










Serviços Personalizados
Journal

artigo
 Português (pdf)
Português (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
Indicadores
Compartilhar

 Permalink
PermalinkCiências & Cognição
versão On-line ISSN 1806-5821
Ciênc. cogn. vol.12 Rio de Janeiro nov. 2007
Artigo Científico
Efeito stroop e rastreamento ocular no processamento de palavras1
Stroop effect and eye-tracking in word processing
Marcus Maia; Miriam Lemle; Aniela Improta França
Universidade Federal do Rio de Janeiro (UFRJ), Rio de Janeiro, Rio de Janeiro, Brasil
Resumo
Como é a organização cerebral do léxico? As palavras são guardadas por inteiro ou existe derivação que forma uma estrutura interna a elas? Usando dois paradigmas experimentais, investigamos se a decomposição morfológica é uma propriedade fundamental do processamento lexical na leitura de palavras isoladas no português do Brasil. O primeiro experimento propõe uma tarefa baseada no chamado Efeito Stroop, no qual processos atencionais concorrentes demonstram a natureza automática das fases iniciais do processamento da leitura. O segundo experimento, usando protocolo de rastreamento ocular durante a leitura, investiga as mesmas palavras, pretendendo identificar, preliminarmente, os pontos de fixação e sacadas na primeira passagem do olhar, bem como nos movimentos regressivos. Os resultados obtidos nos dois experimentos permitem reunir evidências de que, no processo de leitura, as palavras são derivadas morfema a morfema, embora haja também heurísticas globais da visão que atuam simultaneamente no processamento da leitura. © Ciências & Cognição 2007; Vol. 12: 02-??.
Palavras-chave: rastreamento ocular; morfologia interna à palavra; efeito stroop.
Abstract
How is the lexicon organized in the brain? Are words stored as units or is there a derivational process dynamically combining its pieces at each use? The present study, composed by two experimental paradigms, investigates if morphological decomposition is a property inherent to the lexical processing during a reading task in Brazilian Portuguese. The first experiment deals with Stroop Effect, in which attentional processes demonstrate the automatic nature of the initial phases of processing during reading. Using an eye-tracking protocol, the second experiment investigates the process of reading the same words, aiming at identifying, preliminarily, the fixation points and the saccades during first eye scan, as well as the regressive movements. The results obtained in the two experiments gather evidences that, during reading, words are delivered morpheme by morpheme, despite the fact that there are concurrent global heuristics that act simultaneously in reading. © Ciências & Cognição 2007; Vol. 12: 02-??.
Keywords: eye-tracking; morphology internal to words; stroop effect.
Introdução
Um tema de pesquisa muito produtivo em psicolingüística nas últimas três décadas é a investigação do papel do processamento morfológico2 no reconhecimento de palavras e na organização do léxico na mente dos falantes. Uma questão importante do processamento lexical consiste em saber como as palavras complexas são armazenadas e acessadas: há decomposição morfológica prévia ao acesso lexical? Desde os estudos seminais de Taft e Forster (1975;1976), que investigaram experimentalmente a armazenagem e a recuperação de palavras polimorfêmicas na memória lexical, conduzindo ao modelo BOSS, baseado em fatores ortográficos e morfológicos (Taft, 1979), os estudos sobre o parsing perceptual de palavras oferecem evidências contraditórias: de um lado, trabalhos de orientação conexionista, como Seidenberg e McClelland (1989) argumentam que os efeitos encontrados em estruturas sublexicais sejam apenas epifenômenos da redundância ortográfica; de outro lado, estudos como Marslen-Wilson et alii (1994) apresentam resultados de experimentos de priming evidenciando que as palavras são, de fato, representadas morfemicamente ao nível da entrada lexical. Além de sua caracterização conflitante em psicolingüística, a proposição de segmentos sub-lexicais é controversa também no âmbito da teoria gramatical. Os Modelos Lexicalistas (e.g. Chomsky, 1995), embora admitindo unidades menores do que a palavra, consideram . palavr. pronta como sendo a unidade que dá entrada na derivação sintática, ao passo que modelos não lexicalistas, como a Morfologia Distribuída (cf. Halle e Marantz, 1993). assumem uma computação sintática operando por fases com unidades desprovidas de som. Ao final de cada fase acontece a competição, seleção e inserção de peças de vocabulário nos nós terminais da sintaxe. Estas peças passam então por operações pós-inserção que dão a forma morfofonológica final à derivação
O presente estudo investiga, preliminarmente, se a decomposição morfológica é uma propriedade fundamental do processamento lexical na leitura de palavras isoladas em português, usando dois paradigmas experimentais. O primeiro experimento propõe uma tarefa baseada no chamado efeito Stroop, no qual processos atencionais concorrentes demonstram a natureza automática das fases iniciais do processamento da leitura. Nessa tarefa, adaptada do estudo de Prinzmetal e colaboradores (1986), solicita-se a identificação da cor de uma letra componente de um morfema em condição na qual há corte morfêmico, comparativamente à condição em que o corte é não morfêmico, incluindo, ainda, como controle, condição de pseudo morfemas ou seja, palavras em que há apenas coincidência fonológica com a forma do morfema (e.g. jornalista x entrevista). O objetivo do experimento é verificar em que medida no processo da leitura a identificação implícita do morfema no interior da palavra fonológica exercerá efeito de facilitação na realização da tarefa de identificação cromática (por exemplo, a cor da letra i da forma ista). Este efeito será medido através de duas variáveis dependentes: o índice de acertos e os tempos de decisão, computados em milésimos de segundos, utilizando-se a plataforma experimental Psyscope em computador Apple Macintosh.
