










Serviços Personalizados
Journal

artigo
 Português (pdf)
Português (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
Indicadores
Compartilhar

 Permalink
PermalinkPsicologia: teoria e prática
versão impressa ISSN 1516-3687
Psicol. teor. prat. v.10 n.2 São Paulo dez. 2008
ARTIGOS ORIGINAIS
Avaliação cognitiva de leitura: o efeito de regularidade grafema-fonema e fonemagrafema na leitura em voz alta de palavras isoladas no português do Brasil
Cognitive reading evaluation: the grapheme-phoneme and the phonemegrapheme regularity effect in the word reading aloud in Brazilian Portuguese
Evaluación cognitiva de la lectura: el efecto de regularidad grafemafonema y fonema-grafema en la lectura en voz alta de palabras aisladas en el portugués de Brasil
Ângela Maria Vieira PinheiroI; Patrícia Silva LúcioII; Daniel Márcio Rodrigues SilvaIII
I Universidade Federal de Minas Gerais
II Faculdade de Minas (Faminas)
III Centro de Referência em Saúde Mental
RESUMO
Este estudo avalia o efeito de regularidade na leitura em voz alta de palavras isoladas. Crianças da 1ª à 3ª série do Ensino Fundamental de uma escola particular de Belo Horizonte leram, em duas sessões, uma lista de 323 palavras de baixa freqüência. Os estímulos variaram de 4-8 letras e foram classificados em duas categorias de regularidade: grafema-fonema e fonema-grafema (regular e irregular). Medidas de tempo de reação (TR) e de porcentagens de erros foram coletadas. Considerando a regularidade grafema-fonema, um efeito de regularidade geral ocorreu apenas nos erros. Considerando a relação fonema-grafema, esse efeito apareceu tanto no TR quanto nos níveis de precisão da leitura dos participantes. Tais resultados sugerem que, em português, o nível de regularidade da escrita das palavras interfere na leitura. Em razão desses resultados, a metodologia usada para a construção de listas para a averiguação do efeito de regularidade na leitura em português é discutida.
Palavras-chave: Leitura em voz alta de palavras, Estratégia fonológica de leitura, Efeito de regularidade, Categorias de regularidade, Tempo de reação.
ABSTRACT
The study evaluates the regularity effect in the reading aloud of isolated words. School children from 1st to 3rd grade from a private school of Belo Horizonte City read, in two sessions, a list of 323 low frequency words. The stimuli varied from 4-8 letters and were classified into two categories of grapheme-phoneme and phoneme-grapheme regularity (regular and irregular). Measures of reaction time (RT) and of percentage of accuracy were collected. When we considered the grapheme-phoneme regularity, a general effect of regularity occurred in the errors, and this effect appeared both in RT and in the errors when we considered the phoneme-grapheme regularity. Such results suggest that, in Portuguese, the level of regularity of the spelling of words interfere in reading. In the light of these results, the methodology used for the construction of lists for the evaluation of the regularity effect in reading is discussed.
Keywords: Reading words aloud, Phonological strategy in reading, Regularity effect, Categories of regularity, Reaction time.
RESUMEN
El estudio evalúa el efecto de regularidad en la lectura en voz alta de palabras aisladas. Niños de 1ª a 3ª serie de enseñanza básica de una escuela particular de la Ciudad de Belo Horizonte leyó, en dos sesiones, una lista de 323 palabras de baja frecuencia. Los estímulos variaron de 4-8 letras y fueron clasificados en dos categorías de regularidad grafema-fonema e fonema-grafema (regular e irregular). Medidas de tiempo de reacción (TR) y de porcentajes de precisión fueron tomadas. Considerando se la regularidad grafema-fonema, un efecto de regularidad general ocurrió en los errores. Considerando se la relación fonema-grafema, ese efecto apareció tanto en el TR como en los errores. Tales resultados sugieren, que en portugués, el nivel de regularidad de la escritura de las palabras interfiere en la lectura. La metodología usada para la construcción de listas para averiguar el efecto de regularidad en la lectura del portugués es discutida.
Palabras clave: Lectura en voz alta de palabras, Estrategia fonológica de lectura, Efecto de regularidad, Categorías de regularidad, Tiempo de reacción.
Introdução
A investigação dos fatores que exercem influência no processamento de palavras isoladas – área de estudo denominada reconhecimento de palavras – tem se baseado em medidas de tempo de reação (o tempo entre a apresentação de um estímulo e a resposta do participante ao mesmo) e proporções de acertos e erros, assim como na análise dos tipos de erros produzidos pela leitura de classes diferentes de estímulos, tais como: palavras de alta e baixa freqüência de ocorrência, palavras regulares/irregulares (de acordo com a correspondência entre grafema e fonema), não-palavras (seqüências de letras, construídas com estruturas ortográficas possíveis na língua sob consideração, mas não associadas a nenhum significado) e palavras reais e não-palavras de comprimentos (número de letras/sílabas) variáveis. Para Henderson (1984), a manipulação dessas classes de palavras tem propiciado não só a formulação de modelos de processamento da leitura, como também o desenvolvimento de procedimentos para avaliar os componentes desses modelos. Uma das teorias que têm recebido muito suporte empírico, além de ter se mostrado muito útil, é a teoria de duplo processo de leitura, originalmente proposta por John Morton em 1979.
Segundo os modelos derivados dessa teoria, cuja versão mais influente é o modelo de Coltheart et al. (2001), a leitura de palavras em voz alta – definida como a derivação de som e de significado de palavras escritas – pode ocorrer por meio de dois processos principais que funcionam de forma interativa: um processo envolvendo mediação fonológica, que se dá na rota/via fonológica, ou por meio de um processo visual direto, que se dá na rota/via lexical. A síntese que apresentamos a seguir sobre esses processos baseia-se principalmente em Coltheart et al. (2001) que, nesse artigo clássico, resumem o estado da arte sobre a teoria de duplo processo de leitura e apresentam o modelo de dupla-rota em cascata (DRC), que representa uma evolução dos modelos de dupla-rota anteriores.
