










Serviços Personalizados
Journal

artigo
 Português (pdf)
Português (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
Indicadores
Compartilhar

 Permalink
PermalinkInteramerican Journal of Psychology
versão impressa ISSN 0034-9690
Interam. j. psychol. v.42 n.3 Porto Alegre dez. 2008
O efeito de vizinhança ortográfica em crianças brasileiras: estudo com a tarefa de decisão lexical
The effect of orthographic neighborhood in brazilian children: lexical decision task study
Francis Ricardo dos Reis JustiI,1,2; Ângela Maria Vieira PinheiroII
IUniversidade Federal de Alagoas, Maceió, Brasil
IIUniversidade Federal de Minas Gerais, Belo Horizonte, Brasil
RESUMO
Nesse estudo, foram realizados dois experimentos para investigar o efeito de vizinhança ortográfica no reconhecimento de palavras, em crianças brasileiras da quarta série do ensino fundamental. No primeiro experimento, uma tarefa de decisão lexical do tipo Go/No-Go, observou-se um efeito inibitório do número de vizinhos (N) e do número de vizinhos de maior freqüência que a da palavra-alvo (NF). No segundo, uma tarefa de decisão lexical com tempo fixo, observou-se um efeito inibitório de NF. Em estudos com adultos, porém, efeitos facilitadores de N foram observados. Verificou-se que o efeito de vizinhança ortográfica é genuinamente inibitório no português do Brasil e que crianças, ao contrário de adultos, podem ter dificuldades em utilizar estratégias na tarefa de decisão lexical.
Palavras-chave: Vizinhança ortográfica; Reconhecimento visual de palavras; Tarefa de decisão lexical.
ABSTRACT
In this study two experiments were developed to investigate the orthographic neighborhood effect on word recognition in 4th grade Brazilian Portuguese speaking school children. In the first, a lexical decision task of the Go/No-Go type was conducted, controlling the lexical activation index of words and pseudowords, an inhibitory effect of the number of neighbors (N) and of the number of neighbors of greater frequency than the target word (NF) was observed. In the second, a lexical decision task under a time-limit, the stimuli were presented briefly (250 ms) followed by a mask and the speed of the responses was emphasized. Compared with previous studies with adults in which, in these conditions, facilitative effects of N were observed, in this second experiment, the children continued to show an inhibitory effect of NF. It was argued that the orthographic neighborhood effect is genuinely inhibitory for Brazilian Portuguese and children, in contrast to adults, can present difficulties in employing strategies in the lexical decision task.
Keywords: Orthographic neighborhood; Visual word recognition; Lexical decision task.
Pode-se dizer que, pelo menos, dois processos estão envolvidos na leitura: o acesso lexical e a compreensão. O acesso lexical se refere ao acesso à representação mental das palavras que reconhecemos em um texto. A compreensão ao conjunto de processos inter-relacionados por meio dos quais o leitor constrói uma representação do significado do texto (Perfetti, 1985).
O foco desse trabalho é sobre o processo de acesso lexical e sendo assim, mais uma distinção torna-se relevante. De acordo com Monsell, Doyle e Haggard (1989), é possível distinguir entre transcodificação lexical e identificação lexical. A transcodificação lexical refere-se à geração de um código no sistema semântico ou fonológico a partir de um input. Uma etapa desse processo de transcodificação seria a seleção da forma ortográfica no léxico mental que melhor corresponde ao estímulo-alvo. Esse processo de seleção, é denominado identificação lexical. Nesse sentido, uma das principais tarefas que o nosso sistema cognitivo desempenha durante o acesso lexical, é a seleção da unidade lexical correta diante das diversas unidades que podem ser ortograficamente similares ao estímulo-alvo. Dentro da tradição de pesquisas sobre o reconhecimento visual de palavras, o efeito que as palavras similares em termos ortográficos desencadeiam no processo de reconhecimento de um estímulo-alvo, é conhecido por efeito de vizinhança ortográfica e tem sido questão bastante estudada na literatura sobre o tópico (Andrews, 1989, 1992, 1997; Carreiras, Perea, & Grainger, 1997; Coltheart, Davelaar, Jonasson, & Besner, 1977; Grainger, O’Regan, Jacobs, & Segui, 1989; Huntsman & Lima, 1996, 2002; Laxon, Masterson, Pool, & Keating, 1992; Perea, Carreiras, & Grainger, 2004; Perea & Pollatsek, 1998; Perea & Rosa, 2000; Sears, Hino, & Lupker, 1995; Snodgrass & Minzer, 1993; entre outros).
A principal tentativa de se definir as palavras que seriam similares em termos ortográficos a uma palavra-alvo consiste em considerar como vizinhos ortográficos da palavra-alvo, qualquer palavra que possa ser criada ao se mudar uma letra dessa, enquanto se preservam as posições das demais letras. Desse modo, a palavra ‘alma’ teria cinco vizinhos ortográficos (‘arma’, ‘asma’, ‘alga’, ‘alça’ e ‘alta’). Essa pode ser considerada a definição mais tradicional de uma palavra vizinha (ou similar em sua forma ortográfica) e é atribuída a Coltheart et al. (1977). O número de palavras que pode ser criado utilizando esse processo proposto por Coltheart et al. (1977) é chamado de medida N (de neighbourhood, em inglês) e se refere ao número de vizinhos de uma palavra-alvo. Além dessa medida, nos estudos sobre o efeito de vizinhança ortográfica, também se tem utilizado a medida NF (de neighbourhood frequency, em inglês) que se refere à freqüência de ocorrência dos vizinhos de uma palavra-alvo, ou seja, se ela possui vizinhos de freqüência maior do que a dela ou não (Grainger et al., 1989). A operacionalização dessas medidas (N e NF) tem o intuito de permitir aos pesquisadores estabelecerem se o efeito de vizinhança ortográfica seria facilitador ou inibitório. Assim sendo, se o efeito de vizinhança ortográfica for facilitador, então o reconhecimento de palavras com um grande número de vizinhos ou com pelo menos um vizinho de maior freqüência será realizado mais rapidamente; se o efeito for inibitório, o contrário se verificará, ou seja, as palavras nessa condição serão reconhecidas mais lentamente.
