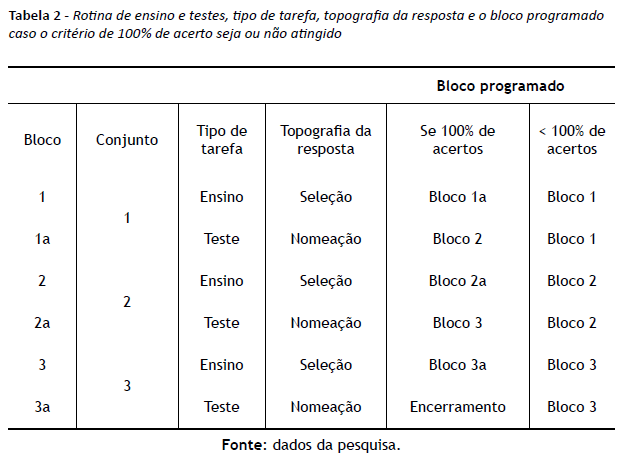
O procedimento iniciava com a exposição a um bloco de tentativas do treino de seleção de figuras com as palavras do conjunto 1; se o desempenho do participante fosse de 100% de acertos, ele era exposto ao teste de nomeação das figuras do conjunto 1. Após a obtenção de 100% de acertos em nomeação com figuras do conjunto 1, o mesmo procedimento era conduzido com estímulos dos conjuntos 2 e 3. A tabela 2 apresenta a rotina de apresentação de blocos de ensino e testes com os estímulos dos três conjuntos, bem como quais seriam os blocos expostos aos participantes, caso obtivessem ou não 100% de acertos.
Resultados
A figura 1 apresenta o desempenho dos participantes no ensino de seleção de figuras (barras pretas) e no teste de nomeação de figuras (barras cinza) com estímulos dos conjuntos utilizados no procedimento. As barras representam a porcentagem de acertos obtida em um bloco de ensino ou teste.
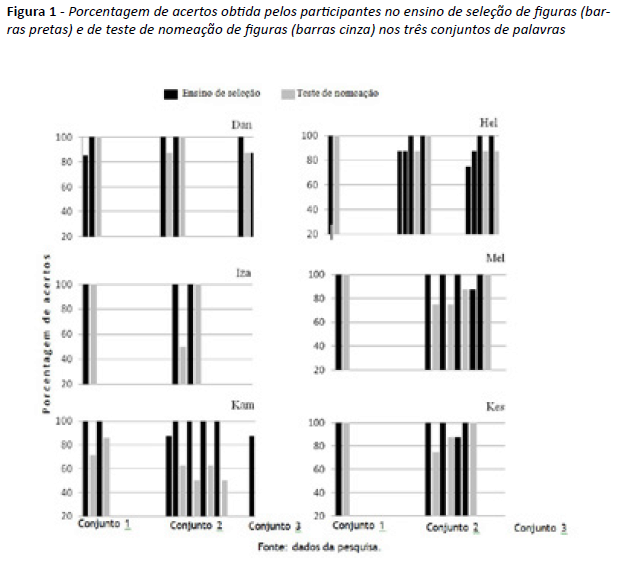
De modo geral, os resultados demonstram que, o ensino de seleção de figuras diante da palavra ditada desconhecida pelos participantes e contextualizado com palavras conhecidas permitiu a aquisição rápida (com poucas exposições) do reconhecimento dessa palavra por todos os participantes. Após terem demonstrado o reconhecimento auditivo a partir das tarefas de seleção, os participantes também demonstraram a nomeação de figuras. Todos os participantes aprenderam a selecionar a figura após palavra ditada com os três conjuntos de estímulos (embora haja alguma variação na quantidade de exposição necessária aos blocos de ensino, especificamente de 1 a 2 exposições para o conjunto 1; de 2 a 5 exposições para conjunto 2; e de 1 a 5 exposições para o conjunto 3) e nomearam a maioria das figuras, embora apresentado variabilidade nos desempenhos em nomeação.