Assim, a leitura pela rota fonológica, também denominada leitura fonológica ou processo fonológico, depende da utilização do conhecimento das regras de conversão entre grafema e fonema para a construção da pronúncia de uma palavra. Já a leitura pela rota lexical, também conhecida como leitura lexical ou processo lexical, depende do reconhecimento de uma palavra previamente adquirida e memorizada, e da recuperação de seu significado e de sua pronúncia por meio de um endereçamento direto ao léxico – o qual incorpora todos os conhecimentos (ortográficos e fonológicos) que possuímos sobre nosso vocabulário.
O processo fonológico, por basear-se em regras de correspondência grafema-fonema, é adequado para a leitura de palavras regulares e de não-palavras, mas causa dificuldades – a saber, aumento de tempo de reação e/ou aumento de erros – para a leitura de palavras irregulares. Uma palavra é considerada regular quando apresenta correspondência grafema-fonema (leitura) ou fonema-grafema (escrita) regida por regras que podem ser independentes de contexto (por exemplo, BALA) ou dependentes de contexto (por exemplo, CARO). Uma palavra que contém uma (ou mais) correspondência grafema-fonema ou fonema-grafema não regida por regras é considerada irregular, como BOXE (PARENTE; SILVEIRA; LECOURS, 1997; PINHEIRO, 1995; OGUSUKO; LUKASOVA; MACEDO, 2008).
A principal característica da leitura lexical é que a pronúncia da palavra é retirada/processada como um todo, após consulta ao léxico, processo denominado acesso lexical. A implicação da recuperação da pronúncia como um todo é que tanto as palavras regulares quanto as irregulares podem ser lidas corretamente por meio da via lexical.
As palavras regulares podem, portanto, ser pronunciadas com sucesso tanto pelo processo lexical como pelo fonológico. Por gerarem sempre a mesma pronúncia, independentemente do modo como são produzidas (por acesso direto da memória lexical – processo lexical – ou pelo uso das regras de correspondência grafema-fonema – processo fonológico), podem ser lidas mais rapidamente e mais corretamente do que as palavras irregulares. A maior rapidez e a maior correção da leitura das palavras regulares em relação às palavras irregulares são conhecidas como efeito de regularidade. Esse efeito, que pode ocorrer tanto em tempo de processamento quanto em termos de erros, é interpretado como um sinal de leitura fonológica (KINOSHITA; LUPKER; RASTLE, 2004; SEIDENBERG et al., 1984; TARABAN; McCLELLAND, 1987).
A desvantagem observada para a leitura de palavras irregulares ocorre quando a pronúncia dada pelas duas rotas não é a mesma. A palavra irregular FIXO, por exemplo, poderá ser lida como /fiksu/ pela rota lexical e como 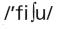 pela rota fonológica. Esse desacordo entre as pronúncias dadas pelas diferentes rotas é observado principalmente nas palavras irregulares pouco familiares (de baixa freqüência de ocorrência). Como a rota lexical, ao processar palavras pouco familiares, opera mais vagarosamente, dá margem para que a pronúncia produzida pelo processo fonológico (por meio do uso das regras de correspondência grafema-fonema) chegue à memória articulatória junto com a pronúncia lexical, ou mesmo antes dela. No primeiro caso, as duas pronúncias serão comparadas. Se houver um desacordo, o que acontece no caso de palavras irregulares, um atraso ocorrerá por causa da necessidade de recorrer ao léxico para uma confirmação, o que configura um efeito de regularidade em tempo de processamento. No segundo caso, quando a pronúncia da palavra irregular pela rota fonológica é produzida antes da pronúncia pela rota lexical, o leitor poderá cometer um erro, o que, por sua vez, configura um efeito de regularidade em erros. O efeito de regularidade, tanto para tempo de processamento quanto para erros, tende a não afetar as palavras irregulares de alta freqüência porque a pronúncia dessas palavras é freqüentemente processada pela rota lexical, antes que a pronúncia gerada pela tradução grafema-fonema feita pela rota fonológica se torne disponível.
pela rota fonológica. Esse desacordo entre as pronúncias dadas pelas diferentes rotas é observado principalmente nas palavras irregulares pouco familiares (de baixa freqüência de ocorrência). Como a rota lexical, ao processar palavras pouco familiares, opera mais vagarosamente, dá margem para que a pronúncia produzida pelo processo fonológico (por meio do uso das regras de correspondência grafema-fonema) chegue à memória articulatória junto com a pronúncia lexical, ou mesmo antes dela. No primeiro caso, as duas pronúncias serão comparadas. Se houver um desacordo, o que acontece no caso de palavras irregulares, um atraso ocorrerá por causa da necessidade de recorrer ao léxico para uma confirmação, o que configura um efeito de regularidade em tempo de processamento. No segundo caso, quando a pronúncia da palavra irregular pela rota fonológica é produzida antes da pronúncia pela rota lexical, o leitor poderá cometer um erro, o que, por sua vez, configura um efeito de regularidade em erros. O efeito de regularidade, tanto para tempo de processamento quanto para erros, tende a não afetar as palavras irregulares de alta freqüência porque a pronúncia dessas palavras é freqüentemente processada pela rota lexical, antes que a pronúncia gerada pela tradução grafema-fonema feita pela rota fonológica se torne disponível.
No português, o efeito de regularidade na proporção de erros/acertos se expressa por altas porcentagens de erros de regularização e de erros de troca de qualidade de vogal cometidos nas palavras irregulares (PARENTE; SILVEIRA; LECOURS, 1997; PINHEIRO, 1995, 2006; SALLES, 2005). No primeiro tipo de erro, a correspondência grafema-fonema irregular de uma palavra é tratada como se fosse uma correspondência regular, como o <x> da palavra NEXO pronunciado como 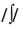 . Nos erros de troca de qualidade de vogal, uma vogal aberta é lida como se fosse fechada e vice-versa (por exemplo, CEDO lida como
. Nos erros de troca de qualidade de vogal, uma vogal aberta é lida como se fosse fechada e vice-versa (por exemplo, CEDO lida como 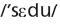 e BOLA lida como
e BOLA lida como  ). Já os erros causados por desconhecimento de regras contextuais ocorrem nas palavras que possuem correspondência grafema-fonema controlada por regras. Nenhum desses erros, no entanto, ocorre quando as palavras são lidas pela rota lexical, porque nessa rota, como vimos, a pronúncia da palavra é recuperada como um todo e, por isso, em princípio, gera uma pronúncia adequada para qualquer tipo de palavra, independentemente do seu nível de regularidade grafema-fonema.
