








Services on Demand
article
 Portuguese (pdf)
Portuguese (pdf)
 Article in xml format
Article in xml format Article references
Article references
Indicators

Share

 Permalink
PermalinkPerspectivas em análise do comportamento
On-line version ISSN 2177-3548
Perspectivas vol.7 no.2 São Paulo July/Aug. 2016
http://dx.doi.org/10.18761/pac.2016.012
ARTIGOS
DOI: 10.18761/pac.2016.012
Comparando o efeito dos procedimentos de pareamento ao modelo simultâneo e atrasado com resposta construída no ensino de leitura e produção de sentenças
Comparing the effect of simultaneous and delayed constructed-response training on sentence reading and production
Comparando el efecto de los procedimientos de igualación a la muestra simultáneo y con atraso con respuesta construida en la enseñanza de la lectura y producción de frases
Taynan Marques Bandeira; Grauben José Alves de Assis; Carlos Barbosa Alves de Souza
Universidade Federal do Pará
RESUMO
O procedimento de pareamento ao modelo com resposta construída tem sido usado no ensino de leitura de palavras. A resposta é construída com a seleção dos componentes individuais, apresentados como estímulos-comparação, condicionalmente ao estímulo-modelo. Pode ser construída simultaneamente à presença do modelo ou com atraso, após sua apresentação e remoção. O presente estudo verificou o efeito dos treinos da resposta construída na presença e ausência do modelo, nos repertórios de produção e leitura de sentenças. Participaram sete crianças com repertório mínimo de discriminação sílabas/palavras, que não leram ou construíram as 32 sentenças do estudo. Antes do ensino das sentenças, cada participante foi exposto ao ensino das palavras que tiveram erros de leitura do Pré-teste inicial. Com um delineamento de sujeito único com tratamento alternado, todos foram submetidos aos dois treinos, com dois conjuntos diferentes de sentenças. Os dados mostraram que todos os participantes aprenderam a construir sentenças, mantiveram esse desempenho nos dois treinos, e demonstraram o responder textual e leitura com compreensão das sentenças. A diferença de acertos entre os procedimentos não ultrapassou 20%. Discutiram-se variáveis importantes na utilização desses treinos e direções para estudos futuros.
Palavras-chave: CRMTS com e sem atraso, produção e leitura de sentenças, controle de estímulos.
ABSTRACT
Constructed-response matching to sample has been used to teach word reading. In this procedure, the response is constructed through the selection of the word's individual components, presented as comparison stimuli conditionally on a given sample. The response may be constructed simultaneously with, or after, the sample stimulus. This study evaluated the effect of simultaneous and delayed constructed-response training on sentence reading and production. The participants were seven children with a minimal repertoire of syllable and word discrimination and who could not read or construct the 32 sentences used in our pretest. Before being taught sentences, the participants were trained to read the words that they had read incorrectly during pretesting. Using a single-subject, alternated-treatment design, all participants went through the two types of training with two different sets of sentences. The results showed that all participants learned to construct sentences and maintained their level of performance throughout training. Also, the participants showed textual behavior and the reading of sentences with comprehension. The difference between the two procedures did not exceed 20% in terms of correct responses. We discuss some variables that may have been important in the implementation of the training schedules as well as possibilities for future studies.
Keywords: simultaneous vs. delayed constructed-response matching to sample, sentence reading and production, stimulus control.
RESUMEN
El procedimiento de igualación a la muestra con respuesta construida se ha utilizado en la enseñanza de la lectura de palabras. La respuesta es construida con la selección de los componentes individuales de las palabras, presentados como estímulos de comparación condicionalmente al estímulo muestra. La respuesta puede ser construida simultáneamente a la presencia del estímulo muestra, o con atraso. El presente estudio investigó el efecto del entrenamiento de la respuesta construida en la presencia y ausencia del estímulo muestra, sobre la producción y lectura de frases. Participaron siete niños con un repertorio mínimo de discriminación de silabas y palabras, que no leyeron o construyeron en el pre-test las 32 frases del estudio. Antes de la enseñanza de las frases, los participantes fueron enseñados a leer las palabras leídas incorrectamente en el pre-test. Empleando un diseño de sujeto único con tratamiento alternado, todos participantes fueron sometidos a los dos tipos de entrenamiento, con dos conjuntos diferentes de frases. Los resultados mostraron que todos los participantes aprendieron a construir frases y mantuvieron el desempeño en todos los entrenamientos, y demostraron responder textual y lectura con comprensión de las frases. La diferencia en los aciertos entre los procedimientos no excedió el 20%. Se discuten las variables que pueden haber sido importantes en la implementación de los entrenamientos y posibilidades para estudios futuros.
Palabras clave: igualación a la muestra simultáneo y con atraso con respuesta construida, producción y lectura de frases, control de estímulos.
A aprendizagem dos repertórios de leitura e escrita é fundamental para a plena inserção dos indivíduos no mundo moderno. A Ciência da Análise do Comportamento vem contribuindo com estudos para o ensino dos repertórios considerados pré-requisitos de leitura e escrita (e.g., de Souza, de Rose & Domeniconi, 2009; de Souza, Hanna, de Rose, Melo, & Quinteiro, 2004).
Um dos procedimentos que tem se mostrado eficaz para ensinar a leitura e a escrita de palavras para populações que apresentam dificuldades em aprender esses repertórios é o de 'pareamento ao modelo com resposta construída' (do inglês constructed response matching to sample ou CRMTS - e.g., Dube, McDonald, McIlvane, & Mackay, 1991). Este procedimento caracteriza-se pela apresentação de um estímulo-modelo e os estímulos-comparação são as partes componentes deste modelo. A tarefa consiste em construir uma resposta por meio da seleção de tais componentes, colocando-os na ordem correta, condicionalmente ao modelo apresentado. Quando os estímulos-comparação apresentam características físicas comuns com o modelo, define-se o CRMTS de identidade (do inglês identity constructed response matching to sample). Quando a relação estabelecida entre os estímulos-comparação e o modelo é fisicamente diferente, define-se o CRMTS de arbitrário (do inglês arbitrary constructed response matching to sample). Situações clássicas do cotidiano que podem exemplificar estes dois procedimentos são: a cópia e o ditado, respectivamente. Na cópia, o estímulo-modelo é visual (ex. palavra impressa), os estímulos-comparação também são visuais (ex. letras que a compõem) e a resposta é escrita (seja por composição/construção ou manuscrita). No ditado, o estímulo-modelo é auditivo (ex. palavra ditada), os estímulos-comparação são visuais (ex. letras que a compõem) e a resposta é escrita (seja por composição/construção ou produção manuscrita).
O procedimento ainda pode variar em função da permanência ou remoção do estímulo-modelo quando os estímulos-comparação são apresentados (Stromer & Mackay, 1992). No CRMTS simultâneo (do inglês simultaneous constructed response matching to sample ou SCRMTS), o modelo permanece presente até que todos os estímulos-comparação sejam selecionados. No CRMTS com atraso (do inglês delayed constructed response matching to sample ou DCRMTS), somente após a remoção do modelo é que os estímulos-comparação são apresentados e a tarefa pode ser realizada.
Pelo fato da resposta no CRMTS ser construída selecionando cada elemento, este procedimento tem se mostrado útil para estabelecer o controle discriminativo pelas unidades mínimas que compõem o estímulo-modelo, o que pode favorecer o desempenho de soletração (spelling) (e.g., Stromer & Mackay, 1992).