De acordo com a figura 1, quatro participantes (Hel, Iza, Kes e Mel) necessitaram de apenas uma exposição ao ensino de relações auditivo-visuais para obterem 100% de acertos na nomeação das figuras do conjunto 1. Um participante (Dan) precisou de duas exposições ao treino para atingir o critério de 100% de acertos nas tarefas de seleção, apresentando posteriormente 100% no teste de nomeação. Um participante (Kam) precisou de duas exposições ao bloco de ensino, uma vez que não obtive 100% em nomeação de figuras na primeira exposição.
Com os estímulos do conjunto 2, dois participantes (Dan e Iza) necessitaram de duas exposições ao ensino de seleção da figura diante da palavra para que atingissem 100% de acertos no teste em nomeação de figuras. Para o participante Hel, foram apresentados sucessivamente três blocos de tentativas no ensino das relações auditivo-visuais, uma vez que não atingiu, nas duas primeiras exposições, o critério (100% de acertos na seleção de figuras) para avanço para a próxima etapa; após a terceira exposição ao ensino, este atingiu o critério (100% de acertos em seleção), demonstrando precisão (100%) em nomeação. Outra participante (Iza) não demonstrou 100% na nomeação após a primeira exposição ao ensino de relações auditivo-visuais, exigindo a repetição do bloco de ensino para que alcançasse a precisão (100% de acertos) em nomeação das figuras do conjunto 2. Kam, embora atingisse o critério dos blocos de ensino de seleção (apresentando variabilidade quanto ao número de exposições seguida de pós-testes de nomeação), demonstrou uma significativa variação na emissão da nomeação de figuras e da porcentagem de acertos próximo à linha do acaso (aproximadamente 50%); embora esse desempenho fosse insatisfatório para prosseguimento nas etapas subsequentes, optou-se pela exposição dessa participante ao terceiro conjunto. Uma participante (Kes) necessitou de quatro exposições, e outra (Mel), de cinco exposições ao treino de seleção até obter 100% de acerto no teste de nomeação.
Com estímulos do conjunto 3, para três participantes (Iza, Kes e Mel) uma única exposição ao ensino de seleção de figuras foi suficiente para que obtivessem 100% de acerto no teste de nomeação. Um participante (Hel) necessitou de três exposições, a fim de que apresentasse desempenho de 100% de acerto em nomeação. O participante Dan necessitou de quatro exposições ao treino de seleção até obter 100% de acerto no teste de nomeação de figuras, e uma participante (Kam) necessitou de duas exposições ao treino de seleção, contudo tal condição não garantiu a precisão da nomeação de Kam (aproximadamente 70% em nomeação).
O maior percentual de dificuldade dos participantes concentrou-se nas palavras do conjunto 2. As palavras que apresentaram mais erros em seleção foram: "vale" (nove ocorrências), "tubo" (oito ocorrências), "toco" (sete ocorrências); "mapa" (três ocorrências) e "tomate" (uma ocorrência). Quanto aos erros em nomeação, notou-se que cinco participantes (Dan, Iza, Kam, Kes e Mel) exibiram erros diante da figura "vale"; outros cinco participantes (Hel, Iza, Kam, Kes e Mel) apresentaram na presença da figura "tubo"; três participantes (Iza, Kam e Mel) foram diante da figura "toco"; uma participante, quando foi exibida a figura do "mapa" (Kam); e uma participante demonstrou erros ao nomear a figura "tomate" (Iza).
Discussão
O objetivo deste estudo foi avaliar se o ensino de repertórios de ouvinte (no caso, a seleção de figura mediante a palavra ditada) favoreceria a emergência de repertórios de falante, especificamente a nomeação precisa de figuras por crianças com diferentes diagnósticos e que frequentavam o serviço de atendimento educacional especializado (AEE) no ensino fundamental em suas respectivas escolas. Ainda que todos aprendessem a selecionar figuras mediante a palavra ditada e a nomear figuras com precisão, os resultados revelam uma variabilidade significativa nos desempenhos. Esses resultados replicam os achados de estudos com o mesmo propósito (Ferrari et al. 2009; Almeida-Verdu et al., 2012; Bandini et al., 2012) e indicam a sua generalidade para populações distintas (como a de escolares com déficits acadêmicos e de linguagem, empregada neste estudo).