Atualmente as pesquisas sobre o efeito de vizinhança ortográfica têm se revestido de grande importância teórica (Andrews, 1997). Uma das razões para isso é que muitos modelos de reconhecimento de palavras postulam a existência de um "dicionário mental" (léxico ortográfico) no qual armazenaríamos as representações lexicais das formas ortográficas das palavras que encontramos ao ler (Coltheart, Rastle, Perry, Langdon, & Ziegler, 2001; Grainger & Jacobs, 1996; McClelland & Rumelhart, 1981; Murray & Forster, 2004; Paap & Johansen, 1994). Os estudos sobre o efeito de vizinhança ortográfica são importantes porque podem ajudar a revelar a dinâmica do processo de acesso a essas representações lexicais (Perea & Rosa, 2000). Por exemplo, esse processo implicaria em uma espécie de "competição" entre as unidades lexicais que fossem similares ao estímulo-alvo, como parece acontecer nos modelos de McClelland e Rumelhart (1981), Grainger e Jacobs (1996) e Coltheart et al. (2001)? Ou, esse processo, se assemelharia a uma busca serial em um conjunto de unidades lexicais similares ao estímulo-alvo, como proposto por Murray e Forster (2004) e Paap e Johansen (1994)? Ou ainda, de forma mais radical, deveríamos abandonar a idéia de um léxico ortográfico composto por unidades, em prol da idéia de que as representações dessas palavras se assemelhariam a padrões de ativação distribuídos em uma rede de unidades mais simples, como nos modelos de Seidenberg e McClelland (1989) e de Plaut, Seidenberg, McClelland e Patterson (1996)?
Os estudos sobre o efeito de vizinhança ortográfica ajudariam a responder tais questões, porque certos efeitos seriam mais naturalmente acomodados por um modelo do que por outro. Por exemplo, um efeito inibitório seria mais naturalmente acomodado pelos modelos de McClelland e Rumelhart (1981), Grainger e Jacobs (1996) e Coltheart et al. (2001), enquanto um efeito facilitador seria mais natural nos modelos de Seidenberg e McClelland (1989) e Plaut et al. (1996), conforme demonstrado nas simulações computacionais de Grainger e Jacobs (1996) e de Sears, Hino e Lupker (1999).
As tarefas de decisão lexical (TDL) têm sido consideradas as tarefas mais adequadas para se investigar o acesso ao léxico e conseqüentemente, estão entre as tarefas mais utilizadas para se investigar o efeito de vizinhança ortográfica (Andrews, 1997)3. Nesse tipo de tarefa, os sujeitos têm que decidir se um conjunto de letras é uma palavra ou não. Para isso, a tarefa consiste na apresentação de um conjunto de letras (estímulo), geralmente no centro da tela de um computador. Uma vez que o estímulo tenha aparecido, o sujeito deve apertar a tecla "sim", caso o conjunto de letras apresentado seja uma palavra e a tecla "não", caso seja uma pseudo-palavra (seqüência de letras, construída com estrutura ortográfica possível na língua em questão, mas não associada a nenhum significado).
Utilizando-se da tarefa de decisão lexical para investigar o efeito de NF no reconhecimento de palavras, Grainger et al. (1989) observaram um efeito inibitório dessa variável no reconhecimento de palavras em falantes da língua francesa. Esse efeito foi replicado em um estudo posterior por Grainger e Segui (1990), mas em um outro estudo, Grainger, O’Reagan, Jacobs e Segui (1992) observaram um efeito inibitório apenas quando os vizinhos de maior freqüência do que a da palavra-alvo, diferiam dessa, em uma de suas letras mediais. Isso indica que a posição em que a palavra tem vizinhos de maior freqüência, pode influenciar no papel da variável NF e que, talvez, as letras interiores de uma palavra, sejam menos processadas que as letras nas posições iniciais e finais. Em pesquisas em que os vizinhos com maior freqüência de ocorrência do que a da palavra-alvo diferiam dessa em uma de suas letras mediais, o efeito inibitório de NF também foi replicado em falantes do holandês (Grainger, 1990) e do espanhol (Carreiras et al., 1997).
Pesquisando falantes da língua inglesa, Huntsman e Lima (1996) controlaram o número de vizinhos (N) de palavras-alvo e manipularam NF na tentativa de observar o efeito dessa variável no reconhecimento de palavras. Corroborando os resultados das pesquisas anteriores em outras línguas, Huntsman e Lima (1996) encontraram um efeito inibitório de NF. Também encontraram um efeito inibitório de NF, Perea e Pollatsek (1998), sendo importante mencionar que nesse estudo, como no estudo de Grainger et al. (1992), os vizinhos de maior freqüência diferiam da palavra-alvo em uma de suas letras mediais. Em um estudo de Pugh, Rexer, Peter e Katz (1994), uma letra do meio da palavra-alvo aparecia cem milésimos de segundo depois das outras letras dessa palavra. Eles avaliaram duas condições: em uma delas, a letra que demorava a aparecer não apresentava ambigüidade (não se formavam, a partir da mudança dessa letra, nenhum vizinho de freqüência maior do que a da palavra-alvo) e na outra condição, essa letra apresentava ambigüidade (podia-se formar um vizinho de maior freqüência nessa posição). Condizente com um efeito inibitório de NF, esses autores observaram que, a condição em que a letra ambígua demorava a aparecer, gerava mais erros e respostas mais demoradas nos sujeitos, em comparação com a condição em que a letra não ambígua demorava a aparecer. Em um outro experimento, esses pesquisadores dividiram as pseudopalavras em duas condições: pseudopalavras com poucos vizinhos e pseudopalavras com muitos vizinhos. Pôde-se observar que o efeito de NF só foi inibitório quando as pseudopalavras tinham muitos vizinhos, do contrário, esse era nulo. Sendo assim, pode ser que o efeito de NF varie de acordo com a constituição das pseudopalavras do experimento também.
O efeito de NF, então, parece razoavelmente consistente na tarefa de decisão lexical. Porém, alguns estudos realizados com falantes da língua inglesa têm apresentado resultados conflitantes com os dos estudos anteriores. Por exemplo, Andrews (1989, 1992) manipulando o número de vizinhos (N) e a freqüência de ocorrência das palavras-alvo, observou um efeito facilitador de N para as palavras de baixa freqüência na tarefa de decisão lexical. Mesmo não tendo manipulado NF, esses resultados podem ser considerados inconsistentes com os anteriores, pois N e NF se correlacionam positivamente na língua inglesa, isso é, um grande número de vizinhos geralmente implica, pelo menos, um vizinho de maior freqüência que a da palavra-alvo (Andrews, 1997). Em experimentos manipulando, tanto N, quanto NF, Huntsman e Lima (2002) observaram um efeito facilitador de N e um efeito nulo de NF em falantes do inglês. Pesquisando falantes dessa mesma língua, em uma série de experimentos Sears et al. (1995) obtiveram efeitos facilitadores de N e até mesmo, de NF. No entanto, em um experimento onde as pseudopalavras tinham muitos vizinhos, esses pesquisadores não obtiveram efeitos consistentes, nem de N e nem de NF.