Dube et al. (1991) utilizaram uma versão computadorizada do SCRMTS para o ensino de soletração de dois jovens adultos com atraso no desenvolvimento cognitivo. Os participantes foram ensinados a construir palavras diante de estímulos-modelo simultâneos (palavra impressas e figuras) tendo as letras como estímulos-comparação. Inicialmente, utilizando o CRMTS de identidade, as palavras apresentadas como modelo tinham as letras na cor preta, mas com o decorrer das tentativas ficavam em tons de cinza gradualmente mais claros até serem excluídas totalmente. Após este treino, era ensinada a tarefa de resposta construída a partir de figuras como estímulo-modelo. O desempenho final dos participantes demonstrou que o SCRMTS foi eficaz para o ensino da soletração, com diminuição de erros ao longo do procedimento de ensino e o procedimento fading out favoreceu a transferência de controle de estímulos textuais para os estímulos figuras.
Stromer e Mackay (1992) identificaram que três participantes, com atraso no desenvolvimento cognitivo, após um treino de pareamento ao modelo, no qual a exigência era apenas selecionar palavras como estímulos-comparação, não foram capazes posteriormente de construir as mesmas palavras. Portanto, investigaram o efeito do DCRMTS informatizado na soletração de palavras envolvendo novas manipulações: palavra ditada como estímulo-modelo e a inclusão do atraso zero, ou seja, o estímulo-modelo era apresentado e removido, e após 0s, os estímulos-comparação eram apresentados. Em cada sessão de treino eram realizadas as tarefas de pareamento ao modelo (figura-figura, palavra impressa-palavra impressa; palavra ditada-figura; palavra impressa-figura; palavra ditada-palavra impressa) e tarefas de resposta construída com atraso zero (palavra impressa, palavra ditada e figura como modelos). Os resultados demonstraram que os participantes apresentaram um aumento nas respostas corretas de soletração, inclusive diante de novas palavras, sob controle da figura ou palavra ditada. Um participante ainda demonstrou melhora nos desempenhos de soletração oral, escrita e nomeação das palavras.
Em um estudo similar, Hanna, de Souza, de Rose e Fonseca (2004) avaliaram os efeitos do treino com DCRMTS de cópia (usando anagramas) sobre a generalização recombinativa e escrita manual sob controle de palavras ditadas, com crianças que já haviam participado de um programa de ensino de leitura. Os resultados demonstraram que, embora com algumas variações entre as crianças, o DCRMTS foi eficaz na construção das palavras pela seleção das letras, bem como na resposta manuscrita, incluindo tanto as palavras treinadas quanto novas palavras recombinadas.
Os resultados dos estudos descritos anteriormente mostram que os procedimentos DCRMTS e SCRMTS têm sido efetivos para ensinar soletração de palavras para crianças ou adultos com dificuldades de aprendizagem. Entretanto, para ensinar o repertório sintático é necessário que além das palavras, a criança saiba organizá-las de uma maneira que seja compreendida por outras pessoas, seja falando ou escrevendo. Para Skinner (1992), são as contingências sociais que selecionam arbitrariamente a ordem em que as palavras são expressas nas sentenças e uma expressão sintaticamente correta significa que a ordem das palavras é apropriada a uma determinada comunidade verbal e não a outra. Assim, alguns estudos na literatura investigaram as variáveis relevantes no estabelecimento do repertório sintático utilizando, dentre outros procedimentos, o CRMTS.
Yamamoto e Miya (1999) utilizaram um procedimento informatizado com SCRMTS para ensinar três crianças com Transtorno do Espectro Autista (TEA) a construírem sentenças com cinco palavras (sendo duas partículas específicas da língua japonesa) diante de imagens como estímulos-modelo. Apresentavam como repertório inicial a formação de sentenças com apenas duas palavras (sem as partículas) e escreviam palavras, mas não sentenças. Inicialmente, após serem ensinadas a construírem três sentenças diante de uma imagem correspondente, foram capazes de construir novas sentenças gramaticalmente corretas diante de novas imagens. Em seguida, foi investigado, se os participantes eram capazes de usar corretamente as partículas (a depender da posição que ocupam, determinam se sentença está na voz passiva ou ativa), bem como avaliaram a transferência da resposta de construção da sentença para a resposta manuscrita. Os resultados demonstraram que os participantes aprenderam a construir sentenças completas, fazendo o uso adequado das partículas, bem como realizaram a escrita manuscrita das mesmas.
Considerando a importância e complexidade no ensino do repertório sintático (Mackay & Fields, 2009), e por não ter sido verificado nenhum estudo na literatura que comparasse a efetividade dos procedimentos SCRMTS e DCRMTS, o presente estudo delineou um arranjo experimental que verificou o efeito dos treinos simultâneo e com atraso informatizado, no estabelecimento dos repertórios de produção e leitura de sentenças, bem como manutenção desse repertório em crianças com desenvolvimento típico.
Método
Participantes
Participaram sete crianças com desenvolvimento típico, com seis anos de idade, sendo seis do sexo masculino (ZIA, UAN, LAE, PAL, ADR, MOR) e uma do sexo feminino (JAM). Todas frequentavam o 1º ano do Ensino Fundamental numa instituição privada. Os critérios de inclusão e exclusão estão descritos na seção Procedimentos, nos Pré-testes. A participação foi autorizada pelos pais por meio da assinatura do Termo de Consentimento Livre e Esclarecido. A pesquisa foi aprovada pelo Comitê de Ética em Pesquisa da Universidade Federal do Pará, com o parecer nº 405.206 de 24/09/2013.
Ambiente experimental, material e equipamentos
As sessões foram conduzidas em uma sala de 2,0 m2;, climatizada e iluminada artificialmente. Foi utilizado o notebook DELL Inspiron com tela sensível ao toque, para apresentação dos softwares Microsoft Office Power Point® e PROLER na versão 7.0 (Assis & Santos, 2010). Os estímulos auditivos foram gravados e editados previamente pela experimentadora no software Audacity Portable®.
As sessões experimentais foram filmadas com uma filmadora Sony DSC-W210 e os desempenhos foram anotados em folhas de registro. As sessões de Pré-teste 1 e Testes de Sentenças (etapas 1, 2) e de Manutenção foram assistidas por um segundo observador. O índice de concordância ([Concordância/Concordâncias + Discordância] x 100) entre observadores foi de 100% na resposta de construção e de 98% a 100% no responder textual das sentenças.