Este trabalho tem algumas implicações. Por um lado, uma vertente de estudos sobre as relações entre o ouvir e o falar propõe que, uma vez garantida a aprendizagem ostensiva do ouvinte, tal condição possibilitaria a emergência de repertórios expressivos, sem treino explícito, configurando assim uma dependência funcional entre o ouvir e o falar (Stemmer, 1992); por outro lado, neste estudo, embora os participantes apresentassem bons desempenhos como ouvintes e tenham aprendido novas relações entre palavra ditada e figura, a nomeação dessas figuras (falar) não acompanhou o mesmo ritmo, sendo obtida após sucessivas exposições ao ensino do ouvir e teste do falar. Esses dados sugerem que a habilidade de reconhecimento auditivo isoladamente pode não oferecer condições suficientes para que o indivíduo nomeie prontamente as palavras ouvidas, sendo mais uma evidência da independência funcional entre esses repertórios (Ferrari et al., 2009; Almeida-Verdu et al., 2012; Bandini et al., 2012).
A nomeação precisa de figuras do conjunto 1 (por Hel, Iza, Mel, Kes e Jul) e do conjunto 3 (por Iza, Mel e Kes), antecedida por uma única exposição a tarefas de seleção, poderia inicialmente corroborar a hipótese de dependência funcional, já que, após o ensino das relações entre estímulos verbais (palavra ditada) e não verbais (figura), nossos participantes demonstraram, imediatamente, a nomeação precisa de figuras. Contudo esse desempenho pode ser pela familiaridade com as palavras de ensino.
Nas tarefas com palavras do conjunto 2, embora o desempenho de seleção fosse acurado, a nomeação de figuras não acompanhou o mesmo ritmo, sendo obtida após sucessivas exposições às tarefas de seleção e de nomeação. Dados semelhantes foram obtidos no estudo de Bandini et al. (2012), no qual poucas vezes os participantes demonstraram nomeação precisa após uma única exposição ao ensino; possivelmente isso seja devido ao uso de pseudopalavras.
Neste estudo, a nomeação foi obtida após sucessivas condições que alternavam ensino de seleção (ouvir) e teste de nomeação (falar). Desempenho semelhante foi observado por Anastácio-Pessan (2011), em que sucessivos pós-testes de vocalização foram intercalados com ensino de reconhecimento auditivo de figuras, de palavras e de sílabas, em seis crianças com deficiência auditiva usuárias de implante coclear. Os participantes também demonstraram emergência gradual da nomeação de figuras, e as autoras concluíram que o delineamento com sucessivos pós-testes de nomeação intercalados com cada etapa do ensino do ouvir permitiu sucessivas oportunidades de ouvir (no treino auditivo-visual) e de falar (durante as sondas), constituindo-se em um supertreino. O fato de os participantes serem expostos a sucessivas oportunidades de ouvir a palavra e selecioná-la (ensino) e depois vocalizá-la (testes) pode ter levado, ao longo de sucessivos testes, ao desempenho-alvo, por modelagem da vocalização (reforço diferencial por aproximações sucessivas). Se os participantes do estudo de Anastácio-Pessan (2011), assim como os participantes deste estudo, necessitariam de mais exposições ao ciclo ouvir e falar com os mesmos estímulos verbais do que participantes com desenvolvimento típico é um aspecto a ser explorado em novas investigações.
Podemos considerar, ainda, que a pouca familiaridade com os estímulos envolvidos, sobretudo do conjunto 2 (tubo, toco e vale) pode ter sido variável importante no ensino de seleção de figuras e nos testes de nomeação, exigindo maiores quantidades de exposição às tarefas programadas. Esses dados podem ter implicações adicionais se considerarmos os resultados de Lima, Souza, Martinez e Rocca (2010), que desenvolveram atividades recreativas de ensino da relação nome-objeto a crianças do ensino fundamental, com desenvolvimento típico, mas que estavam apresentando dificuldades na aquisição da leitura. Lima et al. (2010) verificaram os efeitos da contextualização nome-objeto sobre a aprendizagem de leitura e escrita, e seus resultados demonstraram que a aprendizagem de leitura foi mais rápida para palavras familiares.