Para Carreiras et al. (1997), essa inconsistência nos resultados seria apenas aparente e os efeitos facilitadores de N seriam provenientes do uso de uma estratégia de "adivinhação". Os estudos que demonstraram um efeito facilitador de N também apresentaram tempos de reação menores e um maior número de erros, em comparação com os estudos que reportaram efeitos inibitórios de NF. Para esses autores, isso indicaria que os pesquisadores, nesses experimentos, incentivaram os participantes a dar respostas rápidas (enfatizando o tempo de reação). Com isso, podem ter induzido à adoção de uma estratégia de adivinhação rápida (fast guess strategy), em que os participantes emitiam uma resposta sem, necessariamente, completar todos os processos envolvidos no acesso lexical. Desse modo, o desempenho na tarefa de decisão lexical poderia sofrer influências de estratégias extralexicais, como haviam argumentado anteriormente Balota e Chumbley (1984).
No Modelo de Leitura Múltipla de Grainger e Jacobs (1996) e no Modelo de Dupla Rota em Cascata de Coltheart et al. (2001), a estratégia de adivinhação rápida pode ser interpretada como o que interessa é responder o mais rápido possível, o sistema de acesso lexical não completa o processo de seleção da representação lexical (identificação da palavra-alvo no léxico de input ortográfico), mas sim, estabelece um limiar de ativação no sistema, a partir do qual, uma resposta positiva será emitida e, se em um determinado período de tempo este limiar não é atingido, o sistema emite uma resposta negativa. Desse modo, um grande número de vizinhos aumenta a ativação do sistema lexical como um todo, fazendo com que a resposta positiva seja, rapidamente, emitida. Como as pseudopalavras têm um nível de ativação menor, o limiar não é atingido a tempo e a resposta negativa é emitida, fazendo com que essa estratégia funcione razoavelmente bem. No entanto, quando a acurácia é enfatizada e as pseudopalavras do experimento têm um grande número de vizinhos, essa estratégia tende a falhar e, conseqüentemente, não vem a ser usada.
Tendo o modelo de Grainger e Jacobs (1996) em mente, Justi e Pinheiro (2006) desenvolveram dois experimentos para avaliar se os efeitos de N e NF podem ser modulados na tarefa de decisão lexical de acordo com a possibilidade de se usar ou não a estratégia de adivinhação rápida. Justi e Pinheiro (2006) investigaram o desempenho de estudantes de psicologia falantes do português do Brasil, em duas versões da tarefa de decisão lexical. Na primeira delas, utilizaram uma tarefa de decisão lexical do tipo Go/No-Go, onde só se requer que o sujeito responda às palavras. Nessa tarefa, o índice de ativação lexical das palavras e pseudopalavras foi equiparado de modo que os sujeitos não pudessem usar a discrepância entre esses índices para estabelecer um limiar de resposta que permitisse o uso da estratégia de adivinhação rápida. Nesse experimento, Justi e Pinheiro (2006) observaram um efeito inibitório de NF quando as palavras tinham poucos vizinhos e um efeito inibitório de N quando as palavras não tinham vizinhos de maior freqüência. O segundo experimento, visava incentivar o uso da estratégia de adivinhação rápida. Para isso, Justi e Pinheiro (2006) utilizaram uma tarefa de decisão lexical com tempo fixo, limitando o tempo de apresentação dos estímulos a 150 milésimos de segundo e empregaram pseudopalavras com um baixo índice de ativação lexical. Nesse experimento, observou-se um efeito facilitador de N na análise de erros (isso é, os estímulos com muitos vizinhos geraram uma menor porcentagem de erros) e uma tendência facilitadora de NF que não chegou a ser estatisticamente significativa. Essa inversão no padrão dos resultados entre os experimentos (da inibição a facilitação) foi interpretada como um indício de que o efeito de N e NF realmente pode ser modulado pelo uso da estratégia de adivinhação rápida. Além disso, esses pesquisadores postularam que, no português do Brasil, o efeito de N e NF no processo de identificação lexical é genuinamente inibitório.
Nota-se que, apesar de observarem uma inversão no padrão de resultados em seus dois experimentos, a afirmação de Justi e Pinheiro (2006) de que o efeito de vizinhança ortográfica é inibitório em falantes do português do Brasil é fundamentada apenas teoricamente. É com base nas predições do modelo de Grainger e Jacobs (1996) que os autores argumentaram que no seu primeiro experimento (tarefa de decisão lexical do tipo Go/No-Go) o acesso lexical estava mais envolvido e que no segundo (tarefa de decisão lexical com tempo fixo) os sujeitos, provavelmente, utilizaram a estratégia de adivinhação rápida. No entanto, embora possa parecer um pouco contra-intuitivo, pode se argumentar que o alto índice de ativação lexical das pseudopalavras empregadas no primeiro experimento levou os sujeitos a retardar "estrategicamente" suas respostas e, nesse sentido, o experimento não envolveria acesso lexical genuíno. Desse modo, é necessária uma fonte de evidências independente para ser decidido qual dos experimentos envolve acesso lexical genuíno.
O estudo de Justi e Pinheiro (2006), como a maioria dos estudos discutidos até então, foi realizado com estudantes de psicologia. Nesse caso, os sujeitos de seu estudo têm uma alta probabilidade de já terem tido algum contato com a tarefa de decisão lexical, o que por sua vez, pode ter facilitado o uso de estratégias. Se além dos cuidados metodológicos tomados por Justi e Pinheiro, um estudo fosse desenvolvido com sujeitos que nunca tiveram contato com a tarefa de decisão lexical, a probabilidade de que esses sujeitos viessem a utilizar qualquer estratégia seria ainda menor.
Tendo essas considerações em mente, o presente estudo empregou a metodologia desenvolvida por Justi e Pinheiro (2006) para estudar os efeitos de vizinhança ortográfica em crianças da quarta série do Ensino Fundamental falantes do português do Brasil. Esse estudo baseou-se na hipótese auxiliar de que por nunca terem tido contato com a tarefa de decisão lexical essas crianças seriam menos propensas a empregar estratégias sofisticadas como a de adivinhação rápida nessa tarefa. Sendo assim, pode-se comparar o padrão de desempenho das crianças com o padrão de desempenho dos adultos do estudo de Justi e Pinheiro (2006). Se o efeito de vizinhança ortográfica for genuinamente inibitório no português do Brasil, é provável que N e NF apresentem um efeito inibitório também em crianças. Se o acesso lexical genuíno está presente na tarefa de decisão lexical do tipo Go/No-Go, como argumentam Justi e Pinheiro (2006), então, ao desempenhar essa tarefa, as crianças devem apresentar o mesmo padrão de respostas que os adultos apresentaram (isso é, um efeito inibitório de N e NF). Se for na tarefa de decisão lexical com tempo fixo que devemos observar os efeitos da estratégia de adivinhação rápida, é possível que as crianças apresentem um padrão de respostas diferente do padrão apresentado pelos adultos estudados por Justi e Pinheiro (2006).