Estímulos antecedentes
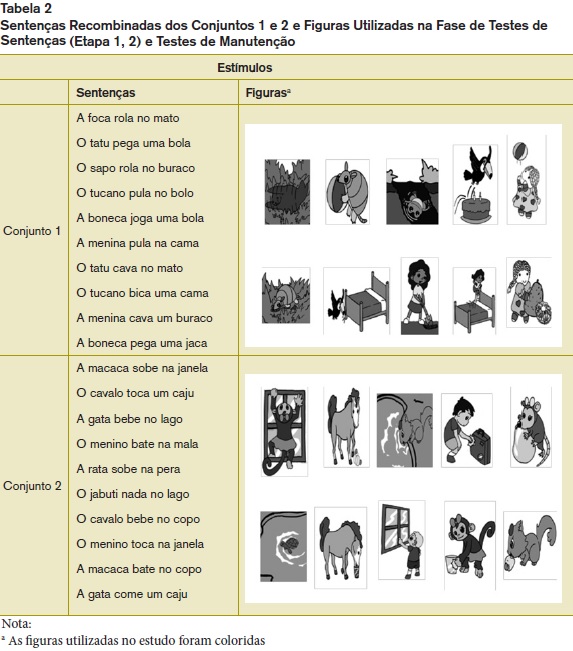
As sentenças foram divididas em dois conjuntos, cada um contendo seis sentenças afirmativas, formadas por cinco termos: artigo definido + substantivo + verbo + locução prepositiva ou artigo indefinido + substantivo. Foram apresentadas nos formatos visual e auditivo. Também foram usadas figuras correspondentes a cada uma das sentenças. A Tabela 1 apresenta as sentenças dos conjuntos 1 e 2, e suas respectivas figuras, utilizadas durante a Fase de Ensino das Sentenças. A Tabela 2 apresenta as sentenças recombinadas dos conjuntos 1 e 2, e suas respectivas figuras, utilizadas na Fase de Testes das Sentenças.

Estímulos consequenciadores
Com base nas informações obtidas com os pais e/ou professores foram selecionados alguns brindes de preferência de cada criança (material escolar, revistas de colorir, brinquedos, jogos, guloseimas). Antes de cada sessão experimental, era realizado um teste de preferência, com estímulos múltiplos sem reposição (sinalizados pelos pais/professores), para escolher os brindes que pudessem funcionar como reforçadores (Carr, Nicolson, & Higbee, 2000). O resultado estabelecia uma hierarquia de preferência dos estímulos e apenas o brinde de maior preferência era entregue ao final da sessão experimental, independente do desempenho. Isso foi planejado para reforçar o comportamento de participar da atividade, manter a motivação, mesmo que houvessem "erros" ao longo das tentativas.
Delineamento experimental
Foi utilizado um delineamento de sujeito único com tratamento alternado, de forma que todos os participantes foram expostos aos dois procedimentos de ensino: SCRMTS e DCRMTS. Cada participante foi ensinado a construir sentenças por meio de cada procedimento, com conjuntos de diferentes sentenças, de forma alternada entre sessões. Para o ensino das sentenças do conjunto 1, foi utilizado o SCRMTS com os participantes ZIA, JAM, PAL e MOR, enquanto que UAN, LAE e ADR foram ensinados pelo DCRMTS. Para o ensino das sentenças do conjunto 2, os participantes ZIA, JAM, PAL e MOR foram ensinados pelo DCRMTS, enquanto que UAN, LAE e ADR foram pelo SCRMTS. A ordem de apresentação dos treinos foi balanceada entre as sessões experimentais para controlar possíveis efeitos de sequência do tipo de treino realizado. Por exemplo, se ZIA no primeiro dia foi exposto inicialmente ao ensino das sentenças do conjunto 1 (SCRMTS) e depois ao conjunto 2 (DCRMTS), no dia seguinte, o treino iniciou com as sentenças do conjunto 2 (DCRMTS), seguido do conjunto 1 (SCRMTS) e assim sucessivamente até o ensino de todas as sentenças.
Procedimento
Pré-testes. Nesta fase as respostas não foram consequenciadas diferencialmente e todas as sentenças foram apresentadas apenas uma vez para cada avaliação.
Pré-teste 1: Comportamento textual e construção de sentenças
Inicialmente foi avaliado o repertório de responder textual das 32 sentenças individualmente (ver Tabelas 1 e 2). A experimentadora manipulava o notebook para apresentar a sentença digitada, em um slide no Power Point, com a seguinte instrução vocal: "Leia a frase em voz alta". A sentença ficava disponível na tela por, no máximo, dois minutos. Após esse tempo, mesmo que o participante ainda estivesse tentando responder textualmente, era sinalizado pela experimentadora que outra sentença seria apresentada. A resposta correta consistia na emissão de um som, fluente ou não, que correspondesse, ponto-a-ponto, a todas as palavras presentes na sentença. Mesmo que o participante respondesse textualmente a quatro das cinco palavras, era considerado erro, e passava-se para a sentença seguinte. Caso o participante respondesse "não sei", outra sentença era imediatamente apresentada. Este pré-teste foi realizado em uma sessão experimental, tendo quatro blocos com oito sentenças cada, havendo um intervalo de três minutos entre eles.
Na sessão seguinte, verificou-se o repertório de construção, apresentando individualmente as 32 sentenças no formato auditivo. O estímulo auditivo, gravado previamente pela experimentadora, era apresentado repetidamente a cada dois segundos pelo sistema de áudio do notebook. Foi utilizado o software PROLER, e a configuração da tela do notebook ficava dividida em duas áreas principais: a parte inferior, "área de escolha" e a superior, "área de construção". Acima da "área de construção" existia uma célula onde era apresentado o estímulo-modelo. Após a resposta de observação (toque no estímulo-modelo), os seis estímulos-comparação eram apresentados, sendo cinco corretos e apenas uma palavra funcionava como estímulo de distração. O toque em cada estímulo-comparação produzia o seu deslocamento da "área de escolha" para a "área de construção", onde ficava disposto da esquerda para a direita. Após a seleção da última palavra, o participante tocava na célula "confirmar", e então a tentativa era concluída. Portanto, a duração de tempo máximo em cada tentativa era estabelecida pelo próprio participante. Foram realizados dois blocos com 16 sentenças cada, sendo que um bloco foi avaliado com o SCRMTS e o outro com o DCRMTS. Primeiramente foram testadas 16 sentenças com o mesmo procedimento. Após um intervalo de três minutos, as demais 16 sentenças foram avaliadas com o outro procedimento.
No procedimento com SCRMTS, no início da tentativa, a sentença ditada já era apresentada regularmente, independente de qualquer ação do participante e permanecia presente durante toda a tarefa de construção. Após o toque no modelo (quadrado verde) eram apresentadas seis palavras como estímulos-comparação. A instrução foi: "Ouça a frase e ordene as palavras que aparecerão nesses quadrados (apontando para a região) conforme o que está ouvindo". Caso o participante respondesse "não sei", foi solicitado que continuasse selecionando as palavras da maneira que achasse correto. No procedimento com DCRMTS, as tentativas eram realizadas com uma configuração semelhante, mas a diferença era que após o toque no modelo (quadrado verde), o estímulo auditivo era interrompido e a tarefa de selecionar os estímulos-comparação era realizada na sua ausência. Durante o teste do comportamento textual da sentença, o estímulo- modelo impresso ficou presente durante toda a tentativa. Apenas no teste de construção era manipulada a presença ou ausência do estímulo-modelo. Os participantes que obtiveram, no máximo, 50% de acertos das 64 tentativas desta fase, em cada um dos repertórios (textual e construção), foram incluídos na pesquisa.
Pré-teste 2: Comportamento textual das palavras
As 42 palavras utilizadas nas sentenças dos Conjuntos 1 e 2 foram apresentadas randomicamente. Na presença da palavra, a experimentadora fornecia a instrução: "Leia a palavra em voz alta". A resposta correta consistia na emissão de um som, fluente ou não, que correspondesse ponto-a-ponto, à grafia da palavra. Quando responderam "não sei", foi solicitado que nomeassem vocalmente, pelo menos, as letras e/ou as sílabas. Em seguida, era apresentada uma nova palavra. Esta avaliação foi realizada em uma sessão experimental, sendo três blocos com 14 palavras cada e um intervalo de três minutos entre eles. Para ser incluído na pesquisa, o participante podia ou não apresentar um responder textual das palavras, mas deveria obter, no mínimo, 75% de acertos na soletração das 20 letras e 35 sílabas utilizadas nas mesmas.
