










Serviços Personalizados
Journal

artigo
 Português (pdf)
Português (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Curriculum ScienTI
Curriculum ScienTIIndicadores
Compartilhar

 Permalink
PermalinkArquivos Brasileiros de Psicologia
versão On-line ISSN 1809-5267
Arq. bras. psicol. vol.66 no.3 Rio de Janeiro 2014
ARTIGOS
Efeitos da similaridade ortográfica das pseudopalavras no acesso lexical
Pseudowords' orthographic similarity effects on lexical access
Efectos de la similitud ortográfica de las pseudopalabras en el acceso lexical
Francis Ricardo dos Reis JustiI; Cláudia Nascimento Guaraldo JustiI; Antonio RoazziII
IDocente. Programa de Pós-Graduação em Psicologia. Universidade Federal de Juiz de Fora (UFJF). Juiz de Fora. Estado de Minas Gerais. Brasil
IIDocente. Programa de Pós-Graduação em Psicologia Cognitiva. Universidade Federal de Pernambuco (UFPE). Recife. Estado de Pernambuco. Brasil
RESUMO
O presente estudo investigou o efeito que a similaridade ortográfica de um estímulo tem no tempo de reação e na precisão dos participantes em uma tarefa de decisão lexical. Para tanto, contou com pseudopalavras que correspondiam a uma manipulação fatorial de duas medidas de similaridade ortográfica: N - o número de vizinhos ortográficos formados pela substituição de uma letra do estímulo-alvo (p. ex.: 'navela' e 'novela') e TLN - o número de vizinhos ortográficos formados pela inversão na ordem de duas letras do estímulo-alvo (p. ex.: 'ânuglo' e 'ângulo'). Participaram da pesquisa 20 estudantes de um curso de pós-graduação em Psicologia, selecionados por amostragem não probabilística de conveniência. Utilizou-se um delineamento de medidas repetidas do tipo 2 x 2, correspondendo a uma manipulação fatorial de N e TLN. Observou-se uma interação entre TLN e N, na qual TLN apresentou um efeito inibidor apenas para as pseudopalavras que não tinham vizinhos ortográficos formados pela substituição de uma letra. Argumentou-se que o efeito de TLN traz desafios para os esquemas representacionais dos modelos atuais de leitura hábil.
Palavras-chave: Leitura; Vizinhos ortográficos; Vizinhos transpostos; Acesso lexical.
ABSTRACT
The present study investigated the effects that a stimulus’ orthographic similarity has in the participant’s reaction time and precision in a lexical decision task. The pseudowords in the lexical decision task corresponded to a factorial manipulation of two measures of orthographic similarity: N – the number of substitution neighbors (e.g., ‘hink’ and ‘hank’) and TLN – the number of transposed letter neighbors (e.g., ‘anlge’ and ‘angle’). A non-probabilistic sample of twenty graduated psychology students took part in this study. The experimental design consisted of a factorial manipulation of N and TLN in 2 x 2 within-subjects design. An interaction between N and TLN was observed, because TLN only inhibited the processing of pseudowords without substitution neighbors. It was argued that the TLN effect calls into question the representational schemas of nowadays skilled reading models.
Keywords: Reading; Orthographic neighborhood; Transposed letter neighbors; Lexical access.
RESUMEN
El presente estudio investigó el efecto que la similitud ortográfica de un estímulo tiene en el tiempo de reacción y en la precisión de los participantes en una tarea de decisión léxica. Las pseudopalabras en la tarea de decisión léxica corresponden a una manipulación factorial de dos medidas de similitud ortográfica: N – el número de vecinos ortográficos formados mediante la sustitución de una letra del estímulo (p. ej., “navela” y la “novela”) y TLN - el número de vecinos ortográficos formados por la inversión en el orden de dos letras del estímulo (p. ej., “ánuglo” y “ángulo”). Los participantes fueron 20 estudiantes de un curso de post-graduación de psicología, seleccionados a través de muestreo no probabilístico de conveniencia. Se utilizó un diseño de medidas repetidas tipo 2 x 2, correspondiente a una manipulación factorial de N y TLN. Se observó una interacción entre N y TLN, en la cual TLN inhibió el procesamiento solamente para las pseudopalabras sin vecinos de sustitución. Se argumentó que el efecto TLN trae desafíos para los sistemas de representación de los modelos actuales de la lectura hábil.
Palabras clave: Lectura, Vecindad ortográfica, Vecinos de transposición, Acceso lexical.
Um dos componentes importantes para uma leitura fluente e hábil é a capacidade de reconhecer uma palavra de forma rápida e automática. Para fazer isso, o nosso sistema cognitivo tem que mapear um determinado padrão ortográfico em um significado e/ou em um conjunto de sons. Uma questão que surge a esse respeito é: como, ao fazer esse mapeamento, o nosso sistema cognitivo distingue palavras que são ortograficamente similares umas às outras? Para investigar essa questão os pesquisadores têm desenvolvido medidas visando indexar o grau de similaridade ortográfica que uma palavra tem com outras (Andrews, 1996; Coltheart, Davelaar, Jonasson, & Besner, 1977). Por exemplo, quais palavras são mais similares em sua forma ortográfica: 'dado' e 'dedo', que diferem em apenas uma letra, ou 'brado' e 'bardo', que compartilham todas as letras, mas têm duas em ordem invertida? Ou ainda, colocando a questão de forma diferente, qual destas pseudopalavras1 é mais similar a uma palavra real: 'navela' ou 'noevla'?
A tentativa de responder a essas perguntas tem levado os pesquisadores a refletir sobre a maneira pela qual o nosso sistema cognitivo representa a estrutura ortográfica das palavras. Por exemplo, se isso ocorrer de forma estritamente posicional, a pseudopalavra 'navela' seria cognitivamente mais parecida com a palavra real 'novela', pois elas diferem ortograficamente em apenas uma posição. Por outro lado, se o nosso sistema cognitivo representar a estrutura ortográfica das palavras de forma mais relativa, a pseudopalavra 'noevla' seria cognitivamente mais parecida com a palavra 'novela', porque ambas compartilham todas as letras.
Como uma das características centrais da Psicologia Cognitiva é a investigação de como as representações mentais são combinadas e transformadas durante os processos cognitivos (Gardner, 1996), pode-se compreender por que há um interesse crescente pelas questões supracitadas nas pesquisas cognitivistas sobre a leitura, já que responder a essas questões pode nos ajudar a compreender como nosso sistema cognitivo representa a forma ortográfica das palavras (Acha & Perea, 2008; Andrews, 1989, 1992, 1996; Arduino & Burani, 2004; Carreiras, Perea, & Grainger, 1997; Huntsman & Lima, 2002; F. R. R. Justi & Pinheiro, 2006, 2008; Laxon, Gallagher, & Masterson, 2002; Perea, Carreiras, & Grainger, 2004; Perea & Lukpker, 2003a, 2003b; Perea, Rosa, & Gomez, 2003; Pollatsek, Perea, & Binder, 1999; Siakaluk, Sears, & Lupker, 2002; entre outros).