). Já os erros causados por desconhecimento de regras contextuais ocorrem nas palavras que possuem correspondência grafema-fonema controlada por regras. Nenhum desses erros, no entanto, ocorre quando as palavras são lidas pela rota lexical, porque nessa rota, como vimos, a pronúncia da palavra é recuperada como um todo e, por isso, em princípio, gera uma pronúncia adequada para qualquer tipo de palavra, independentemente do seu nível de regularidade grafema-fonema.
Partindo das suposições teóricas associadas ao efeito de regularidade na leitura discutidas por Pinheiro e Rothe-Neves (2001), o presente trabalho propõe testar um banco de palavras cuja classificação de regularidade toma como referência a regularidade grafemafonema, para que a magnitude do efeito de regularidade na leitura, em português, seja adequadamente conhecida, já que no estudo de Pinheiro (1995) – estudo pioneiro na área de reconhecimento de palavras por crianças brasileiras – o efeito de regularidade para a leitura foi testado com listas de palavras cuja classificação de regularidade baseou-se na escrita, ou seja, na regularidade fonema-grafema. Assim, Pinheiro descobriu que as diferentes categorias de regularidade testadas somente tiveram um efeito significativo na leitura de palavras de baixa freqüência e que esse efeito (palavras regulares lidas mais rapidamente do que palavras irregulares) foi restrito aos anos iniciais e ao tempo de reação, não se estendendo à proporção de acertos.
Os resultados encontrados em diversos estudos (PINHEIRO, 1995, 2006; SALLES; PARENTE, 2002; SUCENA; CASTRO, 2005) sugeriram que a leitura fonológica predomina no início da alfabetização. Por volta da 3ª série, quando as crianças estão desenvolvendo representações lexicais para os itens menos familiares, o efeito de regularidade tende a desaparecer. No entanto, Pinheiro e Rothe-Neves (2001) alertam que essa interpretação deve ser considerada com cautela, já que, em português, a maioria das palavras irregulares para a escrita – por exemplo: cigana, traje, caçada – pode ser pronunciada com o uso das regras de correspondência grafema-fonema, isto é, não são irregulares do ponto de vista da leitura. Como conseqüência, é possível que as crianças mais experientes, por terem um maior conhecimento dessas regras, não mostrem o efeito de regularidade. Isso pode ocorrer não porque as crianças estejam lendo lexicalmente, e sim por estarem em um estágio mais avançado de domínio do processo fonológico, em que as correspondências grafema-fonema regulares para a leitura, mas irregulares para a escrita, são aprendidas. Assim, Pinheiro e Rothe-Neves (2001) levantam a possibilidade de que a lista de Pinheiro (1995, 2006), cuja classificação de regularidade foi feita com base na escrita, possa ter induzido à ausência do efeito de regularidade na leitura das crianças mais experientes, impedindo-nos, pois, de avaliar com precisão a emergência do processo lexical na leitura ao longo do desenvolvimento. Essa possibilidade foi tomada como tendo implicações para a construção de novas listas e nela reside uma das motivações para o presente estudo.
No entanto, a maior dificuldade que encontramos ao tentar construir listas de palavras com regularidade para a leitura é de ordem metodológica, pois um dos problemas relacionados ao efeito de regularidade no português é que o caráter regular de nossa ortografia impõe uma limitação no uso desse efeito como teste do processo fonológico na leitura (mas não na escrita). Por exemplo, considerando a relação grafema-fonema, temos em nossa língua apenas dois tipos de irregularidade: (1) palavras contendo o <x> intervocálico (por exemplo, fixo) – irregularidade do tipo 1A, cuja irregularidade também se aplica à escrita – e (2) palavras contendo as vogais <e> ou <o> em posição paroxítona (por exemplo, cedo, copo) – irregularidade do tipo 1B que se aplica apenas à leitura (PARENTE; SILVEIRA; LECOURS, 1997). Enquanto o número de palavras tipo 1A é bem pequeno, nem todas as palavras do tipo 1B favorecem erros de troca de qualidade de vogal (PARENTE; HOSOGI; LECOURS, 1997; PINHEIRO; ROTHE-NEVES, 2001; LÚCIO; BRAGA; PINHEIRO, 2005).
A despeito das limitações apontadas, a nossa primeira hipótese é a de que, com o uso de uma lista cuja classificação de palavras tome como referência a leitura, o contraste entre palavras regulares e irregulares gere um efeito significativo tanto em tempo de processamento como em erros, com vantagem para as palavras regulares. Dessa forma, como antecipado por Pinheiro e Rothe-Neves (2001), a ausência do efeito de regularidade poderá indicar leitura lexical, mais do que na lista original (PINHEIRO, 1995, 2006). Como vimos, nesse tipo de leitura, a pronúncia das palavras, por ser determinada lexicalmente, não está sujeita a erros de troca de qualidade de vogal e a regularizações.