Método
Amostra
Participaram do estudo 68 alunos do segundo ciclo (equivalente à 4a série do Ensino Fundamental) do Centro Pedagógico da Universidade Federal de Minas Gerais (UFMG) Belo Horizonte/BR. Esses foram divididos aleatoriamente em dois grupos de 34 participantes. Um grupo foi alocado ao primeiro experimento, realizando a tarefa de decisão lexical do tipo Go/No-Go. O outro grupo participou do segundo experimento, realizando a tarefa de decisão lexical com tempo fixo. Essa pesquisa foi aprovada pelo Comitê de Ética em Pesquisa da UFMG - COEP (parecer ETIC 438/04).
Experimento I Tarefa de Decisão do Tipo Go/No-Go
Conforme discutido anteriormente, de acordo com os modelos de Coltheart et al. (2001) e de Grainger e Jacobs (1996), uma resposta pode ser emitida na tarefa de decisão lexical de três maneiras: por meio do nível de ativação geral do sistema lexical (estratégia de adivinhação rápida); por meio de um limite de tempo para a resposta "não" (estratégia deadline); e finalmente, por meio de identificação lexical (quando o nível de ativação da unidade lexical correspondente à palavra-alvo atinge um limiar de ativação que lhe é próprio no sistema lexical). Como seria possível, então, garantir que uma resposta emitida na tarefa de decisão lexical dependa exclusivamente do processo de identificação lexical?
Existe uma versão da tarefa de decisão lexical conhecida como tarefa de decisão lexical do tipo Go/No-Go (Go/No-Go lexical decison task). Nessa tarefa, os participantes têm que apertar uma tecla quando um conjunto de letras for uma palavra e não apertar tecla alguma quando for uma pseudopalavra. Como a estratégia deadline opera apenas para as respostas "não" na tarefa padrão, na versão Go/No-Go, o seu uso fica impossibilitado, pois apenas as respostas "sim" são requeridas (Justi & Pinheiro, 2006; Perea, Rosa, & Gómez, 2003).
De acordo com Grainger e Jacobs (1996), a estratégia de adivinhação rápida tem como base o nível de ativação geral do sistema lexical para gerar a resposta "sim" e só funciona porque, na maioria das vezes, o nível de ativação lexical gerado por uma palavra e seus vizinhos excede, consideravelmente, o nível de ativação lexical gerado pelos vizinhos das pseudopalavras. Sendo assim, para que o uso dessa estratégia seja impedido, basta que se selecione para o experimento pseudopalavras que tenham um índice de ativação lexical tão alto quanto o das palavras. De acordo com Justi e Pinheiro (2006), esse controle pode ser obtido por meio do pareamento da soma da freqüência de ocorrência das palavras-alvo e de seus vizinhos (FS-PV), com a soma da freqüência de ocorrência dos vizinhos das pseudopalavras (FS-V). Isso é, utilizando pseudopalavras que tenham muitos vizinhos e que, desse modo, possam gerar tanta ativação lexical quanto à das palavras do experimento. Assim sendo, ao tentar utilizar a estratégia de adivinhação rápida o participante obterá um índice de erros grande e, provavelmente, abdicará de utilizar essa estratégia em prol da identificação completa do estímulo-alvo (acesso lexical genuíno).
Participantes
Participaram desse experimento um dos dois grupos de 34 crianças da amostra total descrita.
Material
As palavras-estímulo do presente estudo foram retiradas do estudo de Justi e Pinheiro (2006), tendo as seguintes características: são substantivos, têm cinco letras, são regulares para a leitura e têm baixa freqüência de ocorrência (de acordo com a contagem de freqüência ocorrência de palavras efetuada por Pinheiro em 1996). Além disso, as palavras que compuseram as condições experimentais foram selecionadas de acordo com uma manipulação fatorial de N e NF, onde cada um desses fatores tinha dois níveis. Os dois níveis de N correspondiam a "de um a dois vizinhos" e "quatro ou mais vizinhos", enquanto os dois níveis de NF correspondiam a "sem vizinhos de maior freqüência" e "pelo menos um vizinho de maior freqüência". As pseudopalavras que compuseram esse experimento também foram retiradas do trabalho de Justi e Pinheiro (2006) e são equivalentes às palavras-estímulo no que diz respeito ao seu índice de ativação lexical (pareou-se a soma da freqüência de ocorrência das palavras-alvo e de seus vizinhos FS-PV à soma da freqüência de ocorrência dos vizinhos das pseudopalavras FS-V). Os 24 estímulos utilizados na sessão de treinamento exibiram as mesmas características dos estímulos experimentais. Os estímulos (palavras e pseudopalavras) utilizados nesse experimento encontram-se no Anexo A.
Procedimentos
Os participantes foram testados em uma sala do Centro Pedagógico da UFMG que consistia em um ambiente silencioso e de luz fraca. Eles entravam em grupos de dois a três, porém cada um desempenhava o teste individualmente em um computador. Os instrumentos utilizados para a testagem foram três computadores portáteis de arquitetura compatível à IBM PC e o software utilizado para a apresentação dos estímulos e a coleta dos dados de tempo de reação foi o Mel Professional Version 2.0 (Schneider, 1988). A apresentação dos estímulos obedeceu, tanto para a sessão de treinamento, quanto para a experimental, aos seguintes parâmetros: (a) uma marca de fixação (+) aparecia no centro da tela por 500 milessegundos (ms); (b) após um intervalo de 200 ms o estímulo-alvo (que podia ser uma palavra ou uma pseudopalavra), em letras minúsculas, era apresentado e permanecia na tela por 2500 ms, ou, até que o sujeito pressionasse a barra de espaço, o que deveria ocorrer, caso o estímulo fosse uma palavra. Os estímulos foram apresentados em ordem aleatória para cada sujeito e o intervalo entre o término da apresentação de um estímulo e o início da apresentação de outro (iniciando-se com a marca de fixação) foi de 800 ms. Além disso, os estímulos seguiam a fonte padrão do MS DOS (tamanho 14), sendo de cor branca em um fundo preto.
O procedimento de testagem durou aproximadamente 15 minutos para as sessões de treinamento e experimental. Os participantes sentavam-se diante dos computadores a uma distância de, aproximadamente, 40 centímetros e recebiam a seguinte instrução:
Nesse teste você verá esse sinal + no centro da tela. Logo após, você verá uma palavra ou uma palavra de mentira. Aperte a barra de espaço quando for uma palavra. Tente acertar o máximo possível, mas também tente ser rápido.
Após receberem essas instruções, os participantes eram inquiridos sobre o seu conteúdo para confirmar se o compreenderam e também para redimir quaisquer dúvidas que pudessem ter. Então, finalmente, eram instruídos a iniciar, todos juntos, a sessão de treinamento que, diferentemente da sessão experimental, contava com feedback sobre a correção das respostas emitidas. Ao término dessa sessão, os participantes eram convidados a iniciar a sessão experimental.