A medida mais utilizada na literatura para se investigar o efeito de similaridade ortográfica foi desenvolvida por Coltheart et al. (1977) e refere-se ao número de palavras que se pode gerar por meio da mudança de uma letra no estímulo-alvo. Por exemplo, de acordo com essa definição, a partir da palavra 'dado' podem ser geradas as palavras 'fado', 'gado', 'lado', 'nado', 'dedo', 'dano' e 'dada', enquanto a partir da palavra 'fulgor' não se gera nenhuma outra. Essa medida é conhecida como medida N (de Neighborhood, em inglês) e indexa o número de vizinhos ortográficos de um estímulo (isto é, o número de palavras que podem ser geradas a partir dele).
Como os pressupostos de modelos influentes de leitura hábil (como, por exemplo: o modelo de Ativação Interativa e Competição - AIC, de McClelland e Rumelhart (1981), e o modelo de Dupla Rota em Cascata - DRC, desenvolvido por Coltheart, Rastle, Perry, Langdon e Ziegler (2001)) se ajustam bem à medida de Coltheart et al. (1977), muitos pesquisadores a têm utilizado para avaliar o efeito do número de vizinhos ortográficos no reconhecimento visual de palavras. Por exemplo, Andrews (1989) manipulou o número de vizinhos ortográficos e a frequência de ocorrência das palavras-alvo em uma tarefa de decisão lexical. Nesse tipo de tarefa são apresentadas aos participantes ora palavras, ora pseudopalavras, e os mesmos devem decidir, apertando um botão, se o estímulo apresentado é uma palavra ou não.
Nos dois experimentos desenvolvidos por Andrews com essa tarefa, observou-se que as palavras de baixa frequência de ocorrência com muitos vizinhos ortográficos foram reconhecidas mais rapidamente do que as palavras de baixa frequência de ocorrência com poucos vizinhos ortográficos (ou seja, N teve um efeito facilitador no reconhecimento dessa classe de palavras); já o padrão inverso foi observado nas pseudopalavras do estudo. Esse mesmo efeito facilitador de N também foi observado quando essas mesmas palavras foram utilizadas em um experimento desenvolvido com a tarefa de leitura em voz alta (na qual os participantes devem ler em voz alta, o mais rápido possível, a palavra apresentada).
Em uma replicação posterior que controlou a frequência de ocorrência dos bigramas2 das palavras-alvo, os mesmos resultados foram observados (Andrews, 1992). Desde então, os efeitos facilitadores de N para palavras de baixa frequência de ocorrência têm sido observados por outros pesquisadores, tanto na tarefa de decisão lexical (Huntsman & Lima, 2002; Sears, Hino, & Lupker, 1995) quanto na tarefa de leitura em voz alta (Carreiras et al., 1997; Laxon et al., 2002). É interessante observar que na tarefa de leitura em voz alta também se tem observado um efeito facilitador de N na pronúncia das pseudopalavras (Arduino & Burani, 2004; Laxon, Masterson, Pool, & Keating, 1992; Laxon et al., 2002).
Uma das explicações delineadas por Andrews (1989, 1992) para o efeito facilitador de N se inspira no modelo de McClelland e Rumelhart (1981). Nessa explicação, Andrews propõe que as palavras com muitos vizinhos ortográficos são mais rapidamente reconhecidas porque as unidades lexicais pré-ativadas (a palavra-alvo e seus vizinhos ortográficos) enviam um feedback informacional que ajuda no reconhecimento das letras que as compõem. Como uma palavra com muitos vizinhos ortográficos, por definição, compartilha todas as letras com seus vizinhos, exceto uma, as letras dessa palavra recebem feedback de múltiplas fontes e são reconhecidas mais rapidamente, acelerando, assim, o processo de reconhecimento da palavra-alvo como um todo.
No entanto, um problema com essa proposta é que, apesar de alguns estudos demonstrarem um efeito facilitador de N para as pseudopalavras na tarefa de leitura em voz alta (Arduino & Burani, 2004; Laxon et al., 1992, 2002), isso não acontece na tarefa de decisão lexical. Como a explicação de Andrews se baseia em um mecanismo de feedback que melhora a percepção das letras, não há motivo para que isso também não ocorra com as pseudopalavras. Sendo assim, para que essa hipótese receba o suporte empírico adequado, é necessário explicar por que as pseudopalavras na tarefa de decisão lexical apresentam um efeito inibidor de N e, além disso, se possível, demonstrar em quais condições as pseudopalavras podem apresentar um efeito facilitador de N mesmo na tarefa de decisão lexical.
Uma das possíveis explicações para uma ausência do efeito facilitador de N para as pseudopalavras pode ser depreendida do trabalho de Grainger e Jacobs (1996). Para esses autores, a tarefa de decisão lexical é suscetível a uma estratégia de "adivinhação" (fast guess strategy) que faz com que o efeito de N se torne facilitador para as palavras e inibidor para as pseudopalavras. De acordo com Grainger e Jacobs, existe a possibilidade de os participantes responderem na tarefa de decisão lexical com base na familiaridade do estímulo (p. ex., o estímulo "parece ser" uma palavra), e não com base na sua identificação completa (p. ex., o estímulo é a palavra 'bola'). Se imaginarmos que os estímulos com muitos vizinhos ortográficos têm maior chance de ser ortograficamente similares a palavras (afinal, é isso que a medida N tenta indexar), pode-se esperar que as palavras que tiverem muitos vizinhos ortográficos serão classificadas mais rapidamente como 'palavras' na tarefa de decisão lexical, e as pseudopalavras que tiverem muitos vizinhos ortográficos, por sua vez, serão confundidas com palavras, gerando, provavelmente, tempos de reação mais lentos e maior porcentagem de erros. Daí um efeito facilitador de N para as palavras e, ao mesmo tempo, um efeito inibidor para as pseudopalavras.
O problema com essa proposta de Grainger e Jacobs é que, ao atribuir o efeito facilitador de N para as palavras a um processo meramente estratégico, relacionado à tarefa de decisão lexical, ela não explica por que se tem observado, de forma consistente, um efeito facilitador de N para as palavras e para as pseudopalavras na tarefa de leitura em voz alta (Arduino & Burani, 2004; Carreiras et al., 1997; Laxon et al., 1992, 2002).