Um fator adicional também incluído no design desse experimento é a verificação de eventuais diferenças de desempenho resultantes da renegociação de significado acarretada pela adição do sufixo à raiz, contrastando-se formas como, por exemplo, jornalista com formas como frentista. Note-se que, no primeiro exemplo, o sufixo -ista tem sua computação feita tomando por base aquela da palavra jornal, enquanto que em frentista o significado da palavra frente não é o ponto de partida da computação semântica causada pela introdução do sufixo -ista, embora as duas palavras compartilhem a raiz frent-.
Utilizando o equipamento Head-fixed Viewpoint Eye-tracker (CLIPSEN/CNPq), o segundo experimento investiga o rastreamento ocular das mesmas palavras, pretendendo identificar, preliminarmente, os pontos de fixação e sacadas na primeira passagem do olhar, bem como nos movimentos regressivos. Os resultados obtidos nos dois experimentos permitem reunir evidências para avaliar se, no processo de leitura, palavras complexas são parseadas morfologicamente, concatenando-se raízes a afixos, em contraste com os modelos que postulam a ativação lexical indiferenciada de vocábulos plenos.
O artigo é organizado da seguinte forma. Na seção 2, faz-se uma breve revisão da literatura sobre o processamento da morfologia em palavras isoladas, com especial atenção para a caracterização dos modelos de reconhecimento de palavras escritas, procurando estabelecer o quadro teórico relevante para a discussão dos experimentos. A seção 3 reporta o experimento de decisão cromática e a seção 4, o experimento de rastreamento ocular. A seção 5 apresenta as conclusões do artigo.
Modelos de processamento morfológico
Ao ler uma palavra, acessamos o seu significado na íntegra, diretamente no léxico mental, ou precisamos, preliminarmente, realizar operações de decomposição morfológica, concatenação e interpretação composicional? O acesso lexical direto é uma heurística do tipo top-down3, em que se procede diretamente do input sensorial para um nível de representação "mais alto"do item lexical, ou seja, a palavra inteira, tomada como um listema (cf. Di Sciullo e Williams, 1987), sem precisar recorrer à análise de possíveis subcomponentes do item. A decomposição morfológica, por outro lado, é um algoritmo bottom-up em que o acesso lexical é o produto final de operações "menores" de segmentação de morfemas, identificando-se subunidades lexicais que são, então, montadas em todos maiores, os itens lexicais. Os modelos de acesso lexical direto, também denominados de modelos de listagem plena, economizam em recursos computacionais, mas precisam contar com alta capacidade de armazenagem mnemônica. Os modelos composicionais ou de parsing pleno, por outro lado, demandam maior custo computacional, mas economizam na armazenagem mnemônica. Uma terceira alternativa admite a possibilidade de que os dois tipos de processos -heurísticas top down e algoritmos bottom-up - possam coexistir no processamento lexical. São os modelos mistos ou duais, que lançam mão dos dois tipos de recursos, prevendo uma espécie de competição entre eles.