Outra questão a ser resolvida, ao se construírem listas de palavras para testar o efeito de regularidade na leitura, é investigar se, além do controle da regularidade para a leitura, deve-se, também, controlar o nível de regularidade para a escrita nas palavras classificadas como regulares e irregulares para a leitura. Assim, o presente estudo tem como objetivo testar a magnitude do efeito de regularidade na leitura em português tomando como referência a regularidade das palavras para a leitura e averiguar até que ponto a regularidade das palavras para a escrita desempenha um papel na emergência do efeito de regularidade em nossa língua. Para atingir esses objetivos, utilizamos uma lista em que as palavras, em cada categoria de regularidade para a leitura, foram adicionalmente classificadas em termos de sua regularidade para a escrita, o que nos permitiu formular a nossa segunda hipótese (que é parcialmente contrária à primeira): se o nível de regularidade de palavras para a escrita também influencia a leitura de palavras, então o efeito de regularidade será diminuído na leitura de uma lista de palavras cuja classificação de regularidade toma como referência somente a leitura. Isso ocorreria porque as palavras irregulares para a escrita estão distribuídas em todas as categorias de regularidade para a leitura, interferindo assim no efeito que seria esperado.
Método
O presente estudo é parte de um estudo maior, em que um amplo corpo de itens que apresenta o atributo palavras com classificação de regularidade para a leitura e para a escrita está sendo analisado para a seleção de itens que irão compor uma tarefa de leitura em voz alta de palavras reais a ser desenvolvida. Esse corpo de itens é o instrumento do presente trabalho, que foi desenvolvido especificamente para essa pesquisa e que foi recentemente publicado (PINHEIRO, 2007). O projeto do qual o estudo faz parte foi aprovado pelo Comitê de Ética em Pesquisa com Seres Humanos (Coep) da Universidade Federal de Minas Gerais (UFMG).
Amostra
A amostra foi composta de 53 crianças da 1ª (N = 21), 2ª (N = 18) e 3ª séries (N = 14) do Ensino Fundamental (47% do sexo feminino), pertencentes a uma escola da rede particular de Belo Horizonte e com desenvolvimento normal na habilidade de leitura, segundo o julgamento de suas professoras. Por serem alunos regulares, a idade da amostra variou de 7 anos e 3 meses a 9 anos e 6 meses. Os responsáveis pelas crianças foram devidamente esclarecidos sobre a pesquisa e deram consentimento para que suas crianças participassem do estudo.
Instrumento
Uma lista de palavras com 323 itens de baixa freqüência (PINHEIRO, 1996) dividida em duas partes foi o instrumento do presente estudo. Cada lista gerada é composta por palavras de 4-8 letras (o efeito de extensão de palavras não será tratado aqui), distribuídas em duas categorias de regularidade grafema-fonema: 1. palavras regulares para a leitura (RL) – palavras contendo correspondências grafema-fonema regidas por regras que são independentes de contexto (por exemplo, bala) ou dependentes de contexto (por exemplo, rasa) – e 2. palavras irregulares para a leitura (IRL) – palavras contendo irregularidade do tipo 1A e/ou do tipo 1B (por exemplo, boxe).
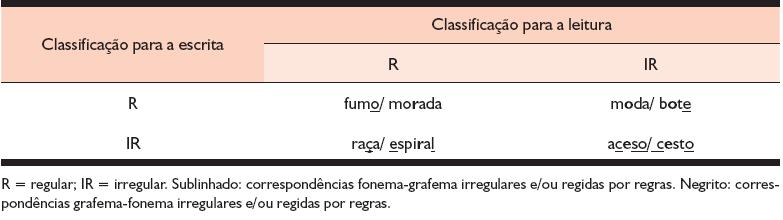
Em cada categoria de regularidade para a leitura, as palavras podem variar segundo a sua classificação para a escrita, podendo ser (1) palavras regulares para a escrita (RE) – palavras que possuem perfeita correspondência fonema-grafema (por exemplo, cava) ou em que essa relação é regida por regras contextuais, como o caso dos sons /I/ e /u/ que, em final de palavra, são respectivamente grafados com os vocálicos <e> e <o>, e o caso do som /h/ intervocálico, que é grafado com o dígrafo <rr>, entre outros casos; ou (2) palavras irregulares para a escrita (IRE) – palavras que apresentam pelo menos um fonema que pode ser arbitrariamente representado por mais de um grafema (por exemplo, na palavra BUZINA, o som /z/ poderia ser representado por <s> ou por <z>). A Tabela 1 mostra a variação da classificação das palavras para a escrita (relação fonema-grafema) para as diferentes categorias de regularidade para a leitura (relação grafema-fonema).
Tabela 1. Exemplos de palavras em cada categoria de classificação para a escrita, em função da classificação para a leitura
O teste foi aplicado mediante o uso de computadores portáteis que apresentaram as palavras isoladas que compõem as listas no centro de sua tela por meio do programa Cogwork, cedido pela equipe do professor Philip Seymour da Universidade de Dundee, Escócia, especialmente para este estudo. As respostas e o tempo de reação das crianças foram automaticamente gravados durante o teste pelo próprio computador.
Procedimento
O estudo foi realizado nos meses de outubro-dezembro de 2001. O teste foi aplicado por bolsistas do Programa Institucional de Bolsas de Iniciação Científica (Pibic). Cada criança – testada individualmente por meio de um microcomputador em uma sala especialmente oferecida para a pesquisa pela escola – leu, em sessões diferentes, uma das duas listas. Na primeira sessão, havia um treinamento com uma lista de dez palavras. A seguir, introduzia-se a primeira lista experimental, escolhida aleatoriamente. Na segunda sessão, que geralmente ocorria em um intervalo de três dias, era apresentada a outra lista. Cada lista possuía três pausas, caso a criança necessitasse de descanso. Os itens das listas eram randomizados pelo computador.
Tratamento de dados
Os resultados, que se constituíram de TR e de porcentagens de acertos produzidos pela amostra na leitura das palavras, foram tratados por meio de análises de variância (ANOVAS – General Linear Model) conduzidas tanto nas médias das condições para o número de participantes testados – análise de sujeitos (AS) – quanto nas médias dos participantes para cada item do teste – análise de itens (AI). Estas geraram, respectivamente, os valores F1 e F2. A primeira análise permite a generalização dos resultados para um grupo particular de participantes, e a segunda permite generalizações dos estímulos do teste para a população de itens do qual o conjunto de itens experimentais foi derivado.