Embora a proposta de Andrews (1989, 1992) e a de Grainger e Jacobs (1996) atribuam o efeito de N na tarefa de decisão lexical a processos diferentes (uma estratégia de adivinhação, no caso dos últimos, e um mecanismo de feedback das palavras para as letras, no caso da primeira), isso não significa que ambas sejam mutuamente excludentes. Existe a possibilidade de que o efeito de N na tarefa de decisão lexical possa se dever a ambos os processos. Uma forma de avaliar se esse é o caso é tentar evitar que os participantes utilizem a estratégia de "adivinhação" para responder às palavras e avaliar se nessa situação se pode observar um efeito facilitador de N para as pseudopalavras. Até o presente momento, não parece ter havido nenhum estudo que tenha investigado essa possibilidade, existindo, assim, uma lacuna relevante na literatura acerca do efeito de N para pseudopalavras na tarefa de decisão lexical.
Além das pesquisas sobre o efeito de N, outra medida de similaridade ortográfica que tem sido utilizada refere-se aos vizinhos ortográficos formados pela transposição de duas letras (Transposed Letter Neighbors - TLN), como é o caso das palavras 'anual' e 'anula'. Essa medida tem inspirado modelos recentes de reconhecimento visual de palavras, como, por exemplo, o modelo SERIOL (Whitney, 2001, 2004; Whitney & Lavidor, 2005; Whitney & Cornelissen, 2008). Nesse modelo, existiria um nível de processamento no nosso sistema cognitivo no qual as letras de um estímulo seriam representadas de forma atemporal e contextual. Esse nível de processamento tem sido chamado por Grainger e Whitney (2004) de "bigramas abertos", porque representaria a ordem das letras no estímulo de forma relativa. Por exemplo, no caso da palavra 'BOLA', os seguintes bigramas abertos seriam ativados: 'BO', 'BL', 'BA', 'OL', 'OA' e 'LA'.
De acordo com Whitney e Cornelissen (2008), a ativação dos bigramas abertos serviria de input para unidades no léxico que representariam a forma ortográfica das palavras, sendo que, no plano lexical, essas unidades se inibiriam mutuamente de forma proporcional ao seu grau de similaridade ortográfica (ou seja, as palavras mais similares ortograficamente se inibiriam mais fortemente). Como é o nível de ativação proveniente dos bigramas abertos que alimenta diretamente as unidades do léxico, os estímulos que têm um vizinho transposto teriam fortes competidores, porque esses compartilham muitos bigramas abertos com seus vizinhos. Por exemplo, as palavras 'bardo' e 'brado' compartilhariam 90% de seus bigramas abertos ('ba', 'br', 'bd', 'bo', 'ad', 'ao', 'rd', 'ro' e 'do'), não compartilhando apenas o bigrama 'ar', no caso de 'bardo', ou 'ra', no caso de 'brado'. Dessa forma, é esperado que estímulos que tenham vizinhos transpostos sejam mais difíceis de reconhecer do que os que não tenham.
Um dos primeiros estudos a demonstrar o efeito de TLN para a leitura de palavras e de pseudopalavras é o desenvolvido por Andrews (1996). Nesse estudo, a pesquisadora controlou o número de vizinhos ortográficos (N), a frequência de ocorrência dos bigramas e o número de letras das palavras e observou que na tarefa de decisão lexical as palavras e as pseudopalavras que tinham um vizinho ortográfico formado pela transposição de duas letras foram reconhecidas mais lentamente do que as que não tinham vizinhos transpostos, ou seja, a TLN teve um efeito inibidor tanto para as palavras quanto para as pseudopalavras.
Em uma série de estudos que utilizaram a técnica de priming na tarefa de decisão lexical, Perea e Lupker (2003a, 2003b) investigaram se o fato de uma palavra ou pseudopalavra ser precedida (primed) por um vizinho transposto afetaria o processamento desses estímulos. Em um desses estudos com a tarefa de decisão lexical, a palavra ou a pseudopalavra-alvo era precedida, muito brevemente (40 milissegundos), por uma pseudopalavra formada pela transposição de duas de suas letras (p. ex.: se o alvo era a palavra 'listou', essa era precedida pela pseudopalavra 'lisotu'; se o alvo era a pseudopalavra 'mafora', a mesma era precedida por 'mafroa'). Perea e Lupker (2003b) observaram que tanto as palavras quanto as pseudopalavras que eram precedidas por uma pseudopalavra que era sua vizinha transposta foram reconhecidas mais rapidamente do que as que não eram.
Em outro estudo, Perea e Lupker (2003a) observaram que o fato de uma palavra-alvo ser brevemente precedida (40 milissegundos) por uma pseudopalavra que é vizinha transposta de uma palavra semanticamente relacionada à palavra-alvo faz com que esta seja reconhecida mais rapidamente. Por exemplo, se a palavra-alvo era 'pesca' e a pseudopalavra que a precedia (o prime) era 'pexie', a primeira era reconhecida mais rapidamente do que quando ela era precedida pela pseudopalavra 'macra'. No entanto, é importante assinalar que em diversos experimentos desenvolvidos pelos autores o efeito de TLN era observado apenas quando o vizinho ortográfico era formado pela transposição de duas das letras mediais dos alvos.
Outro estudo interessante que avaliou o efeito de TLN na leitura foi o de Acha e Perea (2008). Nesse estudo, os pesquisadores mensuraram o movimento dos olhos durante a leitura de frases e observaram que os participantes faziam mais regressões oculares e passavam mais tempo fixando as palavras que tinham um vizinho transposto de maior frequência de ocorrência do que as palavras que não tinham um vizinho transposto. É interessante notar que essas duas medidas (o número de regressões feitas à palavra-alvo e o tempo total gasto fixando-a) são consideradas mais relacionadas a estágios finais do acesso lexical, quando o sistema cognitivo estaria selecionando a entrada lexical correspondente ao estímulo-alvo em relação a outras possíveis candidatas (Acha & Perea, 2008).