Resultados
No presente trabalho, as palavras (itens) em cada condição experimental, representam uma população maior de palavras que, igualmente, poderiam estar compondo o experimento e para a qual se deseja generalizar os resultados (por exemplo: palavras de baixa freqüência com N maior que quatro e NF igual a zero). Segundo Clark (1973), o teste estatístico adequado para a análise dos dados de experimentos que fazem uso de itens verbais, como é o caso desse experimento, seria um que tratasse, tanto os itens, quanto os sujeitos, como fatores aleatórios. De acordo com Clark (1973), a maneira mais prática de se fazer tal teste é através do cálculo de min F’.
Para se calcular min F’, é necessário efetuar duas análises de variância: uma análise de sujeitos (F1) e uma análise de itens (F2). Na primeira, calcula-se a média de tempo de reação (TR) dos sujeitos para o conjunto de itens de cada condição experimental e faz-se a análise estatística dessas médias, obtendo-se o valor F1. Na segunda, calcula-se a média de TR dos sujeitos para cada item e a análise estatística é feita nas médias resultantes para se obter o valor F2. Obtidos F1 e F2, min F’ (i, j) é dado pela fórmula F1 x F2 / (F1 + F2). Os graus de liberdade (i, j) de min F’ também são calculados em termos de F1 e F2: se F1(n, n1) e F2(n, n2), i será igual a n e j será o número inteiro mais próximo do resultado de (F1 + F2)2 / (F12/n2 + F22/n1). Seguindo as recomendações de Clark (1973), no presente estudo, em todas as análises que se seguem, empregou-se o cálculo de min F’ para efetuar os testes de hipóteses e rejeitou-se a hipótese nula sempre que p< 0,05.
Todos os escores de um participante que se desviaram de sua média, por mais de dois desvios-padrão em qualquer direção, foram limitados a esse valor (Perea, 1999). Esse procedimento alterou 4,96% dos escores desse experimento. A Tabela 1 apresenta a média e o desvio-padrão do Tempo de Reação (TR) dos participantes para cada condição experimental.
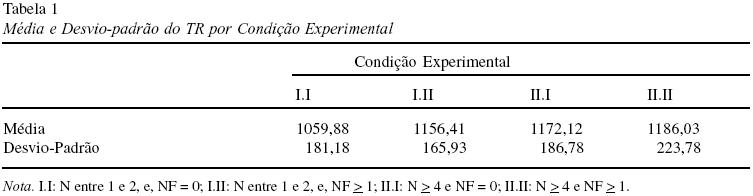
Como podemos observar na Tabela 1, o TR dos participantes aumenta à medida que os valores de N e de NF aumentam, indicando um efeito inibitório dessas variáveis. O efeito geral de N foi estatisticamente significativo [min F’ (1,80) = 4,08], porém o efeito geral de NF e a interação N x NF não o foram (ambos min F’ < 3). O efeito de NF foi específico [min F’ (1,43) = 5,17] às condições em que N tinha seus menores valores (cond. I.I x I.II).
O índice de erros no presente experimento foi de 6,39%, permitindo uma análise estatística da porcentagem de erros por condição experimental. A mesma tendência inibitória que observamos na análise do TR, foi mantida na análise dos erros, como se pode observar na Tabela 2.
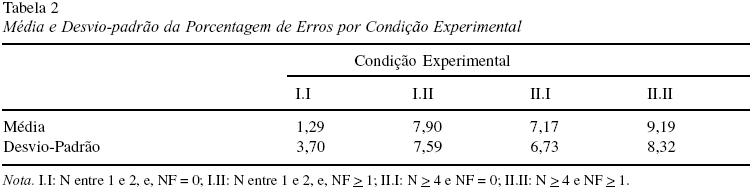
Na análise de erros, o efeito geral de NF foi estatisticamente significativo [min F’ (1,88) = 4,71], porém o efeito geral de N não o foi [min F’ (1,84) = 3,42] e nem a interação N x NF [min F’ (1,92) = 1,23]. O efeito de N foi específico [min F’ (1,55) = 9,18] às condições em que NF era igual a zero (cond. I.I x II.I).
Discussão
Justi e Pinheiro (2006), que aplicaram a tarefa de decisão do tipo Go/No-Go em adultos, concluíram que o acesso lexical, nessa tarefa, ocorre de forma genuína. Tal como nos adultos, esperou-se aqui encontrar também nas crianças um efeito inibitório, tanto de N, quanto de NF. O presente experimento corroborou essa expectativa. No entanto, observou-se um efeito geral de N e um efeito específico de NF na análise do tempo de reação (TR), sendo que esse padrão se inverteu na análise de erros. Esse resultado pode ser explicado pelo fato de, no presente experimento, a média de TR ter sido relativamente alta (1144 ms), o que pode indicar que os participantes mais lentos possam ter tido algumas respostas próximas do limite máximo permitido (lembre-se que nesse experimento após 2500 ms o estímulo desaparecia). Se o efeito de NF for inibitório como parece ser, é esperado que os participantes mais lentos, diante de palavras com vizinhos de maior freqüência, possam ter retardado algumas de suas respostas a ponto de exceder o limite de tempo. Desse modo, essas respostas resultariam em erros e seriam excluídas da análise do TR. Isso faria com que os maiores TRs, provenientes do efeito de NF, não entrassem no cômputo de sua média, reduzindo-a. Daí não se observar um efeito geral estatisticamente significativo de NF na análise do TR, mas apenas na análise de erros. Como N gerou menos erros (aproximadamente 8% de erros para N e 9% de erros para NF), o TR dessa condição foi menos afetado pela exclusão de valores "potencialmente" altos, tornando assim sua média final maior. Ao mesmo tempo, o menor índice de erros obtido, pode ter feito com que o efeito de N se restringisse às condições em que NF era igual a zero, na análise de erros.
Experimento II Tarefa de Decisão Lexical com Tempo Fixo
Nesse experimento, o objetivo foi observar se os efeitos de N e NF poderiam ser modulados pelo uso da estratégia de adivinhação rápida. Uma tarefa de decisão lexical tradicional foi utilizada e para "incentivar" o uso da estratégia de adivinhação rápida. Os seguintes procedimentos foram adotados: pseudopalavras com um baixo índice de ativação lexical foram utilizadas; os estímulos foram apresentados brevemente (250 ms) e depois mascarados; enfatizou-se a rapidez das respostas em detrimento da acurácia (Coltheart et al., 2001; Grainger & Jacobs, 1996; Justi & Pinheiro, 2006; Perea, Carreiras et al., 2004; Perea, Rosa et al., 2003).
Segundo Perea, Rosa et al. (2003), enquanto a utilização de pseudopalavras com um baixo índice de ativação lexical visa induzir o sujeito a estabelecer um limiar de resposta para a estratégia de adivinhação rápida, a redução do tempo de apresentação do estímulo desencoraja a identificação lexical completa da palavra, uma vez que esse último processo é mais demorado e o estímulo desaparece muito rapidamente. Assim, ao serem incentivados a responder o mais rápido possível, os participantes podem ser encorajados a utilizar a estratégia de adivinhação rápida, posto que ela será bem sucedida devido ao baixo índice de ativação lexical das pseudopalavras.