O modelo de Affix-Stripping de Taft e Foster (1975) é o precursor dos modelos estruturais. Utilizando uma tarefa de decisão lexical, Taft e Foster demonstraram que palavras com raízes reais precedidas por prefixos (e.g. re+cursion) são mais difíceis de rejeitar do que palavras com pseudo-raízes (re+pertoire). Uma vez que as raízes reais seriam armazenadas separadamente dos afixos, sua rejeição é mais lenta, pois após a operação de isolamento do afixo estas raízes que podem, de fato, ser localizadas no léxico, requerem consideração extra na tarefa de decisão lexical. Por outro lado, as palavras com pseudo-raízes apresentaram tempos de rejeição menores justamente por não poderem ser localizadas no conjunto de raízes possíveis no léxico. Posteriormente, Taft (1979) demonstra que o efeito de decomposição morfológica do modelo Affix-Stripping também pode ser obtido em palavras com sufixos. Taft (1994) faz ajustes no modelo prevendo que a decomposicionalidade morfológica seja a rota default, mas que o fator freqüência possa também exercer um efeito que resulta em pouca ativação dos morfemas nas palavras mais freqüentes, aproximando, na prática, seu modelo dos modelos duais.
No extremo oposto, a hipótese Full Listing de Butterworth (1983) propõe que as palavras estejam disponíveis para reconhecimento no léxico já com sua morfologia, sendo acessadas apenas em sua forma plena, sem qualquer operação decomposicional. Também os modelos conexionistas como, por exemplo, o desenvolvido por Seidenberg e McClelland (1989), propõem uma arquitetura paralela e distribuída de reconhecimento visual de palavras em que se pretende que ajustes nos pesos das conexões entre unidades ortográficas e fonológicas sejam propagados através de algoritmo de aprendizagem, sendo capazes de simular o reconhecimento de palavras de forma associativa e rápida, sem utilizar a informação morfológica.
No caminho do meio, estão os modelos mistos ou duais, que combinam aspectos dos dois modelos anteriores. O modelo de Augmented Addressed Morphology - AAM de Caramazza e colaboradores (1988) propõe que as palavras familiares sejam acessadas de forma plena, enquanto que as palavras desconhecidas sejam alvo de processos decomposicionais. O modelo de dupla rota paralela de Schreuder e Baayen (1995) propõe que tanto uma rota de parsing morfológico quanto uma rota direta sejam acionadas, em paralelo, desde o início do processo de reconhecimento lexical. O modelo de Marslen-Wilson e colaboradores (1994), estabelecido com base em experimentos de priming, propõe que a decomposição morfológica seja mais provável quando a relação entre a palavra composta com afixos e a sua raiz é transparente. Outro modelo, o de Pinker (1991) prevê que as formas regulares, como, por exemplo, os passados simples formados em -ed, em inglês, sejam acessados via concatenação morfológica, enquanto que os passados irregulares, como taught, por exemplo, sejam armazenados plenamente no léxico. Stockall e Marantz (2006), por outro lado, apresentam evidências de experimentos utilizando a técnica de Magneto-encefalografia, de que um único mecanismo de concatenação morfológica dá conta tanto dos passados regulares quanto dos irregulares em inglês.
Como se vê, a literatura apresenta grande divergência de posições teóricas e métodos. Os experimentos reportados nas seções a seguir têm o intuito de investigar preliminarmente a questão a partir do exame de dados do português, procurando avaliar de forma ampla os três tipos de modelos de processamento lexical resenhados acima a partir de dados recolhidos da atividade de leitura.
Experimento 1 - Decisão cromática no processamento de palavras isoladas
Este estudo baseia-se no chamado "efeito stroop", estabelecido através de uma série de experimentos clássicos em que se testou a nomeação cromática em palavras para cores escritas com letras em cores que podiam concordar ou não com a denotação das palavras (cf. Stroop, 1935). Conforme ilustrado na Figura 1, abaixo, as respostas eram mais rápidas quando havia convergência do que quando havia divergência.
Figura 1 - Efeito stroop.
A interpretação destes resultados geralmente sugere que a dificuldade em nomear palavras com discordância entre a nomeação cromática e a cor das letras se deve a competição, neste caso, entre significado literal e outro metafórico
No presente experimento, estabeleceu-se uma outra sorte de discordância cognitiva: morfológica e visual. A hipótese aqui é a de que uma letra poderia ter sua cor identificada mais acertada e rapidamente quando fizesse parte de um morfema em que todas as letras tivessem a mesma cor. A variável independente "recorte cromático" indica, portanto, que a manipulação de cores poderia singularizar o morfema com todas as letras na mesma cor (corte morfêmico) ou não (corte não morfêmico). Outra variável independente do experimento foi chamada de tipo de morfema, incluindo três níveis, a saber, morfema concatenado a palavras (MP), pseudo-morfema (PM) e morfema concatenado a raízes (MR).