De forma geral, os estudos têm demonstrado que as palavras e pseudopalavras que têm um vizinho transposto podem sofrer influências em seu tempo de processamento devido à pré-ativação desses vizinhos (Acha & Perea, 2008; Andrews, 1996; Perea & Lupker, 2003a, 2003b). No caso dos estudos de priming, isso tem um efeito facilitador porque, ao ser ativado primeiro, o vizinho transposto também pré-ativa a palavra-alvo, facilitando assim seu reconhecimento posterior (p. ex.: Perea & Lupker, 2003a, 2003b). Já no caso dos estudos em que a palavra-alvo já tem um vizinho transposto e não é precedida por ele, é a própria palavra-alvo que pré-ativaria o vizinho transposto (devido à similaridade ortográfica de ambos), e esse, por estar ativo ao mesmo tempo em que a palavra-alvo, acabaria competindo com ela durante o processo de acesso lexical, retardando o seu reconhecimento (p. ex.: Acha & Perea, 2008; Andrews, 1996). No entanto, uma questão que ainda parece perdurar na literatura sobre o efeito de TLN é que há indícios de que o efeito do número de vizinhos transpostos varia de acordo com o número de letras das palavras, chegando, em alguns casos, a ser nulo em palavras com poucas letras e forte em palavras com muitas letras (Grainger, 2008). Esse fato levou Grainger (2008) a propor que "[...] o tamanho da palavra-alvo e/ou seu número de vizinhos ortográficos possa determinar de forma crítica a magnitude dos efeitos de priming de TLN" (p. 13).
A proposta de Grainger de que o número de vizinhos ortográficos da palavra-alvo possa moderar o efeito de TLN faz sentido, porque as palavras com poucas letras tendem a ter mais vizinhos ortográficos do que as palavras com muitas letras (Andrews, 1997; F. R. R. Justi & C. N. G. Justi, 2008). De fato, F. R. R. Justi e C. N. G. Justi (2008) relataram uma correlação significativa entre N e o número de letras das palavras no português brasileiro (r = -0,49), e Andrews (1997) relatou que a média do número de vizinhos ortográficos das palavras da língua inglesa diminui com o aumento no número de letras (médias de 7,2, 2,4 e 1,1 vizinhos ortográficos para as palavras de quatro, cinco e seis letras, respectivamente). Dessa forma, embora uma interação entre N e TLN seja bastante factível, nenhum estudo, até o momento, investigou diretamente essa questão. Em suma, existem pelo menos duas lacunas na literatura sobre o reconhecimento visual de palavras que merecem atenção: uma delas refere-se à inobservância de um efeito facilitador de N para as pseudopalavras na tarefa de decisão lexical, e a outra diz respeito a uma possível interação entre N e TLN que ainda não foi investigada.
Assim sendo, o presente estudo visa trazer uma contribuição para a literatura da área ao investigar experimentalmente essas duas questões. De forma mais específica, investigou o efeito de N e de TLN no tempo de reação e na porcentagem de erros dos participantes ao responderem a pseudopalavras em uma tarefa de decisão lexical. Nessa tarefa, as palavras não tinham vizinhos ortográficos, de forma a impedir que os participantes pudessem utilizar o número de vizinhos ortográficos das palavras como um índice de familiaridade dos estímulos (Grainger & Jacobs, 1996) e, assim, tentar "adivinhar" o status do estímulo-alvo sem processá-lo por completo. Além disso, enquanto o número de letras das pseudopalavras foi mantido constante, o número de vizinhos ortográficos foi manipulado, de forma a investigar se a magnitude do efeito de TLN pode ser modulada por N, conforme proposto por Grainger (2008).
Método
Participantes
Participaram do estudo 20 estudantes do curso de pós-graduação em Psicologia Cognitiva da Universidade Federal de Pernambuco, sendo cinco do sexo masculino e 15 do sexo feminino, com média de idade de 30,45 anos (DP = 8,71). Essa pesquisa foi aprovada pelo Comitê de Ética em Pesquisa da instituição (Reg. 187/07).
Material
Os estímulos experimentais foram compostos de 72 pseudopalavras de seis letras, que correspondiam a uma manipulação fatorial 2 x 2 de N e de TLN. Dessas 72 pseudopalavras, 18 não tinham vizinhos ortográficos (N = 0) nem vizinhos transpostos (TLN = 0); 18 não tinham vizinhos ortográficos (N = 0) e tinham um vizinho transposto (TLN = 1); 18 tinham, pelo menos, três vizinhos ortográficos (média de 3,94 vizinhos ortográficos) e não tinham vizinhos transpostos (TLN = 0); e 18 tinham, pelo menos, três vizinhos ortográficos (média de 4,55 vizinhos ortográficos) e tinham também um vizinho transposto (TLN = 1).
Para compor a tarefa de decisão lexical, foram incluídas 72 palavras de seis letras, sendo que 36 eram de baixa frequência de ocorrência (todas com uma vez por milhão de palavras) e 36 eram de alta frequência de ocorrência (média de 73,89 por milhão de palavras). Nenhuma dessas palavras tinha vizinhos ortográficos (N = 0) ou vizinhos transpostos (TLN = 0). As estatísticas de N e TLN para essas palavras e pseudopalavras e a estatística de frequência de ocorrência para as palavras foram obtidas no trabalho de F. R. R. Justi e C. N. G. Justi (2008). As palavras e pseudopalavras utilizadas nesse estudo encontram-se na Tabela 1.
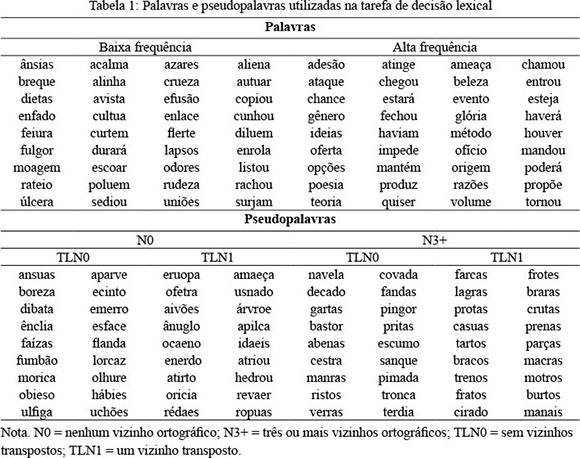
Para a apresentação dos estímulos, registro do tempo de reação e da porcentagem de erros dos participantes, utilizou-se o programa DMDX (K. Forster & J. Forster, 2003). Esse programa permite que os estímulos sejam apresentados em uma ordem aleatória diferente para cada participante e tem uma precisão de milissegundos no registro do tempo de reação. Para coletar as respostas dos participantes, um joystick ergonômico foi utilizado. Esse joystick devia ser segurado com ambas as mãos, e os participantes deviam utilizar o dedo indicador direito para responder às palavras (botão 6) e o dedo indicador esquerdo para responder às pseudopalavras (botão 5).