Fase de Ensino de Palavras.
Nesta fase as respostas foram consequenciadas diferencialmente. Os acertos foram seguidas de elogios fornecidos pela experimentadora e diferentes imagens/gifs de desenhos infantis a cada acerto, que permaneciam na tela do notebook por três segundos. Os erros eram seguidos do escurecimento da tela por três segundos e os estímulos-comparação reapareciam na mesma posição (procedimento de correção).
O objetivo foi ensinar a construção e comportamento textual sob o controle discriminativo das 38 palavras. Foi planejada conforme o desempenho de "erros" de cada participante na fase anterior. Novamente foi usado o PROLER com uma configuração semelhante aos parâmetros descritos no Pré-teste 1.
O ensino de cada palavra correspondia a um bloco, que era composto inicialmente pelo ensino das sílabas, seguido do ensino da palavra inteira. O participante iniciava construindo cada sílaba da palavra por meio da seleção das letras, sob controle inicial da sílaba impressa e depois da ditada. Após o treino de todas as sílabas da palavra (duas ou três), o participante foi ensinado a construir a palavra, selecionando as sílabas já aprendidas, sob controle inicial da palavra impressa, seguida da ditada e por fim, da figura. O critério de acertos durante o ensino das sílabas foi de 100% em duas tentativas consecutivas; já o critério no ensino das palavras foi 100% em três tentativas consecutivas. Enquanto o critério não era alcançado, o participante era reexposto ao procedimento, seja com a sílaba ou a palavra. Somente após atingir todos os critérios de acertos no ensino de uma palavra, as demais eram ensinadas, uma por vez. No ensino dos artigos indefinidos (um, uma), por ser uma palavra monossílaba e não ter uma figura correspondente, o participante construiu a palavra apenas por meio da seleção das letras, sob controle inicial da sílaba impressa e depois da ditada. As locuções prepositivas (no, na) não foram ensinadas separadamente por serem sílabas constituintes das demais palavras.
Com as palavras dissílabas foram conduzidas, no mínimo, um bloco de 17 tentativas. Com as trissílabas, foram, no mínimo, 21 tentativas. Com as palavras monossílabas, foram realizadas, no mínimo, um bloco de quatro tentativas.
O ensino do comportamento textual foi realizado simultaneamente à tarefa de construção das sílabas e da palavra. Em todas as tentativas com a apresentação do estímulo-modelo impresso, antes de selecionar os estímulos-comparação, a experimentadora solicitava: "Leia esta (sílaba ou palavra) em voz alta" e aguardava por três segundos. Quando o participante respondeu textualmente de modo vocal com correspondência ponto-a-ponto com o modelo impresso, passou-se diretamente para a tentativa seguinte. Quando não respondeu ou o fez incorretamente, a experimentadora nomeou o modelo e pediu que repetisse o som apresentado. Só então, podia selecionar os estímulos-comparação.
Primeiro eram ensinados os artigos indefinidos e as palavras do Conjunto 1, seguidos dos testes de leitura textual e com compreensão (descritos na seção Fase de Testes das Palavras). Antes de continuar com o ensino do Conjunto 2, a experimentadora reapresentava as palavras deste conjunto, com a mesma configuração do Pré-teste 2: Comportamento textual das palavras. Apenas diante das palavras em que os participantes não apresentaram respostas textuais correspondentes, foram incluídas no ensino do Conjunto 2, na Fase de Ensino de Palavras. A quantidade de palavras ensinadas por sessão experimental era, no máximo, 10 palavras.
Fase de Testes das Palavras
Comportamento textual e leitura com compreensão. Nesta fase foram avaliados o comportamento textual e a leitura com compreensão entre figura-palavra impressa (e vice-versa) das 36 palavras (substantivos e verbos) utilizadas na pesquisa, por meio do procedimento de "pareamento ao modelo". Ambos os testes foram realizados, no máximo, em duas sessões experimentais e as respostas não foram consequenciadas diferencialmente.
Inicialmente foram realizados os testes de leitura com compreensão palavra impressa-figura. A tentativa iniciou pela apresentação da palavra impressa como modelo e solicitação de que o participante respondesse textualmente em voz alta. Apresentando ou não a correspondência ponto-a-ponto com o estímulo, foram apresentadas três figuras (do próprio estudo) como estímulos-comparação e indicado que selecionasse a figura correspondente. Esse passo-a-passo foi realizado com todas as demais palavras. Em seguida, foram realizados todos os testes figura-palavra impressa, no qual uma figura foi o modelo e três palavras impressas foram os estímulos-comparação para que apenas uma fosse selecionada. Neste momento, não foi exigido que emitissem uma resposta textual vocal das três palavras.
O participante só avançou para a fase seguinte depois que apresentou 100% de acertos no comportamento textual e de leitura com compreensão de todas as palavras. Primeiro foram avaliadas todas as palavras do Conjunto 1, em dois blocos, com nove palavras cada. Como foram dois testes, totalizaram 36 tentativas. Caso o participante tivesse 100% de acertos, foram ensinadas e testadas as palavras do Conjunto 2. Quando isso não ocorreu, cada participante foi reexposto ao ensino da(s) palavra(s) nas quais ainda ocorria(m) algum(ns) erro(s), seguido de novas tentativas de testes apenas com as palavras revisadas, antes de ser exposto ao Conjunto 2, que seguiu o mesmo passo-a-passo.
Fase de Ensino e Sonda de Sentenças com SCRMTS e DCRMTS.
Conforme descrito no Delineamento Experimental, cada conjunto de sentenças foi ensinado com um tipo de procedimento (ver Tabela 1). Cada tentativa iniciava com a apresentação do estímulo-modelo composto por uma sentença impressa e ditada, produzida pelo áudio do notebook e repetida a cada dois segundos. Após a resposta de observação (sentença impressa), foram apresentadas seis palavras como estímulos-comparação, sendo cinco corretas e uma que funcionava como estímulo de distração, que tinham suas posições randomizadas a cada tentativa.
Enquanto o participante executou a tarefa de construção da sentença, conforme o modelo, a experimentadora forneceu dicas com perguntas: Quem? (quando a seleção envolvia o sujeito), Faz o que? (quando envolvia a ação) e O que?/ Onde? (quando a seleção era o objeto). Após a seleção da última palavra, o participante clicava no botão "confirmar". As respostas corretas eram consequenciadas diferencialmente, assim como na Fase de Ensino das Palavras.
Durante as tentativas de ensino com o procedimento SCRMTS, o estímulo-modelo composto permaneceu presente até que o participante selecionou todas as palavras e confirmou. Com o procedimento por DCRMTS, após a resposta de observação, o estímulo-modelo foi removido com atraso zero e a tarefa realizada na sua ausência.
Foram realizadas duas sessões experimentais por dia, com um intervalo de cinco minutos entre elas. Em cada sessão, eram ensinadas duas sentenças com cada procedimento. O critério para a finalização no ensino de uma sentença foi 100% de acertos consecutivos em um bloco com três tentativas. Caso o participante não alcançasse o critério com, no máximo, quatro blocos (12 tentativas), a tarefa era encerrada e inserido um procedimento de correção com dicas, dividido em três etapas. Na primeira, o ensino incluía apenas três palavras da sentença ("A foca joga"). Após alcançar o critério de três acertos consecutivos na construção da sentença com três palavras, a segunda etapa incluía mais uma palavra ("A foca joga uma") e a terceira incluía a última palavra ("A foca joga uma bola"). A palavra que funcionava como estímulo de distração foi removida durante as duas primeiras etapas, sendo reinserida apenas na terceira etapa.