Participantes
Dentre os participantes selecionados para participar desse experimento (o outro grupo de 34 crianças pertencente à amostra total), quatro deles não compareceram durante o período de testes. Conseqüentemente, não participaram do experimento, ficando essa amostra restrita a 30 crianças.
Material
Nesse segundo experimento, foram utilizadas as mesmas 64 palavras que correspondiam às condições experimentais do primeiro experimento, mas as pseudopalavras utilizadas foram diferentes. Pseudopalavras ilegais (pseudopalavras que desrespeitam as regras de construção ortográfica de palavras da língua em questão, no caso do português do Brasil, por exemplo: ‘tdhdo’) foram retiradas do trabalho de Justi e Pinheiro (2006) e empregadas para facilitar a discriminação entre ambos os grupos de estímulos (palavras e pseudopalavras). Pode-se considerar que essas palavras não tenham quaisquer vizinhos ortográficos no português do Brasil e que o seu índice de ativação lexical seja virtualmente igual a zero, o que facilitaria o uso da estratégia de "adivinhação rápida" (Justi & Pinheiro, 2006). Os 24 estímulos utilizados na sessão de treinamento exibiram as mesmas características dos estímulos experimentais. Desse modo, os participantes poderiam utilizar a sessão de treino para por em prática o uso da estratégia de adivinhação rápida. Os estímulos (pseudopalavras ilegais) utilizados nesse experimento encontram-se no Anexo B.
Procedimentos
O local de testagem, as características do ambiente e o instrumento de coleta de dados foram os mesmos do primeiro experimento, sendo diferentes, apenas, os parâmetros de apresentação dos estímulos e as instruções dadas aos participantes. A apresentação dos estímulos obedeceu, tanto para a sessão de treinamento, quanto para a experimental, aos seguintes procedimentos: (a) uma marca de fixação (+) aparecia no centro da tela por 500 ms; (b) após um intervalo de 200 ms, o estímulo alvo em letras minúsculas (que podia ser uma palavra ou uma pseudopalavra ilegal) era apresentado por 250 ms, quando era então substituído por uma máscara (#####) que permanecia na tela por 2250 ms, ou, até que o participante pressionasse uma das duas teclas do experimento. Os participantes deveriam pressionar uma tecla azul quando o estímulo fosse uma palavra e uma tecla amarela, quando o estímulo fosse uma pseudopalavra ilegal. Os estímulos foram apresentados de forma aleatória para cada participante e o intervalo entre o término da apresentação de um estímulo e o início da apresentação de outro (iniciando-se com a marca de fixação) foi de 800 ms. Além disso, os estímulos seguiam a fonte padrão do MS - DOS (tamanho 14), sendo de cor branca em um fundo preto. Os dois botões do experimento (azul para palavras e amarelo para pseudopalavras ilegais) ficavam dispostos de modo que os participantes pudessem usar seus dedos indicadores para dar as respostas e seus polegares para iniciarem às sessões. O teclado de um computador foi configurado especialmente para canhotos, para que todos os participantes pudessem usar a mão dominante para responder às palavras. O procedimento de testagem foi muito semelhante ao adotado no primeiro experimento, diferindo apenas no tempo de duração e nas instruções dadas. Esse experimento durou, aproximadamente, 12 minutos para ambas as sessões, e, as crianças receberam as seguintes instruções:
Nesse teste você verá esse sinal + no centro da tela. Logo após, você verá uma palavra ou uma palavra de mentira que irá desaparecer rapidamente, sendo substituída por esse sinal: #####. Aperte o botão azul quando for uma palavra ou o botão amarelo quando for uma palavra de mentira. Tente fazer isso o mais rápido possível, mas evite errar muito.
Da mesma forma que no experimento anterior, a sessão de treinamento contava com feedback e ao seu término, as crianças tinham a oportunidade de redimir eventuais dúvidas antes de passarem à sessão experimental (que não contava com feedback).
Resultados
Devido a um índice de erros superior a 30 por cento na tarefa experimental, optou-se por excluir dois participantes das análises de dados nessa tarefa. Sendo assim, as análises de dados contaram com 28 participantes. Nessa análise, todos os escores de um participante que se desviaram de sua média, por mais de dois desvios-padrão em qualquer direção, foram limitados a esse valor (Perea, 1999). Esse procedimento alterou 4,65% dos escores desse experimento. A Tabela 3 apresenta a média e o desvio-padrão do Tempo de Reação (TR) dos participantes para cada condição experimental.
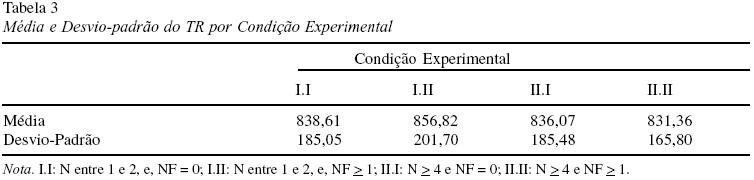
Tomando como parâmetro de comparação a condição I.I, pode-se perceber que a presença de pelo menos um vizinho de maior freqüência (cond. I.II) faz com que o TR dos participantes aumente, porém quando existem vizinhos de maior freqüência em conjunto com muitos vizinhos (cond. II.II) o TR tende a diminuir. No entanto, nenhum dos efeitos de N ou NF foram significativos estatisticamente e nem sua interação (todos os min F’ < 1).
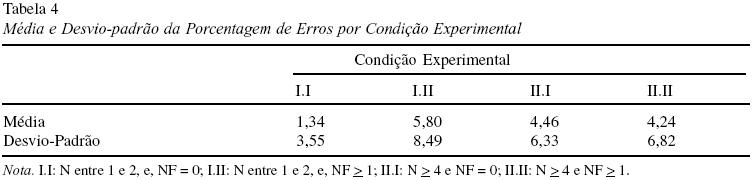
O índice de erros nesse experimento foi de 3,96%. Ao contrário da tendência observada no TR, na análise de erros observou-se uma tendência inibitória tanto de N quanto de NF. Essa tendência pode ser observada na Tabela 4. No entanto, exceto por um efeito inibitório de NF [min F’ (1,57) = 4,17] que se restringiu às condições em que era pequeno o número de vizinhos (cond. I.I x I.II), nenhum outro efeito foi estatisticamente significativo (todos os min F’ < 3,61).