Delineamento
Trata-se de um experimento com duas variáveis independentes, que correspondem a uma manipulação fatorial 2 x 2 de N e de TLN (vide seção 'material'), tendo como variáveis dependentes o tempo de reação (mensurado desde o início da apresentação do estímulo até a resposta do participante) e a porcentagem de erros. O delineamento utilizado foi o de medidas repetidas (within-subjects), tendo sido controlado o número de letras das palavras e das pseudopalavras. Além disso, as palavras que compuseram a tarefa de decisão lexical não tinham vizinhos ortográficos ou vizinhos transpostos, como forma de evitar que os participantes utilizassem esses índices para "adivinhar" o status lexical dos estímulos. Isto é, utilizassem uma estratégia do tipo fast-guess (Grainger & Jacobs, 1996).
Procedimentos
Cada participante foi testado individualmente em uma sala cedida pela coordenação do programa de pós-graduação. Ao chegar à sala, o experimentador recebia o participante, dirimia eventuais dúvidas e o convidava a se acomodar em uma cadeira para que se pudesse dar início ao teste. O participante recebia então as seguintes instruções na tela do computador: "Nesse teste você verá esse sinal > < no centro da tela. Logo após, você verá uma palavra real ou uma palavra inventada. Pressione o botão 6 quando for uma palavra ou o botão 5 quando for uma palavra inventada. Tente fazer isso o mais rápido possível, mas evite errar". Após receber essas instruções, o participante iniciava uma sessão de treinamento, que era repetida até que atingisse uma porcentagem de erros inferior a 30%. A sessão de treinamento tinha a finalidade de familiarizar os participantes com o joystick e com os botões que deveriam pressionar para responder às palavras e às pseudopalavras. Após a sessão de treinamento, o participante iniciava a sessão experimental. Nas duas sessões os estímulos foram apresentados da seguinte forma: inicialmente aparecia uma marca de fixação "> <", com duração de 500 milissegundos; imediatamente após a marca de fixação, o estímulo-alvo era apresentado por 1.500 milissegundos, desaparecendo após esse período. O participante tinha, no máximo, dois segundos (contados a partir do início da apresentação do estímulo-alvo) para responder (pressionando um botão) se o estímulo era uma palavra ou uma pseudopalavra.
Resultados
Um dos participantes apresentou uma porcentagem de erros na sessão experimental acima de 30%, e, como as chances de acertar ao mero acaso na tarefa de decisão lexical é de 50%, os dados desse participante (que apresentou 40,25% de erros) não foram incluídos nas análises do estudo, porque, provavelmente, ele optou por responder ao acaso. Com a exclusão desse outlier, a porcentagem de erros média dos participantes do estudo foi de 10,91% (com um desvio-padrão de 7,09). Conforme recomendações de Perea (1999), os escores de tempo de reação de cada participante que se desviaram de suas médias por mais de dois desvios-padrão foram limitados a esse valor, sendo que tal procedimento alterou 4,51% dos escores. Os participantes apresentaram um tempo de reação médio para responder às palavras de 836 milissegundos (DP = 172) e para responder às pseudopalavras de 991 milissegundos (DP = 195). A Tabela 2 apresenta a média de tempo de reação e porcentagem de erros dos participantes para as pseudopalavras que corresponderam à manipulação experimental de N e TLN.
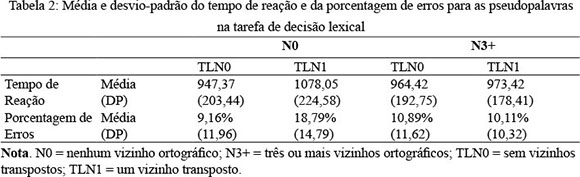
Seguindo as recomendações de Clark (1973) para a análise de dados em estudos com estímulos linguísticos, a variação referente ao efeito dos itens foi incluída no termo de erro dos testes e a estatística min F' foi calculada. Considerando o efeito de N e TLN no tempo de reação das pseudopalavras, pode-se observar que o efeito principal de N teve uma direção facilitadora, porém esse não chegou a ser significante: min F'(1,81) = 2,67, p = 0,11. Já o efeito principal de TLN foi inibidor e significante: min F'(1,83) = 9,10, p < 0,01. No entanto, essas informações devem ser consideradas à luz de uma interação significante entre N e TLN: min F'(1,85) = 6,46, p < 0,05. Testes post-hoc planejados indicaram que essa interação ocorreu porque o efeito de TLN só foi significante quando as pseudopalavras não tinham vizinhos ortográficos [min F'(1,51) = 19,51, p < 0,001], e o efeito de N foi facilitador quando as pseudopalavras tinham um vizinho transposto [min F'(1,49) = 7,40, p < 0,01]. Para o efeito de N quando as pseudopalavras não tinham vizinhos transpostos e para o efeito de TLN quando as pseudopalavras tinham três ou mais vizinhos ortográficos, todos os p foram maiores do que 0,5.
Para o efeito de N e de TLN na porcentagem de erros das pseudopalavras, o mesmo padrão foi observado, exceto pelo efeito principal de TLN, que não chegou a ser estatisticamente significante. A interação entre N e TLN foi significante: min F'(1,84) = 3,84, p = 0,05. Análises post-hoc indicaram que o efeito inibidor de TLN se restringiu às condições em que as pseudopalavras não tinham vizinhos ortográficos [min F'(1,42) = 7,35, p < 0,01] e que N teve um efeito facilitador quando as pseudopalavras tinham um vizinho transposto [min F'(1,44) = 4,38, p < 0,05]. Para o efeito de N, quando as pseudopalavras não tinham vizinhos transpostos, e para o efeito de TLN, quando as pseudopalavras tinham três ou mais vizinhos ortográficos, todos os p foram maiores do que 0,5.
É importante considerar que um dos revisores anônimos deste artigo indicou corretamente que as pseudopalavras 'escumo', 'tronca' e 'manais', utilizadas no estudo (vide Tabela 1), são, na verdade, palavras reais. Nesse caso, é preciso ressaltar que nenhuma dessas palavras consta no trabalho de F. R. R. Justi & C. N. G. Justi (2008), o que indica que a sua frequência de ocorrência é menor do que uma vez por cada milhão. Assim sendo, é provável que essas palavras não sejam conhecidas pelos participantes e que possam ser consideradas como pseudopalavras. De qualquer forma, elas foram excluídas e os dados das análises de itens foram reanalisados. Mesmo assim, os resultados obtidos apresentaram o mesmo padrão, isto é, nenhum resultado não significativo passou a ser significativo ou vice-versa. Isso se manteve para todas as análises realizadas acerca dos efeitos de N e TLN, seja no tempo de reação, seja na porcentagem de erros.