Quando o participante atingiu o critério de acerto em cada sentença, foi exposto a uma tentativa de sonda, que possuía uma configuração semelhante com a de ensino, mas as respostas não foram consequenciadas diferencialmente. O objetivo era preparar os participantes para a Fase de Testes das Sentenças, no qual suas respostas não foram reforçadas.
Revisão de linha de base
A cada duas sentenças ensinadas por SCRMTS e DCRMTS foi realizada uma revisão de linha de base com parâmetros semelhantes aos do ensino descritos acima. As duas sentenças foram apresentadas alternadamente dentro da sessão experimental com o mesmo procedimento em que foram ensinadas. Quando o critério de acerto era alcançado, o participante foi exposto ao ensino das demais sentenças. Caso não fosse, o participante era reexposto ao ensino da sentença em que apresentou erros de construção.
Após o ensino das 12 sentenças foi realizada uma Revisão de linha de base geral com o objetivo de garantir que as sentenças fossem construídas sem qualquer erro antes da exposição à Fase de Testes de Sentenças. As seis sentenças de cada conjunto foram apresentadas, de forma aleatória, diante do mesmo procedimento em que eram ensinadas. Ao construir cada sentença por duas vezes consecutivas sem erro, o participante era exposto à fase seguinte. Caso ainda apresentasse algum erro, o participante era novamente reexposto ao ensino da sentença, com os mesmos critérios de acertos já descritos.
Fase de Testes de Sentenças
Os testes eram realizados com as sentenças de ensino e as novas sentenças (ver Tabelas 1 e 2), formadas a partir da recombinação das palavras utilizadas nas sentenças de ensino e suas figuras correspondentes. Nesta fase ainda eram realizadas duas sessões experimentais por dia, uma com cada procedimento. Cada sentença era apresentada uma única vez.
Etapa 1: construção. O objetivo foi verificar o repertório de construção das sentenças, seguindo os mesmos parâmetros dos procedimentos utilizados no Pré-teste 1.
Etapa 2: comportamento textual e leitura com compreensão. O objetivo foi avaliar os repertórios de comportamento textual e leitura com compreensão das sentenças. No teste de leitura com compreensão sentença impressa-figura, a sentença era apresentada como modelo e solicitado que o participante respondesse textualmente em voz alta. A resposta textual considerada correta era a primeira vocalização na qual o som correspondesse, ponto-a-ponto, a todos os elementos da sentença. Caso não ocorresse, a resposta textual da sentença era registrada como erro. Apresentando ou não a correspondência, após a resposta de observação ao modelo, eram apresentadas três figuras como estímulos-comparação (ver Tabelas 1 e 2) e indicado que selecionasse a figura correspondente. Esse passo-a-passo era realizado com todas as demais sentenças. Em seguida, foram realizados todos os testes figura-sentença impressa, nos quais uma figura era o modelo e três sentenças impressas funcionavam como estímulos-comparação para que apenas uma fosse selecionada. Por exemplo, diante da figura "A foca joga uma bola", as sentenças impressas como comparação eram: "A foca joga uma bola", "A foca rola no mato" e "O tatu pega uma bola". Isso foi planejado para evitar que o participante respondesse sob controle de apenas um elemento do modelo. Neste momento, não foi exigido que emitissem uma resposta textual vocal das sentenças.
Fase de Testes de Manutenção.
Após um período de 20 dias sem contato com as contingências de ensino e teste, cada participante era reexposto à Etapa 1 da Fase de Teste de Sentenças. Este teste era conduzido em apenas um dia com duas sessões experimentais.
Resultados
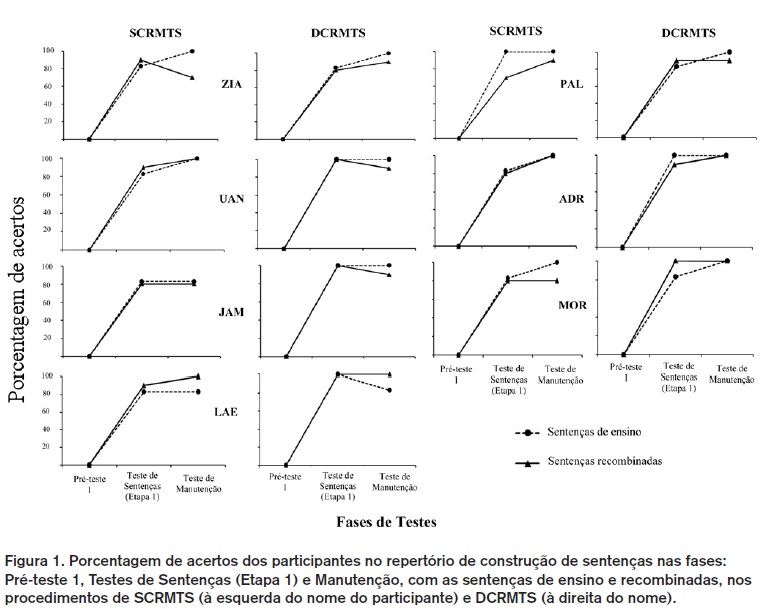
No Pré-teste 1 (construção de sentenças), nenhum dos participantes construiu corretamente as sentenças por meio dos dois procedimentos, como pode ser visualizado na Figura 1. A seleção das palavras foi feita aleatoriamente.
No Pré-teste 2 (comportamento textual das palavras) apenas UAN acertou 73% das palavras. Os participantes MOR, JAM e ADR acertaram 57%, 50% e 27% das palavras, respectivamente. Os demais (ZIA, LAE e PAL) tiveram o acerto de 10% e com dúvidas diante de algumas letras. Considerando este repertório inicial, cada participante foi exposto a um planejamento específico na Fase de Ensino das Palavras.
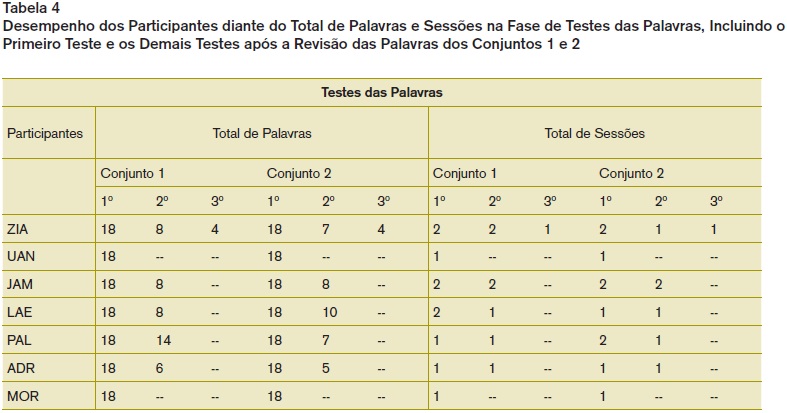
A Tabela 3 apresenta os dados da Fase de Ensino das Palavras dos conjuntos 1 e 2 para cada participante, com relação ao total de palavras ensinadas e revisadas, bem como a respectiva quantidade de sessões. Como mostra a Tabela, com relação à quantidade de palavras ensinadas, dos três participantes (ZIA, LAE e PAL) que tiveram um acerto de apenas 10% das palavras no Pré-teste 2, apenas para ZIA foram ensinadas as 38 palavras. Os participantes LAE e PAL, após serem expostos ao ensino, testes e revisões de palavras do Conjunto 1, aprenderam o responder textual de algumas palavras do Conjunto 2, sendo necessário o ensino de menos palavras do que estava previsto. O mesmo aconteceu com o ADR que precisou de uma redução no ensino de 11 para cinco palavras. Com os demais permaneceu o ensino da quantidade de palavras previsto no Pré-teste 2.