Nossa investigação aponta a necessidade de futuros estudos sobre quais condições são necessárias e também suficientes para a emergência precisa de nomeação, propiciando o desenvolvimento de estratégias educacionais para o manejo de ensino da linguagem em populações com diferentes necessidades educacionais especiais.
Referências
Almeida-Verdu, A. C. M., Matos, F. O., Battaglini, M. P., Bevilacqua, M. C. & Souza, D. G. (2012). Desempenho de seleção e nomeação de figuras em crianças com deficiência auditiva com implante coclear. Temas em Psicologia, 20(1), 189-202. [ Links ]
Alves, C. & Ribeiro, A. F. (2007). Relações entre tatos e mandos durante a aquisição. Revista Brasileira de Terapia Comportamental e Cognitiva, 9(2), 289- 305. [ Links ]
Anastácio-Pessan, F. L. (2011). Evolução da nomeação após fortalecimento de relações auditivo-visuais em crianças com deficiência auditiva e implante coclear. (Dissertação de Mestrado). Universidade Estadual Paulista, Faculdade de Ciências, Programa de Pós-Graduação em Psicologia do Desenvolvimento e Aprendizagem, Bauru. [ Links ]
Bandini, C. S. M., Sella, A. C., Postalli, L. M. M., Bandini, H. H. M. & Silva, E. T. P. (2012). Efeitos de tarefas de seleção sobre a emergência de nomeação em crianças. Psicologia: Reflexão Crítica, 25(3), 568-577. [ Links ]
Barros, R. S. (2003). Uma introdução ao comportamento verbal. Revista Brasileira de Terapia Comportamental e Cognitiva, 5(1), 73-82. [ Links ]
Baum, W. M. (1999). Compreender o behaviorismo. (2ª ed.). Porto Alegre: Artmed. [ Links ]
Córdova, L. F., Lage, M. & Ribeiro, A. F. (2007). Relações de independência e dependência funcional entre os operantes verbais mando e tato com a mesma topografia. Revista Brasileira de Análise do Comportamento, 3(2), 279-298. [ Links ]
Coseriu, E. (1993). Do sentido do ensino da língua literária. Confluência, 5, 29-47. [ Links ]
Dugdale, N. & Lowe, C. F. (1990). Naming and stimulus equivalence. In D. E. Blackman & H. Lejueune (Orgs.), Behavior analysis in theory and practice: contributions and controversies. (pp. 115-138). Brighton: Lawrence Erlbaum Associates. [ Links ]
Ferrari, C., Giacheti, C. M. & Rose, J. C. (2009). Procedimentos de emparelhamento com o modelo e possíveis aplicações na avaliação de habilidades de linguagem. Salusvita, 28(1), 85-100. [ Links ]
Hall, G. & Sundberg, M. L. (1987). Teaching mands by manipulating conditioned establishing operations. The Analysis of Verbal Behavior, 5, 41-53. [ Links ]
Lamarre, J. & Holland, J.G (1985). The functional independence of mands and tacts. Journal of the Experimental Analysis of Behavior, 43(1), 5-19. [ Links ]
Lima, D. C., Souza, D. G. de, Martinez, C. M. S. & Rocca, J. Z. (2010). Atividades recreativas como suporte na ampliação de vocabulário e na aquisição de leitura para não-leitores. Revista de Terapia Ocupacional da Universidade de São Paulo, 21, 61-67. [ Links ]
Matos, M. A. (1991). As categorias formais de comportamento verbal em Skinner. Reunião Anual da Sociedade de Psicologia de Ribeirão Preto, 21. (pp. 333-341). Ribeirão Preto, Brasil. Recuperado a partir de http://www.itcrcampinas.com. br/pdf/outros/as_categorias_formais_de_comportamento_verbal.PDF. [ Links ]