Por fim, considerando as palavras, pode-se observar o tradicional efeito de frequência, sendo as palavras de maior frequência de ocorrência reconhecidas mais rapidamente do que as de menor frequência de ocorrência [757 e 916 milissegundos, respectivamente - min F'(1,66) = 43,86, p < 0,001]. Esse mesmo efeito foi observado na precisão, sendo as palavras mais frequentes reconhecidas com maior precisão do que as menos frequentes [98,32% e 82,53%, respectivamente - min F'(1,48) = 19,15, p < 0,001].
Discussão
É importante considerar que o efeito inibidor de TLN observado no tempo de reação no presente estudo é diretamente comparável com o efeito inibidor de TLN observado para as pseudopalavras na tarefa de decisão lexical no estudo de Andrews (1996). Além disso, embora tenham usado tarefa e medidas diferentes, os achados de Acha e Perea (2008) de que os participantes passam mais tempo fixando as palavras que têm um vizinho transposto de maior frequência de ocorrência do que as palavras que não têm um vizinho transposto também são compatíveis com os achados do presente estudo, porque o efeito observado de TLN também foi inibidor. Assim sendo, o efeito inibidor de TLN parece ocorrer em falantes da língua portuguesa (presente estudo), da língua inglesa (Andrews, 1996) e do espanhol (Acha & Perea, 2008). Infelizmente, nem Andrews nem Acha e Perea manipularam o número de vizinhos ortográficos, então não temos como avaliar se a interação entre N e TLN observada no presente estudo também ocorreria nos estudos desses outros pesquisadores.
Aparentemente, o presente estudo foi o primeiro a investigar diretamente a possibilidade de que os efeitos de TLN e de N interajam. Nesse sentido, tanto nas análises de tempo de reação quanto nas da porcentagem de erros foi possível observar uma interação estatisticamente significante entre N e TLN. É interessante observar que essa interação pode explicar a observação de Grainger (2008) de que o efeito de TLN parece variar de acordo com o número de letras e/ou de vizinhos ortográficos dos estímulos, sendo mais fraco ou nulo para estímulos de poucas letras e mais forte para estímulos com muitas letras.
Como observado na revisão da literatura, há uma correlação negativa entre o número de vizinhos ortográficos e o de letras (F. R. R. Justi & C. N. G. Justi, 2008). Assim sendo, poder-se-ia pensar que, quando os estímulos têm muitos vizinhos ortográficos, o efeito de TLN tende a ser nulo ou fraco e que, quando os estímulos têm poucos vizinhos ortográficos, o efeito de TLN tende a ser mais forte. É interessante notar que esse foi exatamente o padrão observado no presente estudo: o efeito de TLN foi estatisticamente significante quando as pseudopalavras não tinham vizinhos ortográficos e foi nulo quando essas tinham três ou mais vizinhos ortográficos. Como no presente estudo foi controlado o número de letras das pseudopalavras (todas tinham seis letras), essa variação no efeito de TLN pode ser mais seguramente atribuída à variação no número de vizinhos ortográficos das pseudopalavras.
Uma vez demonstrada a interação entre N e TLN, é necessário também lançar mão dos modelos cognitivos de leitura hábil para explicá-la. O efeito inibidor de TLN, isto é, o fato de as palavras e pseudopalavras que têm vizinhos transpostos serem reconhecidas mais lentamente ou de forma mais imprecisa do que as palavras e pseudopalavras que não têm esses vizinhos, tem sido acomodado dentro do arcabouço conceitual de modelos recentes, como o SERIOL (Whitney, 2001, 2004; Whitney & Cornelissen, 2008; Whitney & Lavidor, 2005). Nesse caso, é importante lembrar que o modelo SERIOL representa a ordem das letras de forma relativa por meio de bigramas abertos (Grainger & Whitney, 2004) e que a ativação proveniente desses bigramas serviria de input para representação da forma ortográfica das palavras no léxico.
Assim sendo, uma palavra que tenha um vizinho ortográfico formado pela transposição de duas de suas letras teria um competidor fortemente pré-ativado no léxico e, como as palavras no léxico se inibem mutuamente, consequentemente seria reconhecida mais lentamente. É exatamente esse tipo de processo que explicaria o efeito inibidor de TLN. No entanto, para explicar a interação entre TLN e N, é necessário considerar que o modelo SERIOL (Whitney, 2004; Whitney & Lavidor, 2005), tal qual os modelos AIC (McClelland & Rumelhart, 1981) e DRC (Coltheart et al., 2001) também propõe um mecanismo de feedback entre as palavras e as letras que as compõem. Considerando-se esse mecanismo de feedback e também a inibição que ocorre entre as palavras no léxico, pode-se tentar cunhar uma possível explicação para a interação entre N e TLN.
Uma possível explicação para essa interação passaria pela conjectura de que o efeito de TLN é reduzido quando as palavras têm muitos vizinhos ortográficos, porque, nessa condição, é possível que o grande número de unidades ortograficamente similares pré-ativadas no léxico comece a se inibir mutuamente. Assim sendo, mesmo que um vizinho ortográfico sozinho não consiga inibir fortemente a pseudopalavra-alvo ou seu vizinho transposto, a presença de muitos vizinhos pode ser suficiente para reduzir significativamente a ativação de ambos. Esse processo poderia diminuir um pouco a influência do vizinho transposto, reduzindo assim o efeito inibidor de TLN. Além disso, o feedback existente entre as palavras e as letras que as compõem poderia facilitar a percepção das letras da pseudopalavra-alvo, fazendo com que a última receba ativação um pouco mais rápido do que sua vizinha transposta, anulando um possível efeito inibidor remanescente de TLN. Daí o efeito de TLN ter sido observado, neste estudo, apenas nas pseudopalavras que tinham poucos vizinhos ortográficos.
Infelizmente, como os modelos AIC (McClelland & Rumelhart, 1981) e DRC (Coltheart et al., 2001) não fazem predições para o efeito de TLN, os mesmos não têm como explicar a interação observada no presente estudo entre N e TLN. No entanto, esses modelos, juntamente com o SERIOL (Whitney, 2004; Whitney & Lavidor, 2005), fazem predições para um possível efeito facilitador de N, devido ao feedback que postulam existir entre as palavras e as letras que as compõem. Assim sendo, o presente estudo investigou também a hipótese de que o número de vizinhos ortográficos pudesse ter um efeito facilitador no reconhecimento das pseudopalavras, tentando evitar que os participantes mascarassem esse efeito ao utilizar uma estratégia de "adivinhação" baseada na familiaridade dos estímulos (Grainger & Jacobs, 1996).