Discussão
Nesse experimento, trabalhou-se com a hipótese auxiliar de que, por nunca terem tido contato com a tarefa de decisão lexical, as crianças do presente estudo seriam menos propensas a utilizar a estratégia de "adivinhação rápida" do que os adultos do estudo de Justi e Pinheiro (2006)4. Nesse sentido, postulou-se que as crianças apresentariam um padrão de respostas diferente do apresentado pelos adultos no estudo de Justi e Pinheiro (2006). Isso de fato aconteceu, pois no experimento de Justi e Pinheiro (2006), observou-se um efeito facilitador de N na porcentagem de erros, enquanto no presente experimento observou-se uma tendência inibitória de N e um efeito inibitório de NF na porcentagem de erros. No entanto, assinala-se que, na análise do tempo de reação, ambos os estudos apresentaram efeitos nulos tanto de N, quanto de NF. Talvez, a ênfase na rapidez e a pressão do tempo (pelo desaparecimento do estímulo), possam ter feito com que os participantes estabelecessem um limite de tempo muito baixo para a resposta "não", fazendo com que o TR tivesse uma amplitude de variação pequena. Daí o efeito nulo de N e NF na análise do TR.
Esse efeito inibitório de NF encontrado no desempenho das crianças, mesmo em uma tarefa que propicia o uso de estratégias, corrobora a proposta de Justi e Pinheiro (2006) de que o efeito de vizinhança ortográfica é genuinamente inibitório no português do Brasil. Além disso, como crianças e adultos apresentaram o mesmo padrão de desempenho na tarefa de decisão lexical do tipo Go/No-Go em que o índice de ativação lexical das palavras e pseudopalavras foi equiparado, é provável que a tarefa do tipo Go/No-Go seja, de fato, mais representativa de acesso lexical genuíno do que a tarefa de decisão lexical com tempo fixo.
Conclusão
Os resultados do estudo de Justi e Pinheiro (2006) e os desse estudo tomados em conjunto levam à conclusão de que o efeito de vizinhança ortográfica, no que diz respeito ao acesso lexical, é genuinamente inibitório no português do Brasil. Nota-se que a mesma proposta tem sido feita para outras línguas como a espanhola (Carreiras et al., 1997), a francesa (Grainger et al., 1992) e a inglesa (Perea & Pollatsek, 1998), embora, no caso da língua inglesa, ainda existam controvérsias (Andrews, 1997; Huntsman & Lima, 2002).
Os resultados apresentados têm implicações para os atuais modelos de reconhecimento de palavras. No que diz respeito ao modelo Múltiplo de Leitura - ML (Grainger & Jacobs, 1996) e ao modelo de Dupla Rota em Cascata - DRC (Coltheart et al., 2001), pode-se perceber que os dados do presente estudo são compatíveis com esses modelos, pois ambos prevêem um efeito inibitório de N e de NF no acesso ao léxico ortográfico. Os modelos de Busca e Verificação (Murray & Forster, 2004; Paap & Johanasen, 1994) teriam um pouco de dificuldade em explicar o efeito inibitório de N na tarefa de Decisão Lexical do tipo Go/No-Go, pois se a busca no modelo é serial e ordenada por freqüência, a única variável que poderia ter algum efeito inibitório nessa tarefa seria NF.
Por fim, os modelos de Processamento Paralelo Distribuído PPD (Plaut et al., 1996; Seidenberg & McClelland, 1989) tendem a prever um efeito facilitador, tanto de N quanto de NF nas tarefas de decisão lexical e por isso, teriam dificuldades em explicar os presentes achados. O efeito facilitador ocorreria porque para distinguir uma palavra de uma pseudopalavra na tarefa de decisão lexical, os modelos PPD basear-se-iam no feedback proveniente das unidades escondidas e o comparariam com o padrão de ativação das unidades ortográficas. Assim, os modelos classificariam como pseudopalavras, estímulos que gerassem maior discrepância entre esses dois padrões de ativação e classificariam como palavras, estímulos que gerassem pouca ou nenhuma discrepância. Durante o treinamento dos modelos, as unidades responsáveis por gerar o padrão de ativação de uma palavra-alvo (unidades escondidas) se beneficiariam também do treino com palavras similares a essa palavra-alvo. Desse modo, para palavras com muitos vizinhos, o feedback proveniente das unidades escondidas seria mais preciso e próximo do padrão do input nas unidades ortográficas (como pode ser observado na simulação computacional de Sears et al., 1999). Sendo assim, no atual estado de desenvolvimento dos modelos de reconhecimento de palavras, os modelos DRC e ML (Coltheart et al., 2001; Grainger & Jacobs, 1996) parecem ser mais adequados a descrever o efeito de vizinhança ortográfica no português do Brasil. No entanto, nada impede que os outros modelos, se modificados, possam também se tornar compatíveis com os achados dessa pesquisa.
A guisa de conclusão, algumas sugestões podem ser feitas a pesquisas futuras. A natureza da estratégia de adivinhação rápida parece ainda ser uma questão que levanta muitas perguntas: o que é necessário para que os sujeitos utilizem essa estratégia? Como ela se desenvolve? Ela demanda alguma habilidade em especial ou apenas a prática? Cabe aos modelos de reconhecimento visual de palavras o desafio de explicitar não só as condições em que a estratégia de adivinhação rápida vem a ser utilizada, mas também, quais "pré-requisitos" ou nível de expertise, os sujeitos devem ter para utilizá-la. No presente estudo, supôs-se que as crianças não utilizariam essa estratégia por não terem familiaridade com a tarefa de decisão lexical, no entanto, nenhum dos modelos atuais faz predições explícitas do porquê isso deva acontecer. Por fim, no caso do português do Brasil, é ainda necessário investigar qual o papel das variáveis N e NF em tarefas que têm demandas diferentes da tarefa de decisão lexical, como a tarefa de leitura em voz alta, por exemplo. Isso ajudaria a estabelecer se essas variáveis têm um efeito limitado apenas à identificação lexical ou se elas afetariam outros processos também.
Referências
Andrews, S. (1989). Frequency and neighborhood effects on lexical access: Activation or search? Journal of Experimental Psychology: Learning, Memory & Cognition, 15, 802-814. [ Links ]
Andrews, S. (1992). Frequency and neighborhood effects on lexical access: Lexical similarity or orthographic redundancy? Journal of Experimental Psychology: Learning, Memory, & Cognition, 18, 234-254. [ Links ]
Andrews, S. (1997). The effect of orthographic similarity on lexical retrieval: Resolving neighborhood conflicts. Psychonomic Bulletin & Review, 4, 439-461. [ Links ]
Balota, D., & Chumbley, J. (1984). Are lexical decisions a good measure of lexical access? The role of word frequency in the neglected decision stage. Journal of Experimental Psychology: Human Perception & Performance, 10, 340-357. [ Links ]
Carreiras, M., Perea, M., & Grainger, J. (1997). Effects of orthographic neighborhood in visual word recognition: Cross-task comparisons. Journal of Experimental Psychology: Learning, Memory, & Cognition, 23, 857-871. [ Links ]
Clark, H. (1973). The language-as-fixed-effect fallacy: A critique of language statistics in psychological research. Journal of Verbal Learning and Verbal Behavior, 12, 335-359. [ Links ]
Coltheart, M., Davelaar, E., Jonasson, J., & Besner, D. (1977). Access to the internal lexicon. In S. Dornic (Ed.), Attention and performance: Vol. 6 (pp. 535-555). Hillsdale, NJ: Erlbaum. [ Links ]
Coltheart, M., Rastle, K., Perry, C., Langdon, R., & Ziegler, J. (2001). DRC: A dual route cascaded model of visual word recognition and reading aloud. Psychological Review, 108, 204-256. [ Links ]
Grainger, J. (1990). Word frequency and neighborhood frequency effects in lexical decision and naming. Journal of Memory and Language, 29, 228-244. [ Links ]
Grainger, J., & Jacobs, A. (1996). Orthographic processing in visual word recognition: A multiple read-out model. Psychological Review, 103, 518-565. [ Links ]
Grainger, J., O’Reagan, K., Jacobs, A., & Seguí, J. (1989). On the role of competing word units in visual word recognition: The neighborhood frequency effect. Perception & Psychophysics, 45, 189-195.