As variáveis dependentes do experimento foram os índices de acerto cromático e os tempos de decisão. A variável independente "tipo de morfema" permitiu que se examinasse o papel de três fatores no processamento de palavras em português:
Materiais e métodos
Participantes
Participaram do experimento, como voluntários, 20 alunos do terceiro período de graduação em Letras da UFRJ, todos com visão normal ou corrigida.
Materiais
Os materiais experimentais foram três listas de 14 palavras cada, tendo-se procurado controlar o tamanho e a freqüência de ocorrência médios das palavras cada lista. Os tamanhos foram equalizados, tendo cada lista, em média, 45 sílabas e 104 letras. As freqüências tiveram como índice para o seu estabelecimento o número de ocorrências no sistema de buscas Google, à época em que o experimento foi realizado. As diferenças médias entre os índices de ocorrência dos itens das três listas não foram significativamente diferentes. A Figura 2 exemplifica as três listas:

Figura 2 - Exemplos dos materiais experimentais
O design em quadrado latino permitiu que todos os sujeitos fossem expostos a todas as condições, mas não aos mesmos itens em todas as condições, havendo, portanto, distribuição do tipo de corte "between subjects" em dois grupos. A Figura 3 ilustra as seis condições experimentais em que se controlou também, sistematicamente, o contraste de cores verde e vermelho.
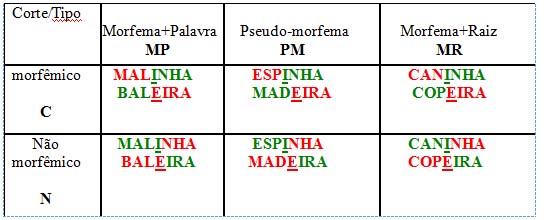
Figura 3 - Condições experimentais.
Além dos 42 itens experimentais, incluiram-se no teste oitenta itens distrativos em que letras no início e no fim das palavras eram destacadas cromaticamente.
Procedimentos
Os participantes foram testados individualmente em sala isolada, em que se encontrava o computador Macintosh I-Mac de 360MHz e uma caixa de botões. Ao pressionar a tecla amarela na caixa de botões ao lado do computador, uma palavra era chamada à tela por 4 segundos, sendo, após esse lapso, automaticamente substituída por tela em que uma mesma letra aparecia em verde e em vermelho seguida de ponto de interrogação. Nos itens experimentais, esta letra era sempre a primeira letra do sufixo ou do pseudo-morfema. Nos distratores, esta letra estava em outras posições, no início ou no fim da palavra. Os participantes deveriam, então, escolher a cor da letra, apertando a tecla verde ou a tecla vermelha na caixa de botões. O programa Psyscope registrava, então, a decisão do sujeito, bem como os seus tempos de reação. Após sua decisão, os participantes deveriam apertar a tecla amarela para que outra palavra fosse chamada à tela, prosseguindo conforme descrito anteriormente até que todas as palavras tivessem sido apresentadas, o que era assinalado por uma última tela com a palavra FIM. As Figuras 4, 5 e 6, ilustram respectivamente a caixa de botões, a primeira tela em que uma palavra era apresentada e a segunda tela em que a cor de uma letra era perguntada.

Figura 4 - Caixa de botões.

Figura 5 - Exemplo de tela em que o estímulo era apresentado por 4 segundos.

Figura 6 - Exemplo de tela com pergunta sobre a cor de letra .
Resultados
Os resultados estão apresentados na Tabela 1 e nos Gráficos 1 e 2 abaixo. Observe-se que o índice de acertos na condição MPC é significativamente maior do que na condição MPN (X2=12,85; p = 0,0003) e que os tempos de decisão de acerto de MPC são significativamente mais rápidos do que os de MPN (t = 3,797; p = 0,0002), confirmando que há um efeito de recorte cromático atuante nas condições com morfemas. O recorte cromático dos morfemas foi, de fato, um fator facilitador nas decisões, fazendo aumentar o índice de acertos e diminuindo o tempo médio de decisão. Observe-se, em seguida, que o mesmo não se instancia na comparação PMC x PMN que apresentam índices de acerto (X2= 0,2800; p = 0,5967) e de tempos de decisão de acerto (t = 1,120; p = 0,264) indiferenciados. Finalmente, a comparação das últimas duas colunas entre si indica que o efeito do recorte cromático também se instancia significativamente ao se comparar MRC com MRN. O índice de acertos na condição MRC é significativamente maior do que na condição MRN (X2=14,74; p = 0,0001) e os tempos de decisão de acerto de MRC são significativamente mais rápidos do que os de RN (t = 4,645; p = 0,0001).