Nesse caso, pode-se dizer que essa hipótese recebeu apenas uma corroboração parcial dos resultados deste estudo, pois o efeito geral de N teve uma direção facilitadora, mas não chegou a ser estatisticamente significante, limitando-se apenas a um efeito facilitador estatisticamente significante quando as pseudopalavras tinham um vizinho transposto. Porém, nesse último caso, não é possível atribuir esse efeito de forma inequívoca a N, já que esse mesmo resultado também pode ser interpretado em função de TLN, argumentando-se que, na prática, o que ocorreu é que TLN, por interagir com N, inibiu mais as pseudopalavras sem vizinhos ortográficos do que aquelas com muitos vizinhos ortográficos. Destarte, a hipótese de Andrews (1989, 1992) de que o efeito facilitador de N se deve primordialmente ao feedback existente entre as palavras e as letras ainda carece de suporte, pelo menos no que diz respeito à tarefa de decisão lexical.
Uma possível explicação para o efeito facilitador de N não ter sido significante no presente estudo seria argumentar em favor de uma possível falta de poder estatístico, já que o presente estudo, apesar de utilizar um delineamento de medidas repetidas, teve apenas 20 participantes. No entanto, na prática, esse argumento só reforça a ideia de que o efeito de N não é tão forte assim. Afinal, com esse mesmo número de participantes foi possível observar de forma estatisticamente significante os efeitos de TLN e sua interação com N e o clássico efeito de frequência, no caso das palavras. Então, é mais provável que o efeito de N na tarefa de decisão lexical seja primordialmente estratégico, conforme proposto por Grainger e Jacobs (1996).
É interessante notar que F. R. R. Justi e Pinheiro (2006) testaram essa hipótese de Grainger e Jacobs (1996) em falantes do português brasileiro e encontraram resultados favoráveis a ela. Porém, a questão que ainda permanece nesse caso é: por que, então, o efeito facilitador de N apareceria (ou seria maior) nas palavras e pseudopalavras na tarefa de leitura em voz alta? Nesse caso, Reynolds e Besner (2002), em uma simulação computacional com o modelo DRC (Coltheart et al., 2001), dão indícios do porquê isso poderia acontecer. De acordo com os pesquisadores, na tarefa de leitura em voz alta, o efeito de N seria facilitador no modelo DRC (Coltheart et al., 2001), porque os estímulos com muitos vizinhos ortográficos não se beneficiariam somente de maior ativação das letras compartilhadas, mas também da pré-ativação dos fonemas que compartilhassem com seus vizinhos ortográficos. Daí o efeito facilitador de N ser mais forte na tarefa de leitura em voz alta, pois nessa tarefa os vizinhos ortográficos ajudariam em dois momentos no processamento do estímulo, enquanto na tarefa de decisão lexical ajudariam em apenas um. O quanto essa explicação de Reynolds e Besner (2002) pode ser estendida aos outros modelos discutidos aqui é uma questão para estudos futuros, já que esses modelos ainda não têm implementado um sistema fonêmico que lhes permita simular os resultados da tarefa de leitura em voz alta.
Os modelos de processamento paralelo distribuído (Plaut, McClelland, Seidenberg e Patterson, 1996; Seidenberg & McClelland, 1989) não foram discutidos neste trabalho por dois motivos: 1) eles não trazem predição para a hipótese testada de que o efeito facilitador de N se deva a um mecanismo de feedback entre as palavras e suas letras componentes, pois não têm esses níveis representacionais implementados; e 2) eles tampouco trazem quaisquer predições quanto ao efeito de TLN.
Conclusões
O presente estudo demonstrou experimentalmente que existe uma interação entre TLN e o número de vizinhos ortográficos e que o fato de uma pseudopalavra ter uma palavra real que lhe é vizinha pela transposição de duas letras torna essa pseudopalavra mais difícil de rejeitar em uma tarefa de decisão lexical. O efeito inibidor de TLN é relevante do ponto de vista teórico, porque é um indício de que nossa mente pode representar a ordem das letras nas palavras de forma relativa, e isso tem repercussões na forma como os estímulos linguísticos são processados ortograficamente e também na sua dinâmica de ativação lexical durante a leitura. Além disso, já que a forma como as representações mentais estão estruturadas é uma questão central na Psicologia Cognitiva, o efeito de TLN constitui um desafio importante para os esquemas representacionais de modelos cognitivos de leitura hábil, como os modelos IAC (McClelland & Rumellart, 1981), DRC (Coltheart et al., 2001) e os de Processamento Paralelo Distribuído (Seidenberg & McClelland, 1989; Plaut et al., 1996), uma vez que os mesmos não representam a ordem das letras de forma relativa.
Por fim, é importante ressaltar que, até onde se sabe, este é o primeiro estudo a investigar diretamente a interação entre N e TLN, sendo também o primeiro a demonstrar o efeito de TLN em pseudopalavras da língua portuguesa. Assim sendo, seria interessante que estudos futuros tentassem replicar esses achados e, especificamente no caso do português brasileiro, que o efeito de TLN fosse avaliado também em tarefas diferentes da tarefa de decisão lexical.