Ainda na Tabela 3, com exceção de UAN e MOR, os demais participantes precisaram ser reexpostos a uma primeira revisão de algumas palavras, de ambos os conjuntos. Destes, apenas ZIA precisou ser exposto a uma segunda revisão.
A Tabela 4 apresenta os Testes das Palavras (comportamento textual e leitura com compreensão), nos quais os participantes UAN e MOR alcançaram 100% de acertos já na primeira exposição aos testes. Os demais participantes, após a primeira exposição, tiveram erros especialmente no comportamento textual de algumas palavras e então, foram expostos a revisões das mesmas, seguido por novos testes destas palavras. Apenas ZIA precisou ser exposto mais duas vezes aos testes, com palavras dos dois conjuntos. Após essas reexposições, todos alcançaram 100% de acertos nos repertórios avaliados.
Na Fase de Ensino de Sentenças com SCRMTS e DCRMTS, os sete participantes alcançaram o critério de acerto na construção das 12 sentenças com os dois procedimentos, mas com diferentes desempenhos. Para concluir esta fase, os participantes UAN, JAM e LAE precisaram de três sessões com cada procedimento; ZIA e PAL precisaram de quatro sessões com cada; ADR concluiu com SCRMTS em quatro sessões e com DCRMTS em três; MOR concluiu com SCRMTS em três sessões e o DCRMTS com quatro. Quatro participantes (ZIA, PAL, ADR, MOR) ainda precisaram do procedimento de correção com dicas em algumas sentenças. Seis participantes (ZIA, JAM, LAE, PAL, ADR, MOR), antes de serem submetidos à Fase de Testes de Sentenças, foram expostos a uma Revisão de linha base geral com as 12 sentenças ensinadas. O participante UAN foi o único que alcançou o critério de acerto em apenas um bloco no ensino de cada sentença, por isso não foi exposto à Revisão.
Retomando a Figura 1, nos Testes de Sentenças (Etapa 1: construção), todos os participantes tiveram acima de 80% de acertos nos testes com DCRMTS, sendo que três (UAN, JAM e LAE) ainda apresentaram 100% de acertos tanto nas sentenças de ensino quanto nas recombinadas. Nos testes com SCRMTS, seis participantes (ZIA, UAN, JAM, LAE, ADR, MOR) também acertaram entre 80% e 90% das sentenças de ensino e recombinadas. Apenas PAL teve 70% de acertos das sentenças recombinadas, mas por outro lado, obteve 100% de acertos nas sentenças de ensino. Nos Testes de Manutenção com DCRMTS, com exceção de LAE, os participantes tiveram acima de 90% de acertos, e dois (ADR e MOR) ainda apresentaram 100% de acertos tanto nas sentenças de ensino quanto nas recombinadas. Nos testes de Manutenção com SCRMTS, com exceção de ZIA, os participantes tiveram acima de 80% de acertos, e novamente dois (UAN e ADR) apresentaram 100% de acertos, incluindo as sentenças de ensino e recombinadas.
Considerando uma análise geral das sentenças testadas por SCRMTS nas etapas 1 e de Manutenção, apenas ZIA teve um decréscimo no desempenho. Os demais participantes mantiveram ou aumentaram a porcentagem de respostas corretas. Já diante das sentenças testadas por DCRMTS, três participantes (UAN, JAM, LAE) tiveram um decréscimo nas respostas corretas. A Tabela 5 apresenta as sentenças (ensino e recombinadas) em que os participantes tiveram erros de construção durante o Teste de Sentenças (Etapa 1) e Teste de Manutenção diante de cada procedimento.

Entretanto, os dados da Figura 1 demonstram que a maior variação de acertos entre os dois procedimentos foi de 20%, para os seguintes participantes: ZIA (sentenças recombinadas no Teste de Manutenção), JAM (sentenças recombinadas no Teste de Sentenças: Etapa 1), PAL (sentenças recombinadas no Teste de Sentenças: Etapa 1) e MOR (sentenças recombinadas no Teste de Sentenças: Etapa 1 e Teste de Manutenção). Nas demais situações de testes para esses participantes e para os demais (UAN, LAE e ADR), essa variação de acertos foi de 17% ou 10% entres as sentenças com os dois procedimentos.
Com relação ao repertório de comportamento textual das sentenças, durante o Pré-teste 1 nenhum dos participantes emitiu respostas textuais correspondentes ao modelo impresso apresentado. Diante da solicitação de leitura da sentença em voz alta, apenas nomearam as letras. Já na Fase de Testes de Sentenças (Etapa 2: comportamento textual), com exceção dos participantes ZIA e PAL, as porcentagens de acertos dos demais variaram de 75% a 100%, incluindo as sentenças de ensino e recombinadas. Vale ressaltar que os erros ocorreram, de um modo geral, em apenas em uma ou duas palavras. Porém, como não havia uma correspondência ponto a ponto de todos os elementos, era considerada como erro completo a resposta textual de toda a sentença.
Nos resultados do repertório de leitura com compreensão das 32 sentenças, avaliado apenas na Fase de Testes de Sentenças (Etapa 2), quatro participantes (UAN, LAE, PAL, MOR) tiveram 100% de acertos diante de todas as relações testadas (sentença impressa - figura; vice-versa), nas sentenças de ensino e recombinadas. Os demais (ZIA, JAM e ADR) apresentaram erros em algumas relações, obtendo uma porcentagem de acertos que variou de 83% a 100%.
Discussão
O presente estudo buscou comparar a efetividade dos treinos com os procedimentos de SCRMTS e DCRMTS no estabelecimento dos repertórios de produção e leitura de sentenças, bem como a sua manutenção, em crianças com desenvolvimento típico.
Todos os participantes aprenderam a construir sentenças apenas sob controle do modelo auditivo, colocando cinco palavras na ordem exigida pela língua portuguesa. Os dois procedimentos demonstraram ser efetivos para estabelecer o repertório de construção de sentenças (ensino e recombinadas), corroborando com os resultados de Yamamoto e Miya (1999), e promovendo uma extensão das análises apresentadas por eles, já que no presente estudo a resposta de construção foi avaliada comparando procedimentos que envolviam a presença e ausência do modelo.
Além disso, considerando a quantidade de sessões necessárias para a conclusão da Fase de Ensino de sentenças com SCRMTS e DCRMTS, conforme descrito na seção Resultados, é possível considerar que os dois procedimentos podem ser utilizados de forma independente no ensino de sentenças, diferindo dos estudos de Stromer e Mackay (1992), os quais expunham os participantes primeiramente a um ensino por cópia com o SCRMTS, por considerarem um pré-requisito para a exposição ao treino com o DCRMTS.