Tabela 1 - Índices de acerto e tempos de decisão por condição.
Gráfico 1 - Índices de acertos.
Gráfico 2 - Tempos de decisão.
Discussão
Os resultados obtidos indicam que os sujeitos reconhecem mais acertada e rapidamente a cor da letra alvo nas condições com recorte morfêmico, esteja o morfema em concatenação com uma palavra(MP) ou com uma raiz (MR). Por outro lado, não se observou efeito de recorte cromático significativo, quer nos índices, quer nos tempos de decisão acertada, nas condições com pseudo-morfema (PM).
Esses resultados sugerem que os leitores utilizariam um procedimento de parsing morfológico pleno, isolando os morfemas que compõem uma palavra, quer esses morfemas estejam em relação de transparência, quer estejam em relação de opacidade com a base. Nas condições com morfemas concatenados a palavras (MP), os leitores identificariam a palavra e o sufixo. Por exemplo, ao ler a palavra malinha, fariam a segmentação mala+inha para chegar ao significado "mala pequena". Também nas condições com morfemas concatenados diretamente à raiz (MR), esta segmentação se instanciaria. O que os resultados parecem estar indicando é que existe uma operação crucial de concatenação de morfema com raiz que ocasiona uma negociação de significado, a qual pode ser acrescida de mais uma concatenação, cujo aporte semântico regular é processado em tempo mínimo.
Crucialmente, no entanto, as condições com pseudo-morfemas em que não se observam efeitos significativos de recorte cromático, parecem sugerir que os leitores têm conhecimento intuitivo da morfologia, não segmentando morfemas quando há apenas material ortográfico não segmentável, como é o caso das palavras da lista PM. Por exemplo, ao ler a palavra espinha, derivada do latim spina, ae, o processador morfológico não seria ativadopara segmentar, reconhecer e fornecer a interpretação ilegítima "espi pequeno", uma vez que, nesse caso, não há morfema diminutivo a ser segmentado e processado, apenas material ortográfico semelhante que a competência lingüística do falante saberia diferenciar de um morfema verdadeiro.
Experimento 2 - Rastreamento ocular
Este experimento rastreou os movimentos oculares na leitura do mesmo conjunto de palavras do experimento anterior, sem, no entanto, incluir a manipulação cromática. A hipótese era a de que as palavras com morfemas, sejam as transparentes, sejam as opacas, apresentariam maiores tempos médios de fixação e maiores índices de movimentos sacádicos progressivos ou regressivos do que as palavras com pseudo-morfemas. Esses índices mais elevados de fixação e movimentação ocular nas condições com morfema refletiriam a atividade de concatenação morfêmica levada a efeito no processamento visual dessas palavras, em oposição ao acesso mais direto, a ser observado nas condições com pseudo-morfemas, em que não se esperariam níveis significativos de computação interna .à palavra. A literatura sobre rastreamento ocular da leitura reconhece não só que medidas de movimento ocular possam ser usadas para inferir processos cognitivos que variam de momento a momento na leitura, mas também que a variabilidade das medidas refletem o processamento on-line (cf. Rayner, 1983). Mais especificamente, Kuperman e colaboradores (2006) demonstraram que a complexidade morfológica na leitura de palavras isoladas em holandês implica maiores tempos de fixação.
Os três fatores da variável independente tipo de morfema (MP, PM e MR) são examinados no presente estudo, que tem como variáveis dependentes os tempos de fixação e os índices de movimentos sacádicos na leitura das palavras.
Materiais e métodos
Participantes
Participaram do experimento 16 alunos de graduação do curso de Fonoaudiologia da UFRJ, com visão normal, sem necessidade de uso de óculos ou lentes de contacto.
Materiais
Os materiais experimentais usados no estudo foram os mesmos usados no experimento 1, sem manipulação cromática: três listas de 14 palavras cada, controladas quanto à freqüência e tamanho, a saber, palavras com morfemas, pseudo-morfemas e morfemas renegociados.
Procedimentos
Os participantes foram testados individualmente em sala isolada, em que se encontravam o equipamento de rastreamento ocular Arrington View Point Quick Clamp Eye-tracker (CLIPSEN-CNPq), com resolução temporal de 30Hz (640x 480), ilustrado na Figura 7:
Figura 7 - Equipamento de rastreamento Ocular.