Referências
Acha, J., & Perea, M. (2008). The effect of neighborhood frequency in reading: evidence with transposed-letter neighbors. Cognition, 108, 290-300. [ Links ]
Andrews, S. (1989). Frequency and neighborhood effects on lexical access: activation or search? Journal of Experimental Psychology: Learning, Memory & Cognition, 15, 802-814. [ Links ]
Andrews, S. (1992). Frequency and neighborhood effects on lexical access: lexical similarity or orthographic redundancy? Journal of Experimental Psychology: Learning, Memory, & Cognition, 18, 234-254. [ Links ]
Andrews, S. (1996). Lexical retrieval and selection processes: effects of transposed-letter confusability. Journal of Memory and Language, 35, 775-800. [ Links ]
Andrews, S. (1997). The effect of orthographic similarity on lexical retrieval: resolving neighborhood conflicts. Psychonomic Bulletin & Review, 4, 439-461. [ Links ]
Arduino, L., & Burani, C. (2004). Neighborhood effects on nonword visual processing in a language with shallow orthography. Journal of Psycholinguistic Research, 33, 75-95. [ Links ]
Carreiras, M., Perea, M., & Grainger, J. (1997). Effects of orthographic neighborhood in visual word recognition: cross-task comparisons. Journal of Experimental Psychology: Learning, Memory, & Cognition, 23, 857-871. [ Links ]
Clark, H. (1973). The language-as-fixed-effect fallacy: a critique of language statistics in psychological research. Journal of Verbal Learning and Verbal Behavior, 12, 335-359. [ Links ]
Coltheart, M., Davelaar, E., Jonasson, J., & Besner, D. (1977). Access to the internal lexicon. In S. Dornic (Org.), Attention and performance VI (pp. 535-555). Hillsdale: Erlbaum. [ Links ]
Coltheart, M., Rastle, K., Perry, C., Langdon, R., & Ziegler, J. (2001). DRC: A dual route cascaded model of visual word recognition and reading aloud. Psychological Review, 108, 204-256. [ Links ]
Forster, K., & Forster, J. (2003). DMDX: A windows display program with millisecond accuracy. Behavior Research Methods, Instruments and Computers, 35, 116-124. [ Links ]
Gardner, H. (1996). A nova ciência da mente: uma história da revolução cognitiva. São Paulo: EDUSP. [ Links ]
Grainger, J. (2008). Cracking the orthographic code: an introduction. Language and Cognitive Processes, 23, 1-35. [ Links ]
Grainger, J., & Jacobs, A. (1996). Orthographic processing in visual word recognition: a multiple read-out model. Psychological Review, 103, 518-565. [ Links ]
Grainger, J., & Whitney, C. (2004). Does the huamn mnid raed wrods as a wlohe? Trends in Cognitive Sciences, 8, 58-59. [ Links ]
Huntsman, L., & Lima, S. (2002). Orthographic neighbors and visual word recognition. Journal of Psycholinguistic Research, 31, 289-306. [ Links ]
Justi, F. R. R., & Justi, C. N. G. (2008). As estatísticas de vizinhança ortográfica das palavras do português e do inglês são diferentes? Psicologia em Pesquisa (UFJF), 2, 61-73. [ Links ]
Justi, F. R. R., & Justi, C. N. G. (2009). Contagem da frequência dos bigramas em palavras de quatro e seis letras do português brasileiro. Psicologia em Pesquisa (UFJF), 3, 81-95. [ Links ]
Justi, F. R. R., & Pinheiro, A. M. V. (2006). O efeito de vizinhança ortográfica no português do Brasil: acesso lexical ou processamento estratégico. Interamerican Journal of Psychology, 40, 275-288. [ Links ]
Justi, F. R. R., & Pinheiro, A. M. V. (2008). O efeito de vizinhança ortográfica em crianças brasileiras: estudo com a tarefa de decisão lexical. Interamerican Journal of Psychology, 42, 559-569. [ Links ]
Laxon, V., Gallagher, A., & Masterson, J. (2002). The effects of familiarity, orthographic neighbourhood density, letter-length and graphemic complexity on children's reading accuracy. British Journal of Psychology, 93, 269-287. [ Links ]
Laxon, V., Masterson, J., Pool, M., & Keating, C. (1992). Nonword naming: Further exploration of the pseudohomophone effect in terms of orthographic neighborhood size, graphemic changes, spelling - sound consistency, and reader accuracy. Journal of Experimental Psychology: Learning, Memory, & Cognition, 18, 730-748. [ Links ]
McClleland, J., & Rumelhart, D. (1981). An interactive activation model of context effects in letter perception: pt. 1, an account of basic findings. Psychological Review, 88, 375-407. [ Links ]
Perea, M. (1999). Tiempos de reacción y psicología cognitiva: dos procedimientos para evitar el sesgo debido al tamaño muestral. Psicológica, 20, 13-21. [ Links ]
Perea, M., Carreiras, M., & Grainger, J. (2004). Blocking by word frequency and neighborhood density in visual word recognition: a task-specific response criteria account. Memory & Cognition, 32, 1090-1102. [ Links ]
Perea, M., & Lupker, S. J. (2003a). Does judge activate court? Transposed-letter similarity effects in masked associative priming. Memory & Cognition, 31, 829-841. [ Links ]
Perea, M., & Lupker, S. J. (2003b). Transposed-letter confusability effects in masked form priming. In S. Kinoshita & S. J. Lupker (Orgs.), Masked priming: State of the art (pp. 97-120). Hove, UK: Psychology Press. [ Links ]_
Perea, M., Rosa, E., & Gómez, C. (2003). Influence of neighborhood size and exposure duration on visual-word recognition: evidence with the yes / no and the go / no-go lexical decision tasks. Perception & Psychophysics, 65, 273-286. [ Links ]
Plaut, D., McClelland, J., Seidenberg, M., & Patterson, K. (1996). Understanding normal and impaired word reading: computational principles in quasi-regular domains. Psychological Review, 103, 56-115. [ Links ]
Pollatsek, A., Perea, M., & Binder, K. (1999). The effects of neighborhood size in reading and lexical decision. Journal of Experimental Psychology: Human Perception & Performance, 25, 1142-1158. [ Links ]
Reynolds, M., & Besner, D. (2002). Neighbourhood density effects in reading aloud: new insights from simulations with the DRC Model. Canadian Journal of Experimental Psychology, 56, 310-318. [ Links ]
Sears, C., Hino, Y., & Lupker, S. (1995). Neighborhood size and neighbourhood frequency effects in word recognition. Journal of Experimental Psychology: Human Perception & Performance, 16, 65-76. [ Links ]
Seidenberg, M., & McClelland, J. (1989). A distributed developmental model of word recognition and naming. Psychological Review, 96, 523-568. [ Links ]
Siakaluk, P., Sears, C., & Lupker, S. (2002). Orthographic neighborhood effects in lexical decision: the effects of nonword orthographic neighborhood size. Journal of Experimental Psychology: Human Perception and Performance, 28, 661-681. [ Links ]
Whitney, C. (2001). How the brain encodes the order of letters in a printed word: the SERIOL model and selective literature review. Psychonomic Bulletin & Review, 8, 221-243. [ Links ]
Whitney, C. (2004). Hemisphere-specific effects in word recognition do not require hemisphere-specific modes of access. Brain and Language, 88, 279-293. [ Links ]
Whitney, C., & Cornelissen, P. (2008). SERIOL reading. Language and Cognitive Processes, 23, 143-164. [ Links ]
Whitney, C., & Lavidor, M. (2005). Facilitative orthographic neighborhood effects: the SERIOL model account. Cognitive Psychology, 51, 179-213. [ Links ]
 Endereço para correspondência:
Endereço para correspondência:
Francis Ricardo dos Reis Justi
francisjusti@gmail.com
Cláudia Nascimento Guaraldo Justi
claudia.ngjusti@gmail.com
Antonio Roazzi
roazzi@gmail.com
Submetido em: 03/03/2014
Revisto em: 05/12/2014
Aceito em: 13/12/2014
1 Conjunto de letras que respeita as regras fonotáticas da língua-alvo, mas que não têm um significado.
2 Pares ordenados de letras que coocorrem em determinadas posições nas palavras de uma língua (F. R. R. Justi & C. N. G. Justi, 2009).