Grainger, J., O’Reagan, K., Jacobs, A., & Seguí, J. (1992). Neighborhood frequency effects and letter visibility in visual word recognition. Perception & Psychophysics, 51, 49-56.
Grainger, J., & Seguí, J. (1990). Neighborhood frequency effects in visual word recognition: A comparison of lexical decision and masked identification latencies. Perception & Psychophysics, 47, 191-198. [ Links ]
Huntsman, L., & Lima, S. (1996). Orthographic neighborhood structure and lexical access. Journal of Psycholinguistic Research, 25, 417-429. [ Links ]
Huntsman, L., & Lima, S. (2002). Orthographic neighbors and visual word recognition. Journal of Psycholinguistic Research, 31, 289-306. [ Links ]
Justi, F. R. R., & Pinheiro, A. M. V. (2006). O efeito de vizinhança ortográfica no português do Brasil: Acesso lexical ou processamento estratégico. Interamerican Journal of Psychology, 40, 275-288. [ Links ]
Laxon, V., Masterson, J., Pool, M., & Keating, C. (1992). Nonword naming: Further exploration of the pseudohomophone effect in terms of orthographic neighborhood size, graphemic changes, spelling - sound consistency, and reader accuracy. Journal of Experimental Psychology: Learning, Memory, & Cognition, 18, 730-748. [ Links ]
McClelland, J., & Rumelhart, D. (1981). An interactive activation model of context effects in letter perception: Pt. 1, an account of basic findings. Psychological Review, 88, 375-407. [ Links ]
Monsell, S., Doyle, M. & Haggard, P. (1989). Effects of frequency on word recognition tasks: Where are they? Journal of Experimental Psychology: General, 118(1), 43-71. [ Links ]
Murray, W. S., & Forster, K. I. (2004). Serial mechanisms in lexical access: The rank hypothesis. Psychological Review, 111, 721-756. [ Links ]
Paap, K. R., & Johansen, L. S. (1994). The case of the vanishing frequency effect: A retest of the verification model. Journal of Experimental Psychology: Human Perception & Performance, 20, 1129-1157. [ Links ]
Perea, M. (1999). Tiempos de reacción y psicología cognitiva: dos procedimientos para evitar el sesgo debido al tamaño muestral. Psicológica, 20, 13-21. [ Links ]
Perea, M., Carreiras, M., & Grainger, J. (2004). Blocking by word frequency and neighborhood density in visual word recognition: A task-specific response criteria account. Memory & Cognition, 32, 1090-1102. [ Links ]
Perea, M., & Pollatsek, A. (1998). The effects of neighborhood frequency in reading and lexical decision. Journal of Experimental Psychology: Human Perception & Performance, 24,767-779. [ Links ]
Perea, M., & Rosa, E. (2000). The effects of orthographic neighborhood in reading and laboratory word identification tasks: A review. Psicológica, 21, 327-340. [ Links ]
Perea, M., Rosa, E., & Gómez, C. (2003). Influence of neighborhood size and exposure duration on visual-word recognition: Evidence with the yes/no and the go/no-go lexical decision tasks. Perception & Psychophysics, 65, 273-286. [ Links ]
Perfetti, C. A. (1985) Reading ability. New York: Oxford University Press. [ Links ]
Pinheiro, A. M. V. (1996). Contagem de freqüência de ocorrência e análise psicolingüística de palavras expostas a crianças na faixa pré-escolar e séries iniciais do 1° grau. São Paulo, SP: Associação Brasileira de Dislexia. [ Links ]
Plaut, D., McClelland, J., Seidenberg, M., & Patterson, K. (1996). Understanding normal and impaired word reading: Computational principles in quasi-regular domains. Psychological Review, 103, 56-115. [ Links ]
Pugh, K. R., Rexer, K., Peter, M., & Katz, L. (1994). Neighborhood effects in visual word recognition: Effects of letter delay and nonword context difficulty. Journal of Experimental Psychology: Learning, Memory & Cognition, 20, 639-648. [ Links ]
Schneider, W. (1988). Micro experimental laboratory: An integrated system for IBM PC compatibles. Behavior Research Methods, Instruments and Computers, 20, 206-217. [ Links ]
Sears, C., Hino, Y., & Lupker, S. (1995). Neighborhood size and neighborhood frequency effects in word recognition. Journal of Experimental Psychology: Human Perception & Performance, 16, 65-76. [ Links ]
Sears, C., Hino, Y., & Lupker, S. (1999). Orthographic neighborhood effects in parallel distributed processing models. Canadian Journal of Experimental Psychology, 53, 220-229. [ Links ]
Seidenberg, M., & McClelland, J. (1989). A distributed developmental model of word recognition and naming. Psychological Review, 96, 523-568. [ Links ]
Snodgrass, J., & Minzer, M. (1993) Neighborhood effects in visual word recognition: Facilitatory or inhibitory? Memory & Cognition, 21, 247-266. [ Links ]
Received 28/03/2007
Accepted 31/01/2008
1 Universidade Federal de Alagoas - Campus A. C. Simões, ICHCA, Curso de Psicologia, Av. Lourival Melo Mota, s/n, Bairro Tabuleiro do Martins, Maceió, AL, Brasil, CEP: 57072-970. E-mail: francisjusti@gmail.com
2 O autor Francis Ricardo dos Reis Justi desenvolveu esse trabalho como bolsista do CNPq
3 Discutiremos aqui apenas os estudos que investigaram o efeito de vizinhança ortográfica fazendo uso da tarefa de decisão lexical. Para uma revisão mais abrangente da literatura ver Andrews (1997) e Perea e Rosa (2000).
4 Além disso, pode ser que uma menor inclinação ao uso da estratégia de "adivinhação rápida" por parte das crianças, também esteja relacionada a fatores cognitivos como, por exemplo, um menor grau de desenvolvimento e automatização nos processos de reconhecimento de palavras em comparação a adultos.