Segundo Clark (1973), para uma comparação entre variáveis ser considerada significativa, é necessário que resultados significativos sejam obtidos nas duas análises (de participantes e de itens) e que, a seguir, com base nos valores de F1 e F2, seja feito o cálculo da estatística denominada minF. O minF é obtido pela Fórmula 1:
Fórmula 1:
F1 x F2
F1 + F2
Os graus de liberdade (i, j) de minF também são calculados em termos de F1 e F2. Dados os valores F1(n, n1) e F2(n, n2), i será igual a n e j será o número inteiro mais próximo do resultado da Fórmula 2:
Fórmula 2:
(F1 + F2)2
F12 + F22
n2 n1
Seguindo as recomendações de Clark, no presente trabalho, empregamos o cálculo de minF para efetuar os nossos testes de hipóteses e rejeitamos a hipótese nula sempre que p < 0,05. (Para uma discussão mais detalhada dessas questões, ver Clark (1973) e Raaijmakers (2003); e para a aplicação dessa estatística em pesquisa brasileira, ver Justi e Pinheiro (2006)).
As análises para TR e níveis de precisão tomaram inicialmente como referência a classificação de regularidade de palavras na direção da leitura e posteriormente a direção da escrita, e consistiram, em cada um desses níveis, da busca de efeitos de escolaridade e de regularidade e de interações entre essas variáveis. Cada um desses efeitos principais e interações podem gerar resultados significativos tanto na direção da leitura quanto na da escrita ou apenas em uma direção. Assim, dois valores de minF serão aqui reportados quando resultados significativos ocorrerem em ambas as direções, e apenas um valor quando os resultados forem significativos em apenas uma direção. No que diz respeito às comparações entre a 1ª, 2ª e 3ª séries, além da análise de variância, foram efetuados testes post hoc para cada par de médias.
Antes de apresentarmos os resultados, deter-nos-emos na descrição do tratamento inicial das variáveis: tempo de reação e erros.
Tratamento do tempo de reação
O presente estudo adotou a técnica de médias restringidas para a análise do tempo de reação, técnica em que os valores de TR que se situam dois (ou três) desvios padrão abaixo ou acima da média de um participante (AS) ou do conjunto de itens (AI) são excluídos da análise (PEREA, 1999). Aqui, foram excluídos todos os valores que se desviam dois desvios padrão em relação à média.
Após o estabelecimento das médias dos participantes, partiu-se para a identificação dos outliers. Segundo Ratcliff (1993), os outliers constituem tempos de resposta gerados por processos outros que não aqueles que estão sob investigação (ou seja, que não constituem efeitos da(s) variável(is) independente(s) em estudo, como a adivinhação ou a falta de atenção por parte do sujeito). Nenhum participante foi considerado outlier pelas análises estatísticas, e, portanto, não houve exclusão de participantes do estudo (dois participantes da 2ª série e um da 3ª, apesar de apresentarem médias bastante elevadas em relação ao grupo, não foram considerados pela análise estatística como outliers e, portanto, permaneceram no estudo). Em relação aos itens, aqueles que foram identificados como outliers também não foram excluídos das análises, dado que um dos objetivos do presente estudo é a seleção de itens que farão parte de um teste de reconhecimento de palavras que está em desenvolvimento pelo nosso grupo de pesquisa, e os itens considerados outliers podem, justamente, conter propriedades que são relevantes para a distinção entre bons e maus leitores, em termos das latências produzidas.
Tratamento das respostas incorretas
Após a coleta dos dados, as gravações da leitura das palavras pelas crianças foram ouvidas, e os erros computados. A partir dessa análise preliminar, executou-se a tabulação dos erros que consistiu no levantamento do número e dos tipos de erros cometidos por cada grupo de participantes para todos os itens do teste. A análise dos tipos de erros será discutida de forma parcial. Somente serão apresentados os aspectos dessa análise que forem necessários para o esclarecimento de resultados obtidos na análise quantitativa. (Para detalhes da análise qualitativa dos erros cometidos no presente estudo, ver Pinheiro, Lúcio e Cunha (no prelo)).
Resultados e discussão
As médias gerais de tempo de reação (para os itens lidos corretamente) e de índices de precisão, por série, são apresentadas na Tabela 2. Contrariando as expectativas, o efeito geral de escolaridade ocorreu apenas em termos de precisão (minF (1, 216) = 21,804, p < 0,001 (direção da leitura); minF (1, 216) = 29,028, p < 0,001 (direção da escrita)), não se evidenciando um ganho em rapidez na leitura de palavras isoladas com o decorrer da escolarização. Os resultados das comparações entre pares de séries (1ª e 2ª séries e entre a 2ª e a 3ª) tanto para TR quanto para acertos, ainda ao que se refere ao efeito de escolaridade, não foram confirmados pelo minF. Diante desses achados, para propósitos da análise quantitativa, todas as três séries serão tratadas como um mesmo grupo, que chamaremos aqui de crianças em processo de aquisição da leitura.