Os resultados apresentados na Figura 1 mostraram que se comparando todas as condições entre dos dois procedimentos, não houve variação maior do que 20% de acertos entre eles para todos os participantes. É possível que a resposta de construção de sentenças, independente do procedimento utilizado, tenha sido facilitada pelo estabelecimento do controle discriminativo dos elementos que compunham as sentenças, ou seja, as palavras, antes do ensino das mesmas. Em estudos sobre a soletração de palavras, Hanna et al. (2004) e de Souza et al. (2004) afirmaram que no ensino com o DCRMTS quanto menor a linha de base dos participantes quanto ao controle de elementos textuais menores do que a palavra (ou seja, as letras e sílabas), maior a quantidade de treino necessária para ensinar o repertório exigido e menor os percentuais de acertos nos testes. Na presente pesquisa, todos os participantes, antes de serem expostos às sentenças, foram ensinados primeiramente a responder discriminativamente a todas às palavras do estudo. Após este treino inicial e o ensino das sentenças, os participantes com um responder textual de apenas 10% das palavras (ZIA, LAE, PAL) alcançaram resultados muito acima da sua linha de base nos testes (Etapas 1 e 2), com os dois procedimentos.
Os dados obtidos na primeira fase desta pesquisa indicam que apresentar um repertório de entrada de responder discriminativamente a todas as palavras que compunham as sentenças parece ser um pré-requisito importante pare o ensino da construção e emissão de comportamento textual de sentenças, independentemente do tipo de procedimento utilizado. Estudos futuros podem investigar o desempenho dos participantes no ensino das sentenças sem o estabelecimento prévio do responder sob o controle das unidades mínimas (letras, sílabas e palavras). Sem esse treino inicial, era provável que tal controle tivesse se desenvolvido durante o treino de sentenças, mas acredita-se que o tornaria mais extenso e possivelmente os participantes teriam sido expostos a mais erros.
Um aspecto identificado durante as tarefas de construção com os dois procedimentos, nas Fases de Ensino ou de Testes das Sentenças, é que os participantes emitiram respostas ecóicas/autoecóicas até a seleção da última palavra1. Skinner (1992) afirmou que diante de tarefas consideradas complexas, pode ser mais vantajoso para o indivíduo responder antes verbalmente, com o objetivo de executar a tarefa com maior precisão.
Nos testes de construção de sentenças com o DCRMTS, os participantes emitiam respostas ecóicas enquanto a sentença ditada era apresentada e continuavam após sua remoção, emitindo as respostas autoecóicas. Desse modo, era possível que durante a construção das sentenças, estivessem respondendo sob o controle conjunto2 dos estímulos verbais textuais (palavras impressas) apresentadas na tela do notebook e dos estímulos verbais auditivos produzidos por eles próprios (autoecóicos). Mesmo sem um planejamento específico para que isso ocorresse, parece que as respostas autoecóicas favoreceram o desempenho dos participantes na seleção de cada palavra até a construção final da sentença. Nos testes de construção das sentenças com o SCRMTS, mesmo com o modelo auditivo sendo apresentado durante toda a tentativa, os participantes permaneceram emitindo respostas ecóicas/autoecóicas até a seleção da última palavra. Assim como ocorreu com o procedimento de DCRMTS, com o SCRMTS é provável que, ao longo de uma mesma tentativa, os participantes estivessem respondendo sob o controle conjunto de diferentes estímulos discriminativos: estímulos verbais textuais (palavras impressas) e estímulos verbais auditivos (tanto o estímulo fornecido pelo áudio do notebook, quanto daquele produzido pelo participante).
Entretanto, mesmo visualizando que a diferença entre os procedimentos foi mínima, ao observar o quantitativo de sentenças construídas com erro na Tabela 5, é possível verificar que os participantes apresentaram mais acertos com o procedimento DCRMTS. Assim, foram realizadas algumas análises que subsidiassem esse dado.
Uma primeira análise é que os comportamentos precorrentes, como as respostas ecóica/autoecóica emitidas pelos participantes, parecem ter uma função facilitadora na escolha e sequenciação das palavras. Esse dado corrobora com os de Artzen (2006) que demonstrou a eficácia do procedimento de MTS com atraso para o estabelecimento de classes de equivalência de estímulos, inclusive, com diferentes atrasos, desde que comportamentos precorrentes fossem ensinados ou utilizados pelos participantes. Estes comportamentos teriam uma função mediadora entre o desaparecimento do modelo e a apresentação dos estímulos-comparação.
Uma segunda análise é que, de certa forma, houve uma alteração da tarefa entre as Fases de Ensino e de Testes das Sentenças durante o procedimento de SCRMTS. Neste procedimento, na Fase de Ensino, os participantes podiam responder tanto sob o controle dos modelos impresso e ditado, que ficavam presentes simultaneamente durante toda a tentativa. Já na fase de teste, o modelo impresso era removido, permanecendo apenas o ditado. Alguns percentuais de acertos mais elevados no DCRMTS na presente pesquisa indicam que num teste de ditado, o treino de cópia com atraso (DCRMTS) parece ser mais eficiente do que o treino de cópia simultânea (SCRMTS). Isso diferiu dos resultados obtidos por Hanna et al. (2002), pois nesse estudo os participantes após um treino de cópia com atraso não demonstraram um desempenho de soletração de palavras sob o controle apenas do modelo auditivo.
E por fim, uma terceira análise é o fato de que a quantidade de estímulos disponíveis simultaneamente no SCRMTS, aos quais podiam controlar a resposta de construção das sentenças, como descrito anteriormente, possa ter dificultado a resposta de selecionar as palavras durante a realização da tarefa. Mesmo considerando a validade das análises realizadas, recomenda-se que estudos posteriores investiguem sistematicamente o papel das respostas ecóica/autoecóica no estabelecimento do repertório de construção de sentenças a partir do tipo de procedimento utilizado.
Analisando o desempenho de responder textual, considerando que nenhum dos participantes apresentou o comportamento textual das sentenças antes de serem submetidos aos treinos, é possível sugerir que o procedimento CRMTS, conforme planejamento estruturado na presente pesquisa, favoreceu não apenas o desempenho de construção, mas também do responder textual das sentenças (Reis, Postalli, & de Souza, 2013).
Os escores nos teste de leitura com compreensão demonstram que a utilização de tarefas de construção de resposta foram suficientes adicionalmente para estabelecer o repertório de relacionar sentenças impressas sob controle de suas respectivas figuras (e vice-versa), o qual emergiu a partir das relações ensinadas, corroborando os estudos de Reis et al. (2013).
Com relação a Fase de Teste de Manutenção, todos os participantes conseguiram manter o repertório de construção, com escores acima de 80% nas sentenças de ensino e 70% nas sentenças recombinadas com os dois procedimentos. Comparando com o estudo de Stromer e Mackay (1992), no qual os participantes tiveram um declínio do repertório de soletração no follow up, na presente pesquisa, três participantes (PAL, ADR, MOR) ainda apresentaram um desempenho melhor se comparados com a etapa 1 da Fase de Teste de Sentenças. Duas variáveis podem ter contribuído para a manutenção do repertório: o tempo de apenas 20 dias entre as sessões experimentais e o teste de manutenção, e as sentenças serem formadas por palavras que faziam parte do ambiente natural dos participantes.