Papalia, D. E. & Olds, S. W. (2000). Desenvolvimento humano. São Paulo: Artmed. [ Links ]
Polson, D. A. D. & Parsons, J. A. (2000). Selection-based versus tography-based responding: an important distinction for stimulus equivalence?. The Analysis of Verbal Behavior, 17, 105-128. [ Links ]
Rosa Filho, A. B., Rose, J. C. de, Souza, D. G. de, Hanna, E. S. & Fonseca, M. L. (1998). Aprendendo a ler e a escrever em pequenos passos [software para pesquisa]. São Carlos: Universidade Federal de São Carlos. Recuperado a partir de http:// geic.ufscar.br:8080/site. [ Links ]
Skinner, B. F. (1978). O comportamento verbal. São Paulo: Cultrix. [ Links ]
Stemmer, N. (1992). The behavior of the listener, generic extensions, and the communicative adequacy of verbal behavior. The Analysis of Verbal Behavior, 10, 69-80. [ Links ]
Twyman, J. S. (1996). The functional independence of impure mands and tacts of abstracts stimulus properties. The Analysis of Verbal Behavior, 13, 1-19. [ Links ]
Vichi, C., Nascimento, G. S & Souza, C. B. A. (2012). Aprendizagem ostensiva, comportamento de ouvinte e transferência de função por pareamento de estímulos. Revista Brasileira de Terapia Comportamental Cognitiva, 14(1), 16- 30. [ Links ]
Wraikat, R., Sundberg, C. T. & Michael, J. (1991). Topography and selectionbasead verbal behavior: a further comparison. The Analysis of Verbal Behavior, 9, 1-17. [ Links ]
Texto recebido em junho 2013 e aprovado para publicação em janeiro de 2014.
* Mestra em Psicologia do Desenvolvimento e Aprendizagem, pela Universidade Estadual Paulista (Unesp-Bauru-SP); psicóloga pela Unesp-Bauru. E-mail:carolina_santonelli@yahoo.com.br.
**Doutorando em Psicologia na Universidade Federal de São Carlos (UFSCar); mestre em Psicologia do Desenvolvimento e Aprendizagem pela Universidade Estadual Paulista (Unesp-Bauru); membro do Laboratório de Aprendizagem, Desenvolvimento e Saúde da Unesp-Bauru; membro do Instituto de Ciência e Tecnologia sobre Comportamento, Cognição e Ensino (INTCECCE); psicólogo pela Unesp-Bauru. Endereço: Universidade Estadual Paulista Júlio de Mesquita Filho, Faculdade de Ciências de Bauru. Avenida Engenheiro Luiz Edmundo Carrijo Coube, 14-01 - Vila Geisel. Bauru-SP, Brasil. CEP: 17033-360. Telefone: (14) 3103-6000. E-mail:filosofoajn@gmail.com.
*** Mestra em Psicologia do Desenvolvimento e Aprendizagem pela Universidade Estadual Paulista (Unesp-Bauru); psicóloga pela Unesp-Bauru. Endereço: Prefeitura Municipal de Jaboticabal, Ambulatório de Saúde Mental. Praça Doutor Jorge Tibiriçá, 25 - Centro, Jaboticabal-SP, Brasil. CEP: 14870-095. Telefone: (16) 3203-5224.E-mail:mariana084@hotmail.com.
****Docente do Departamento de Psicologia e do Programa de Pós-Graduação em Psicologia do Desenvolvimento e Aprendizagem (Unesp-Bauru); membro do Laboratório de Aprendizagem, Desenvolvimento e Saúde (Unesp-Bauru); pesquisadora do Instituto de Ciência e Tecnologia sobre Comportamento, Cognição e Ensino (INTC-ECCE). Endereço: Universidade Estadual Paulista Júlio de Mesquita Filho, Faculdade de Ciências de Bauru, Departamento de Psicologia. Avenida Engenheiro Edmundo Carrijo Coube, s/nº, Bauru-SP, Brasil. CEP: 17033-360. Telefone: (14) 31036-087.E-mail:anaverdu@fc.unesp.br.