Os participantes foram instalados no equipamento a distância de cerca de 50 cms do monitor e instruídos a fazer leitura silenciosa auto-monitorada das palavras que íam chamando à tela através do pressionamento da tecla F-12 no teclado do computador Pentium IV 2,6GHz a que o rastreador ocular está conectado. As palavras grafadas em fonte times new roman 36 apareciam no centro da tela, ali permanecendo até que o sujeito apertasse a tecla F-12 novamente. Entre uma palavra e outra aparecia uma tela cinza vazia. A tarefa pedida aos sujeitos era a de que lessem as palavras para compreensão, sendo que ao final seriam testados quanto ao seu significado. A Figura 8 ilustra participante durante a realização do teste.

Figura 8 - Participante do experimento de rastreamento ocular.
Resultados
Os resultados estão apresentados na Tabela 2 e nos Gráficos 3 e 4 a seguir. Note-se que os tempos médios de fixação diferem significativamente entre morfemas concatenados diretamente a palavras (MP) e pseudo-morfemas (PM) na direção esperada (583 ms x 512ms), embora a diferença entre os índices de movimentos sacádicos, ainda que na direção esperada, seja apenas visual, não significativa estatisticamente (X2= 1,838; p = 0,1752). De qualquer forma, as palavras na condição MP, em que morfemas estão concatenados a palavras, requerem mais tempo de fixação (t = 2,936; p = 0,0034), atestando a maior atividade requerida pela decomposicão morfológica na leitura do primeiro grupo. Entretanto, diferentemente do obtido no Experimento 1, também se atestaram diferenças significativas dos tempos de fixação (t = 3.078; p = 0,0021) com a mesma magnitude e direção entre as palavras com morfemas concatenados a palavras (transparentes) e as palavras com morfemas concatenados a raízes (opacos), cujo significado é arbitrário. Já entre o grupo de palavras com pseudo-morfemas (PM) e o grupo de palavras com primeira concatenação na raiz (MR) não há diferenças significativas nos tempos de fixação (t = 0,1215; p = 0,9033).
Tabela 2 - Fixações e movimentos sacádicos.
Gráfico 3 - Tempos médios de fixação.
Gráfico 4 - Índices médios de movimentos sacádicos.
Discussão
Os resultados do experimento de rastreamento ocular sugerem uma correlação entre a computação morfológica no interior da palavra e os tempos de fixação médios - palavras com sufixos concatenados a palavras apresentam tempos de fixação médios mais elevados do que palavras com pseudo-morfemas, confirmando parcialmente a hipótese de que a concatenação morfêmica requer maiores latências, já que os índices de movimentação sacádica, embora apresentando médias na direção esperada, diferiram de forma estatisticamente não significativa. Observe-se que a diferença nos cruzamentos entre a condição com morfemas concatenados a palavras (MP) e a condição com pseudo-morfemas (PM) é simétrica às que foram obtidas no experimento 1, onde também se observaram diferenças significativas entre essas duas condições. A falta de simetria entre os dois experimentos, entretanto, se instancia ao se compararem as condições de palavras com morfemas concatenados a palavras (MP) com as condições de palavras com morfemas concatenados diretamente a raízes (MR), no teste de rastreamento ocular. Enquanto que neste último teste, há diferenças significativas nos tempos de fixação entre as duas condições, sugerindo que os dois grupos de palavras são processados diferentemente, no experimento 1, não se obtiveram diferenças significativas entre esses dois grupos, inferindo-se, ali, que a computação morfológica ocorria de modo idêntico, fossem os morfemas concatenados a palavras, fossem eles concatenados a raízes.
Uma forma de tentar explicar esta contradição entre os dois experimentos seria atribuir à natureza das tarefas a diferença encontrada entre os dois experimentos no que se refere ao grupo de palavras com concatenação de morfemas a raízes (MR) que, no primeiro experimento, se posicionaram ao lado do grupo de palavras com morfemas concatenados a palavras (MP) e, no segundo experimento, se alinharam melhor com o grupo de palavras com pseudo-morfemas. A tarefa de identificação cromática requeria que se destacassem com a mesma cor os morfemas, tanto no grupo onde havia tcomposição semântica regular (MP), quanto no grupo em que havia leitura semântica arbitrária (MR). Esse destaque do morfema pode ter funcionado como um artefato que ativou o procedimento computacional de concatenação morfológica em ambos os grupos, independentemente do significado ter sido fixado por computação composicional ou por fixação mnemônica semanticamente arbitrária. No grupo de pseudo-morfemas, embora as formas ortograficamente semelhantes a morfemas tenham também sido destacadas, os falantes não as teriam percebido como verdadeiros morfemas, não optando, por isso, pelo procedimento computacional e sim pelo acesso pleno (listema). Já no experimento de rastreamento ocular, em que não se deu destaque nem aos morfemas concatenados a palavras (MP), nem aos concatenados a raízes (MR) e nem aos pseudo-morfemas (PM), pôde-se capturar o acesso com base na computação morfológica apenas no grupo de palavras com morfemas concatenados a palavras, de leitura composicional (MP). Nos dois outros grupos, os leitores teriam optado pelo procedimento de listagem plena, menos custoso em termos de tempos de fixação. No grupo de pseudo-morfemas, o procedimento de acesso direto seria o único possível, uma vez que a computação levaria a resultado enganoso.