É notável também que os resultados alcançados nas sentenças recombinadas estiveram acima dos 70% de acertos das sentenças nos dois procedimentos durante os Testes de Sentenças (Etapa 1) e Manutenção. Esses resultados oferecem suporte a Mackay e Fields (2009) quando apontam que quando duas ou mais sentenças formadas por estímulos diferentes são ensinadas, é possível verificar que os estímulos que ocuparam a mesma posição nas diferentes sentenças se tornam intercambiáveis entre si (passam a funcionar como membros das classes equivalentes de primeiros, segundos, terceiros, etc.), e o indivíduo passa a produzir novas sentenças sintaticamente corretas.
Comparando os resultados da Fase de Testes de Manutenção com os Testes de Sentenças (Etapa 1), três participantes mantiveram melhores resultados com o DCRMTS (ZIA, JAM, MOR), enquanto que para outros três (LAE, PAL, ADR) o repertório aumentou diante do teste com o SCRMTS. Esses resultados sugerem que, ambos os procedimentos, usados nos formatos da presente pesquisa, podem ser úteis para o ensino e a manutenção do repertório sintático. Além disso, reafirmam que não há diferença de eficácia entre os procedimentos, embora nos Teste de Sentenças com SCRMTS, os participantes tenham apresentado mais erros do que nos com DCRMTS.
Uma limitação do estudo é que o Teste de Manutenção não reavaliou os repertórios de comportamento textual e leitura com compreensão. Como a configuração da tarefa era construir a sentença sob controle do estímulo ditado, não houve a possibilidade de exigir os repertórios de leitura. Entretanto, isso pode ser superado em pesquisas futuras com a apresentação das sentenças ditadas e impressas em sessões diferentes.
Os resultados evidenciam que o conjunto de procedimentos de ensino adotados na presente pesquisa foi eficaz para o ensino da produção e leitura de sentenças, bem como para a manutenção do primeiro repertório. Entretanto, sugere-se que novas pesquisas sejam realizadas com um delineamento de linha de base múltipla entre os participantes, de modo que após verificar o repertório de linha de base de P1, ele seria exposto ao treino das sentenças com os dois procedimentos. Quando P1 estivesse concluindo a Fase de Ensino das Sentenças por SCRMTS e DCRMTS, P2 que estaria no mesmo contexto de P1, teria seu repertório de linha de base avaliado e em seguida, exposto ao mesmo treino; e, assim sucessivamente até o último participante. Com esse delineamento é possível verificar com maior precisão se, de fato, as manipulações experimentais são responsáveis por mudanças nos desempenhos avaliados, já que mudanças semelhantes nos desempenhos dos vários participantes quando a variável independente é seguidamente introduzida refutaria ou, no mínimo, enfraqueceria a hipótese da influência de variáveis estranhas nessas mudanças (Sampaio, Azevedo, Cardoso, Lima, Pereira, & Andery, 2008).
Referências
Artzen, E. (2006). Delayed matching to sample: Probability of responding in accord with equivalence as a function of different delays. The Psychological Record, 56, 135-167. [ Links ]
Assis, G. J. A., & Santos, M. B. (2010). PROLER (software - sistema computadorizado para o ensino de comportamentos conceituais). Belém: Universidade Federal do Pará [ Links ].
Carr, J. E., Nicholson, A. C., & Higbee, T. S. (2000). Evaluation of a brief multiple-stimulus preference assessment in a naturalistic context. Journal of Applied Behavior Analysis, 33, 353-357. [ Links ]
de Souza, D. G., de Rose, J. C., & Domeniconi, C. (2009). Applying relational operants to reading and spelling. Em R. A. Rehfeldt & Y. Barnes-Holmes (Org.), Derived relational responding. Applications for learners with autism and other developmental disabilities (p. 173-207). Oakland, CA: New Harbinger Publications. [ Links ]
de Souza, D. G., Hanna, E. S., de Rose, J. C., Melo, R. M., & Quinteiro, R. (2004). O ensino de leitura e escrita a escolares de risco: ensino de cópia e desempenho em ditado. Em E. G. Mendes, M. A. Almeida & L. C. de A. Williams (Orgs.). Temas em educação especial: avanços recentes (pp. 263-270). São Carlos, SP: EduFSCAR. [ Links ]
Dube, W. V., McDonald, S. J., Mcllvane, W. J., & Mackay, H. A. (1991). Constructed-response matching to sample and spelling instruction. Journal of Applied Behavior Analysis, 24, 305-317. [ Links ]
Hanna, E. S., de Souza, D. G., de Rose, J. C., & Fonseca, M. (2004). Effects of delayed constructed-response identity matching on spelling of dictated words. Journal of Applied Behavior Analysis, 37, 223-227. [ Links ]
Hanna, E. S., de Souza, D. G., de Rose, J. C., Quinteiro, R. S., Campos, S. N. M., Alves, M., & Siqueira, A. (2002). Aprendizagem de construção de palavras e seus efeitos sobre o desempenho do ditado: importância do repertório de entrada. Arquivos Brasileiros de Psicologia, 3 (54), 255-273. [ Links ]
Lowenkron, B. (2006). An Introduction to Joint Control. The Analysis of Verbal Behavior, 22, 123 - 127. [ Links ]
Mackay, H. A., & Fields, L. (2009). Syntax, grammatical transformation, and productivity: A synthesis of stimulus sequences, equivalence classes and contextual control. Em R. A. Rehfeldt, & Y. Barnes-Holmes (Eds.), Derived relational responding: Applications for learners with autism and other developmental disabilities (pp. 209-235). Oakland, CA: New Harbinger Publications. [ Links ]
Reis, T. S., Postalli, L. M., & de Souza, D. G. (2013). Teaching spelling as a route for reading and writing. Psychology & Neuroscience, 6(3), 365-373. [ Links ]
Sampaio, A. A. S., Azevedo, F. H. B., Cardoso, L., R., D., Lima, C., Pereira, M. B., R., & Andery, M. A. P. A. (2008). Uma introdução aos delineamentos experimentais de sujeito único. Interação em Psicologia, 12(1), 151-164. [ Links ]
Skinner, B. F. (1992). Verbal behavior. Acton (MA): Copley Publishing Group (Trabalho originalmente publicado em 1957). [ Links ]
Stromer, R., & Mackay, H. A. (1992). Spelling and emergent picture-printed word relations established with delayed identity matching to complex samples. Journal of Applied Behavior Analysis, 25(4), 893-904. [ Links ]
Yamamoto, J., & Miya, T. (1999). Acquisition and transfer of sentence construction in autistic students: Analysis by computer–based teaching. Research in Developmental Retardation, 20(5), 355-377. [ Links ]
 Endereço para correspondência
Endereço para correspondência
Taynan Marques Bandeira, Grauben José Alves de Assis, Carlos Barbosa Alves de Souza
Unidade 203, rua 05, casa 02, Cidade Operária
CEP: 65058-161
São Luis - MA
Email: taynanmb@hotmail.com, ggrauben@gmail.com, carlosouz@gmail.com
Submetido em: 15/03/2016
Primeira decisão editorial: 20/05/2016
Aceito em: 01/06/2016
Editora Associada: Mariéle de Cássia Diniz Cortez
1 A observação dessas respostas verbais foi feita, a princípio, de forma assistemática durante as sessões de coleta. Esse dado foi confirmado posteriormente a partir da observação de todas as sessões filmadas com os participantes.
2 Lowenkron (2006) definiu controle conjunto como o efeito de dois estímulos discriminativos que agem em conjunto para exercer o controle de estímulo sobre uma topografia comum de resposta.