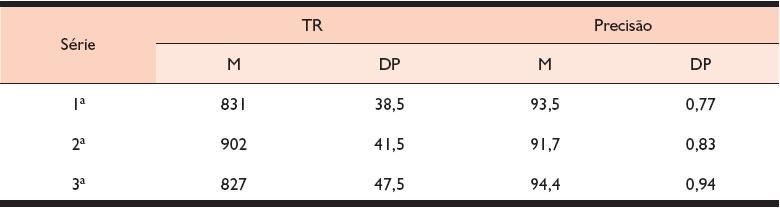
Tabela 2. Média (M) e desvio padrão (DP) para o TR (mseg.) das respostas corretas e para precisão (% de acerto) na leitura pelas crianças das séries estudadas
Efeito de regularidade
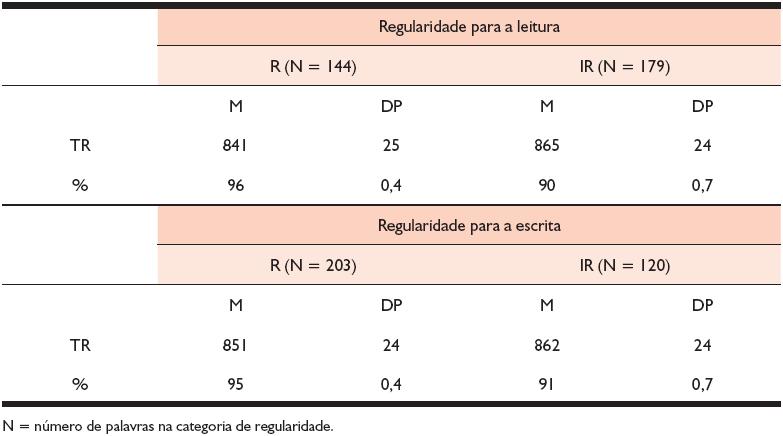
Considerando o TR, e mais uma vez contrariando a nossa primeira hipótese e reforçando a segunda, o efeito de regularidade foi encontrado apenas na direção da escrita (minF (1, 216) = 36,682, p < 0,001). No entanto, o efeito aparece em ambas as direções quando consideramos as porcentagens de acertos: minF (1, 216) = 34,948, p < 0,001 (direção da leitura); minF (1,216) = 14,544, p < 0,002 (direção da escrita)). A Tabela 3 apresenta as médias dos dois níveis de regularidade estudados tanto para TR quanto para níveis de precisão, considerando a regularidade de palavras para a leitura e para a escrita.
Tabela 3. Médias (M) e desvios padrão (DP) para o tempo de reação (TR) e a porcentagem de acertos (%) nas palavras regulares (R) e irregulares (IR) para a leitura e para a escrita obtidas pelo grupo de crianças em processo de aquisição da leitura
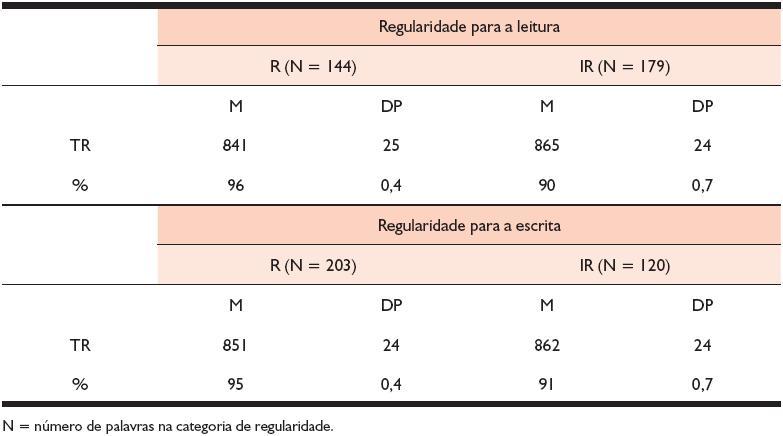
Esse padrão de resultados pode ser explicado quando analisamos os dados de forma qualitativa. Um fato que chamou a atenção nesse estudo é que, considerando-se a extensão das palavras e a regularidade para a leitura, em todas as séries, as palavras RL de menor comprimento (de 4 a 6 letras) apresentaram médias de TR um pouco mais elevadas do que as palavras IRL de extensão correspondente. Apesar de essas diferenças não terem sido significativas, o fato de a direção das médias ter sido contrária ao que seria esperado despertou nosso interesse na investigação dos possíveis fatores que produziram esses resultados. Dessa forma, uma análise qualitativa, que consistiu na identificação em cada série, de itens outliers, foi efetuada para tentar explicar esses achados. Como vimos, os outliers constituem itens que apresentam valores desviantes em relação ao restante da população de itens, podendo ser esses valores acentuadamente mais elevados ou inferiores do que o restante da população. Chamaremos aqui, respectivamente, de Out+ o primeiro grupo e de Out– o segundo. A Tabela 4 mostra o total de outliers por série, de acordo com a regularidade para a leitura (freqüência relativa sobre o total de itens presentes na categoria). Por ela, podemos observar que os Out+ constituem uma pequena proporção de itens que se distribuem de uma maneira muito semelhante entre as diferentes categorias de regularidade na 2ª e 3ª séries, e que na 1ª série tendem a se concentrar nos itens irregulares. Já os Out– são muito menos freqüentes e exibem um padrão oposto nas categorias de regularidade: diminuem progressivamente da 1ª para a 3ª série na categoria regular e sofrem um ligeiro aumento das séries iniciais para a 3ª série na categoria irregular.
Tabela 4. Porcentagem total de itens que foram considerados outliers, separados em função da série e da categoria de regularidade para a leitura
Após a identificação dos itens que constituem outliers em cada série, e de sua separação de acordo com a classificação para a escrita, calculou-se para cada série a freqüência em que esses outliers ocorrem nas diferentes classificações de regularidade para a escrita. O total de outliers presentes em cada uma das duas categorias foi então dividido pelo total de outliers produzido na série. A Tabela 5 resume os resultados.
Tabela 5. Freqüência relativa (%) de ocorrência de outliers por série, de acordo com a regularidade para a escrita
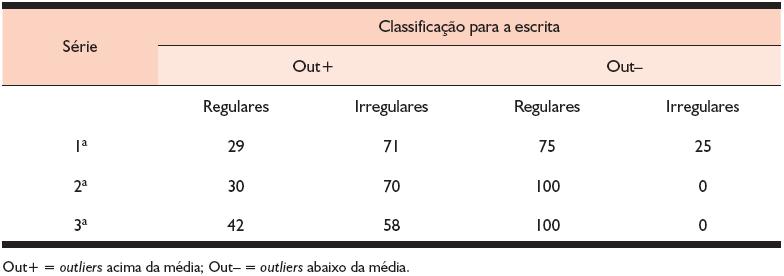
Pela análise da Tabela 5, observamos que, em todas as séries, os outliers com valores acima da média do grupo (Out+) tenderam a se concentrar entre as palavras irregulares para a escrita, enquanto os Out– prevaleceram entre as palavras regulares para a escrita. Dessa forma, constatamos a existência de indícios que apontam que o nível de regularidade para a escrita pode afetar o tempo de reação na leitura em voz alta de palavras isoladas, interferindo, assim, no efeito de regularidade esperado. De fato, Pinheiro (1995), que testou crianças da rede particular de ensino, da mesma forma que no presente estudo, e utilizando uma lista de palavras cuja classificação de regularidade considerou a relação fonema-grafema (direção da escrita), conseguiu identificar a presença do efeito de regularidade apenas nos tempos de leitura que foi restrita à leitura das crianças da 1ª e 2ª séries. No presente trabalho, na situação em que a lista de palavras foi controlada em termos de regularidade para a leitura, não se encontrou o efeito de regularidade em termos de tempo de reação, apesar de sua presença nos erros.