No grupo de morfemas concatenados a raízes (MR), embora o procedimento computacional fosse possível, não foi o preferido, provavelmente também por considerações de natureza econômica já que o acesso top-down é menos custoso computacionalmente e, por isso, menos demorado em termos de tempos de fixação. De qualquer modo, os experimentos parecem haver indicado a disponibilidade dos dois tipos de procedimentos de acesso lexical no processamento de palavras isoladas em português, o acesso direto e o mediado pela computação morfológica, aduzindo evidências em favor dos modelos duais ou de dupla rota. Constatam-se, então, dois procedimentos de acesso - o procedimento mnemônico e o computacional, o primeiro concernente à ativação da convenção arbitrária, que acontece na primeira concatenação de morfema categorizador a uma raiz acategorial e o segundo concernente ao cálculo da composição semântica, um cálculo que vai sendo efetuado logo após a primeira concatenação de afixo a raiz.
Note-se, finalmente, que após a realização do experimento de rastreamento ocular realizaram-se entrevistas com os participantes, indagando-se sobre a ocorrência e os significados de algumas palavras experimentais apresentadas no teste. Registre-se que ao menos uma das palavras experimentais do grupo dos morfemas opacos, a palavra mocinho, apresentou interpretações variáveis entre o sentido computado morfologicamente (moço+inho) e o sentido determinado mediante negociação semântica da estrutura Raiz+x (moc+inho). A maior parte dos sujeitos forneceu como primeira interpretação o sentido negociado, a saber, o de herói, oposto a bandido. Esta interpretação é consistente com o padrão de leitura do tipo top-down com menores índices de fixação e de movimentos sacádicos, ilustrado na Figura 9. Entretanto vários participantes também apresentaram como primeira interpretação o significado de moço jovem que teria resultado do procedimento bottom-up de concatenação da raiz com o sufixo diminutivo, o que poderia ter como correlato padrões de leitura com mais atividade ocular, como o ilustrado na Figura 10. A existência de tais variações sugerem que o controle mais preciso dessas acepções pode ser crucial para se estabelecer com maior precisão os processos de acesso lexical levados a efeito na leitura de palavras isoladas.
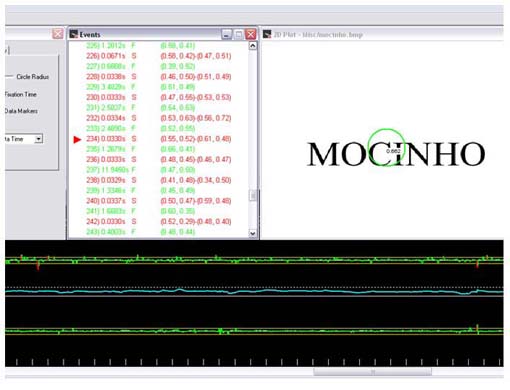
Figura 9 - Padrão de leitura top-down.
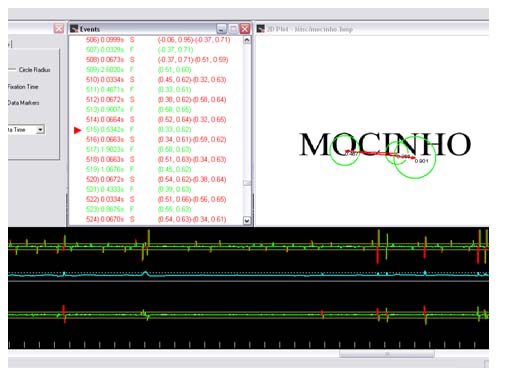
Figura 10 - Padrão de leitura bottom-up
Conclusões
Resumem-se abaixo as principais conclusões a que se chegou neste artigo:
Referências Bibliográficas
Butterworth, B. (1983) Lexical representation. Em: B. Butterworth. Language production (Vol.2, pp.257-294). London: Academic Press. [ Links ]
Caramazza, A.; Laudanna, A. e Romani, C. (1988) Lexical access and inflectional morphology. Cognition, 28, 297-332. [ Links ]
Chomsky, N. (1995). The minimalist Program. Cambridge, Massachutts: MIT Press. [ Links ]
Di Sciullo, A.M. e Williams, E. (1987). On the definition of word. Cambridge, Massachutts: MIT Press. [ Links ]
Halle, M. e Marantz, A. (1993). Distributed Morphology and the Pieces of Inflection. Em: The View from Building 20. Hale, K. e Keyser, S.J. (Ed.). Cambridge, Massachutts: MIT Press: 111-176.
Kuperman, H., Schreuder, R. e Baayen, H. (2006). An eye-tracking study of multiply complex Dutch compounds: Preliminary results. Manuscript. [ Links ]
Marslen-Wilson, W.; Tyler, L.K.; Waksler, R. e Older, L. (1994). Morphology and meaning in the English mental lexicon. Psychological Rev., 101(1), 3-33. [ Links ]
Pinker, S. (1991). Rules of language. Science, 153, 530-535. [ Links ]
Prinzmetal, W.; Treiman, R. e Rho, S.H. (1986). How to see a reading unit. Journal of Memory and Language, 25, 461-475. [ Links ]
Rayner, K. (1998). Eye Movements in Reading and Information Processing: 20 Years of Research. Psychological Bull., 124 (3), 372-422. [ Links ]
Schreuder, R. e Baayen, H. (1995) Modeli morphological processing. Em: Feldman, L.B. (Ed.). Morphological aspects of language processing (pp.131-154). Hillsdale, NJ: Erlbaum. [ Links ]
Seidenberg, M.S. e McClleland, J.L. (1989). A distributed, developmental model of word recognition and naming. Psychological Rev., 96(4), 523-568. [ Links ]
Stockall, L. e Maranz, A. (2006). A single route, full decomposition model of morphological complexity: MEG evidence.
Stroop, J.R. (1935). Studies of interference in serial verbal reactions. J. Exp. Psychol., 18, 643-662. [ Links ]
Taft, M. (1979). Lexical access via an orthographic code: the basic orthographic syllabic structure (BOSS). J. Verbal Learn. Verbal Behav., 18(1), 21-39. [ Links ]
Taft, M. e Forster, K.I. (1976). Lexical storage and retrieval of polymorphemic and polysyllabic words. J. Verbal Learn. Verbal Behav., 15(6), 607-620. [ Links ]
Taft, M. e Forster, K.I. (1975). Lexical storage and retrieval of prefixed words. J. Verbal Learn. Verbal Behav., 14(6), 638-647. [ Links ]
Taft, M. (1994). Interactive-activation as a framework for understanding morphological processing. Language Cogn. Proc., 9 (3), 271- 294. [ Links ]
Notas
M. Maia
Endereço para correspondência: Rua Evaldo Gonçalves, 151, Itaipu, Niterói, RJ 24355-060.
Telefone: (21) 2609-2919.
E-mail para correspondência: maiamarcus@gmail.com.
(1) Este trabalho foi apresentado originalmente na mesa redonda "Restaurar dá restaurante? Analisando a persistência da morfologia no acesso lexical", coordenada por Miriam Lemle (Clipsen/UFRJ), durante o V Congresso Internacional da Associação Brasileira de Lingüística - ABRALIN, realizado na UFMG, em Belo Horizonte, entre os dias 28 de fevereiro e 3 de março de 2007.
(2) O processamento morfológico é um processo sublexical que equivale à concatenação sucessiva de raiz e morfemas categorizadores em prol da formação de uma palavra. Por exemplo, a palavra rastreamento é morfologicamente complexa. É formada a partir da raiz RASTR que se combina com o morfema nominalizador à (sem forma fonológica) e se torna o nome rastro. Depois, rastro se concatena com o morfema verbalizador e forma rastrear. Por fim, o verbo rastrear se concatena a um morfema nominalizador com forma fonológica mento em prol da palavra [[[rastr]nea]vmento]n.
(3) Heurísticas top down no acesso lexical parecem sempre poder ocorrer, sendo, até certo ponto, imprevisíveis, pois variam em função de fatores tão diversos quanto a freqüência, a familiaridade, a similaridade semântica, prosódica, fonética, ortográfica, etc. Por exemplo, recentemente, pudemos observar alguém recuperar o nome de um grupo de mímicos denominado Mummenshantz, como Haagendaz. Pode-se especular que o acesso se deveu a fatores tão diversos quanto o número de sílabas, a pauta acentual, bem como, talvez, à percepção de que se tratava de termo em língua estrangeira.

{kind=link}