Essa contradição nos faz refletir sobre até que ponto a classificação das palavras quanto aos níveis de regularidade para a leitura e para a escrita influencia a leitura em voz alta de crianças cursando as séries iniciais. Os nossos resultados apontam para a possibilidade de que o nível de regularidade das palavras para a leitura e para a escrita apresenta efeitos distintos na produção de erros e de latências na leitura de crianças cursando as séries iniciais.
Conclusão
Neste estudo, avaliamos o efeito de regularidade nas latências e nos erros de leitura em voz alta de palavras isoladas entre crianças cursando as séries iniciais (da 1ª à 3ª série) do Ensino Fundamental de uma escola particular, por meio de uma lista cuja classificação de regularidade levou em consideração a regularidade das palavras tanto do ponto de vista da leitura quanto da escrita. Procuramos, assim, resolver questões teóricas a respeito de como o efeito de regularidade emerge no português do Brasil.
Os resultados aqui expostos sugerem que, quando consideramos a regularidade para leitura, o efeito de regularidade é restrito aos erros cometidos, o que confirma as suposições teóricas de Pinheiro e Rothe-Neves (2001) de que esse efeito poderia ser obtido no português controlando-se o nível de regularidade das palavras para a leitura, mas contraria a suposição desses autores de que o mesmo efeito também seria encontrado no tempo de processamento. Para nossa surpresa, quando avaliamos o efeito de regularidade a partir da classificação das palavras para a escrita, deparamos com um efeito de regularidade tanto no tempo de leitura quanto nos erros. Isso não seria esperado considerando-se o estudo de Pinheiro (1995), que obteve o efeito apenas no tempo de processamento utilizando essa mesma classificação.
Duas hipóteses são feitas para a divergência de resultados: primeiro, o fato de o número de categorias de regularidade diferir nos dois estudos, havendo sido empregadas três categorias no trabalho de Pinheiro (1995) e apenas duas neste estudo. É possível que o número de categorias empregadas no estudo do efeito de regularidade interfira na emergência ou não desse efeito (LÚCIO, 2008). Segundo, a quantidade de itens investigados difere em ambos os trabalhos, havendo três vezes mais palavras no presente estudo. Assim, o efeito de regularidade estendido no presente estudo pode ter sofrido um efeito indireto do efeito de cansaço ou fadiga (para maiores detalhes sobre o efeito de fadiga na leitura desta mesma lista de palavras, ver Lúcio (2008)).
Em síntese, a influência do nível de regularidade das palavras nas latências de leitura em voz alta ainda não está completamente esclarecida no português do Brasil, já que, em razão do nível de regularidade de nossa ortografia, o efeito de regularidade, como demonstrado, não é facilmente averiguado. O uso de listas com classificação de palavras que permitem a averiguação do efeito de regularidade tanto do ponto de vista da leitura como da escrita, como a lista adotada no presente estudo, parece ser uma solução para o estudo do efeito de regularidade na nossa língua e para os problemas metodológicos associados a esse efeito levantados por Pinheiro e Rothe-Neves (2001) e discutidos na introdução deste trabalho. Considerando que no português do Brasil a maioria das palavras pode ser lida com sucesso por meio de decodificação fonológica, a rapidez e a precisão de leitura podem refletir a habilidade do leitor em aplicar as regras de correspondência grafema-fonema mais do que reconhecimento pela via lexical.
Finalmente, um ponto que deve ser destacado é que, em comparação com outros estudos conduzidos com crianças brasileiras de um modo geral, as crianças do presente estudo apresentaram médias de TR muito mais baixas (por exemplo, no estudo de Godoy (2005) crianças de 1ª série leram palavras de baixa freqüência com uma média de 1.433 mseg. – contra uma média de 831mseg. para a série correspondente no presente estudo, conforme exibido na Tabela 2). No entanto, vale lembrar que o nosso trabalho inova por usar a técnica de médias restringidas (PEREA, 1999) para a análise do tempo de reação, o que pode ter contribuído para as baixas médias encontradas. A despeito disso, é inegável que os participantes do presente estudo apresentaram um desenvolvimento muito superior na habilidade de leitura em relação aos seus pares, que, talvez, não seja representativo nem mesmo das crianças cursando as séries iniciais de outras escolas particulares. Esse fato oferece evidência da robustez do efeito de regularidade na leitura de iniciantes.
Referências
CLARK, H. H. The language-as-fixed-effect fallacy: A critique of language statistics in psychological research. Journal of Verbal Learning and Verbal Behaviour, v. 12, p. 334-359, 1973. [ Links ]
COLTHEART, M. et al. DRC: a dual route cascaded model of visual word recognition and reading aloud. Psychological Review, v. 108, n. 1, p. 204-256, 2001. [ Links ]
GODOY, D. M. A. Aprendizagem inicial da leitura e da escrita no português do Brasil: influência da consciência fonológica e do método de alfabetização. 2005. 188 f. Tese (Doutorado em Lingüística)–Universidade Federal de Santa Catarina, Florianópolis, 2005. [ Links ]
HENDERSON, L. Orthography and word recognition in reading. London: Academic Press, 1984. [ Links ]
JUSTI, F.; PINHEIRO, A. M. V. O efeito de vizinhança ortográfica no português do Brasil: acesso lexical ou processamento estratégico? Revista Interamericana de Psicologia, v. 40, n. 3, p. 257-270, 2006. [ Links ]
KINOSHITA, S.; LUPKER, S. J.; RASTLE, K. Modulation of regularity and lexicality effects in reading aloud. Memory & Cognition, v. 32, n. 8, p. 1255-1264, 2004. [ Links ]
LÚCIO, P. S. Investigação psicométrica de uma tarefa de leitura em voz alta de palavras isoladas. 2008. 179 f. Dissertação (Mestrado em Psicologia)–Universidade Federal de Minas Gerais, Belo Horizonte, 2008. [ Links ]
LÚCIO, P. S., BRAGA, L. H., PINHEIRO, A. M. V. Análise dos erros de troca de qualidade da vogal cometidos por crianças de 1ª a 3ª séries de uma escola particular. In: II CONGRESSO BRASILEIRO DE AVALIAÇÃO PSICOLÓGICA, 2005, Gramado. Anais Gramado: Ibap, 2005. p. 17-20. [ Links ]
MORTON, J. Facilitation in word recognition: Experiments causing change in the logogen model. In: KOLERS, P. A.; WROLSTAD, M. E.; BOUMA H. (Org.). Processing of visible language 1. New York: Plenum Press, 1979. [ Links ]
OGUSUKO, M. T.; LUKASOVA, K.; MACEDO, E. C. Movimentos oculares na leitura de palavras isoladas por jovens e adultos em alfabetização. Psicologia: Teoria e Prática – v. 10, n. 1, p. 113-124, 2008. [ Links ]
PARENTE, M. A. M. P.; HOSOGI, M. L.; LECOURS A. R. Conduta clínica. In: LECOURS, A.R.; PARENTE, M. A. M. P. (Org.). Dislexia: implicações do sistema de escrita do português. Porto Alegre: Artes Médicas, 1997. [ Links ]
PARENTE, M. A. M. P.; SILVEIRA, A.; LECOURS, A. R. As palavras do português. In: LECOURS, A. R.; PARENTE, M. A. M. P. (Org.). Dislexia: implicações do sistema de escrita do português. Porto Alegre: Artes Médicas, 1997. [ Links ]
PEREA, M. Tiempos de reacción y psicología cognitiva: dos procedimientos para evitar el sesgo debido al tamaño muestral. Psicológica, v. 20, p. 13-21, 1999. [ Links ]
PINHEIRO, A. M. V. Reading and spelling development in Brazilian Portuguese. Reading and Writing, v. 7, n. 1, p. 111-138, 1995. [ Links ]
_________. Contagem de freqüência de ocorrência de palavras expostas a crianças da 1ª à 4ª série do Ensino Fundamental. São Paulo: Associação Brasileira de Dislexia, 1996. [ Links ]
_________. Leitura e escrita: uma abordagem cognitiva. 2. ed. São Paulo: Livro Pleno, 2006. [ Links ]
_________. Banco de palavras de baixa freqüência de ocorrência, para crianças brasileiras da 1ª à 4ª série do Ensino Fundamental, classificadas em termos de estrutura silábica, número de letras e regularidade para leitura e para escrita. In: SIM-SIM, I.; VIANNA, F. L. Para a avaliação do desempenho de leitura. Lisboa: Ministério da Educação-Gabinete de Estatística e Planejamento da Educação, 2007. [ Links ]
PINHEIRO, A. M. V.; ROTHE-NEVES, R. Avaliação cognitiva de leitura e escrita: as tarefas de leitura em voz alta e ditado. Psicologia: Reflexão e Crítica, v. 14, n. 2, p. 399-408, 2001. [ Links ]
PINHEIRO, A. M. V.; LÚCIO, P. S; CUNHA, C. R. da. Tarefa de leitura de palavras em voz alta: uma proposta de análise dos erros. Revista Portuguesa de Educação. (No prelo). [ Links ]
RAAIJMAKERS, J. W. A further look at the language-as-fixed-effect fallacy. Canadian Journal of Experimental Psychology, v. 57, n. 3, p. 141-151, 2003. [ Links ]
RATCLIFF, R. Methods for dealing with reaction time outliers. Psychological Bulletin, v. 114, n. 3, p. 510-532, 1993. [ Links ]
SALLES, J. F. Habilidades e dificuldades de leitura e escrita em crianças de 2ª série: abordagem neuropsicológica cognitiva. 2005. Tese (Doutorado)–Universidade Federal do Rio Grande do Sul, Porto Alegre, 2005. [ Links ]
SALLES, J. F.; PARENTE, M. A. M. Processos cognitivos na leitura de palavras em crianças: relação com compreensão e tempo de leitura. Psicologia: Reflexão e Crítica, v. 15, n. 2, p. 321-333, 2002. [ Links ]
SEIDENBERG, M. S. et al. When does irregular spelling or pronunciation influence word recognition? Journal of Verbal Learning and Verbal Behaviour, v. 23, p. 383-404, 1984. [ Links ]
SUCENA, A.; CASTRO, S. L. Estratégias fonológicas e ortográficas na aprendizagem da leitura do português europeu. Anales de la Revista de Psicologia General y Aplicada, v. 10, n. 3, 2005. Disponível em: <http://www.fedap.es/IberPsicologia/Iberpsi10/indiceip10-3.htm>. Acesso em: 30 jan. 2008.
TARABAN, R.; McCLELLAND, J. L. Conspiracy effects in word recognition. Journal of Memory and Language, v. 26, p. 608-631, 1987. [ Links ]
 Endereço para correspondência
Endereço para correspondência
Ângela Maria Vieira Pinheiro
Avenida Antônio Carlos, 6627, campus Pampulha
CEP 31270-901 Belo Horizonte – MG
E-mail: pinheiroamv@yahoo.com.br
Tramitação
Recebido em agosto de 2008
Aceito em novembro de 2008

